

高通CEO:生成式AI正在“非
原文来源:新智元

图片来源:由无界 AI生成
指令调优或许是让大模型性能提升最有潜力的方法。
用高质量数据集进行指令调优,能让大模型性能快速提升。

对此,微软研究团队训练了一个CodeOcean数据集,包含了2万个指令实例的数据集,以及4个通用代码相关任务。
与此同时,研究人员微调了一个代码大模型WaveCoder。

论文地址:https://arxiv.org/abs/2312.14187
实验结果表明,Wavecoder优于其他开源模型,在以前的代码生成任务中表现出色。
指令调优,释放「代码大模型」潜力
过去的一年,GPT-4、Gemini、Llama等大模型在一系列复杂NLP任务中取得了前所未有的性能。
这些LLM利用自监督预训练的过程,以及随后的微调,展示了强大的零/少样本的能力,能够有效遵循人类指示完成不同的任务。
然而,若想训练微调这样一个大模型,其成本非常巨大。
因此,一些相对较小的LLM,特别是代码大语言模型(Code LLM),因其在广泛的代码相关任务上的卓越的性能,而引起了许多研究者的关注。
鉴于LLM可以通过预训练获得丰富的专业知识,因此在代码语料库上进行高效的预训练,对代码大模型至关重要。
包括Codex、CodeGen、StarCoder和CodeLLaMa在内的多项研究已经成功证明,预训练过程可以显著提高大模型处理代码相关问题的能力。
此外,指令调优的多项研究(FLAN、ExT5)表明,指令调优后的模型在各种任务中的表现符合人类预期。
这些研究将数千个任务纳入训练管道,以提高预训练模型对下游任务的泛化能力。
比如,InstructGPT通过整合人类标注者编写的高质量指令数据,有效地调整了用户输入,推进指令调优的进一步探索。
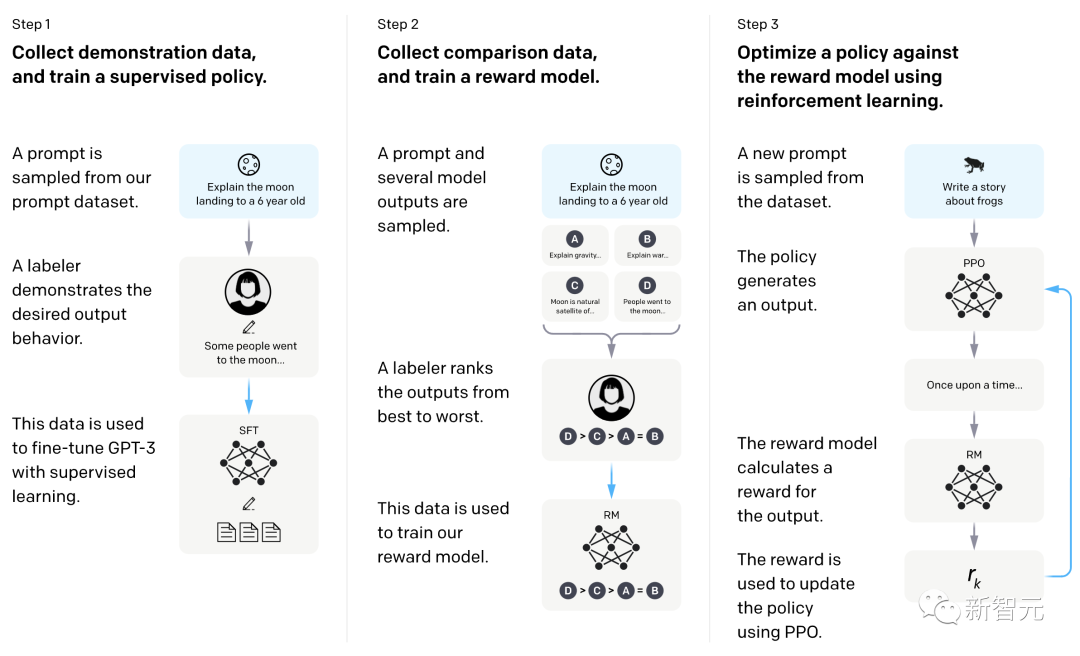
斯坦福的Alpaca利用ChatGPT通过Self-Instruct的方法,自己生成指令数据,进而用于指令调优的过程。
WizardLM和WizardCoder则应用了evol-instruct的方法,进一步提高了预训练模型的有效性。
这些近来的研究都体现了,指令调优在提高大模型性能方面,展现出强大的潜力。
基于这些工作,研究人员的直觉是,指令调优可以激活大模型的潜力,然后将预训练模型微调到出色的智能水平。
对此,他们总结了指令调优的主要功能:
- 泛化
指令调优最初是为了增强大模型的跨任务泛化能力而提出的,当使用不同的NLP任务指令进行微调时,指令调优可提高模型在大量未见任务中的性能。
- 对齐
预训练模型从大量token和句子层面的自监督任务中学习,已经具备了理解文本输入的能力。指令调优为这些预训练模型提供了指令级任务,让它们能够从指令中提取原始文本语义之外的更多信息。这些额外的信息是用户的意图,能增强它们与人类用户的交互能力,从而有助于对齐。
为了通过指令调优提高代码大模型的性能,目前已有许多设计好的生成指令数据的方法,主要集中在两个方面。
例如,self-instructe、vol-instruct利用teacher LLM的零/少样本的能力来生成指令数据,这为教学数据的生成提供了一种神奇的方法。
然而,这些生成方法过于依赖于teacher LLM的性能,有时会产生大量的重复数据,便会降低微调的效率。
CodeOcean:四项任务代码相关指令数据
为了解决这些问题,如图2所示,研究人员提出了一种可以充分利用源代码,并明确控制生成数据质量的方法。
由于指令调优是为了使预训练模型与指令遵循训练集保持一致,研究人员提出了一个用于指令数据生成的LLM Generator-Disciminator(大模型生成器-判别器)框架。
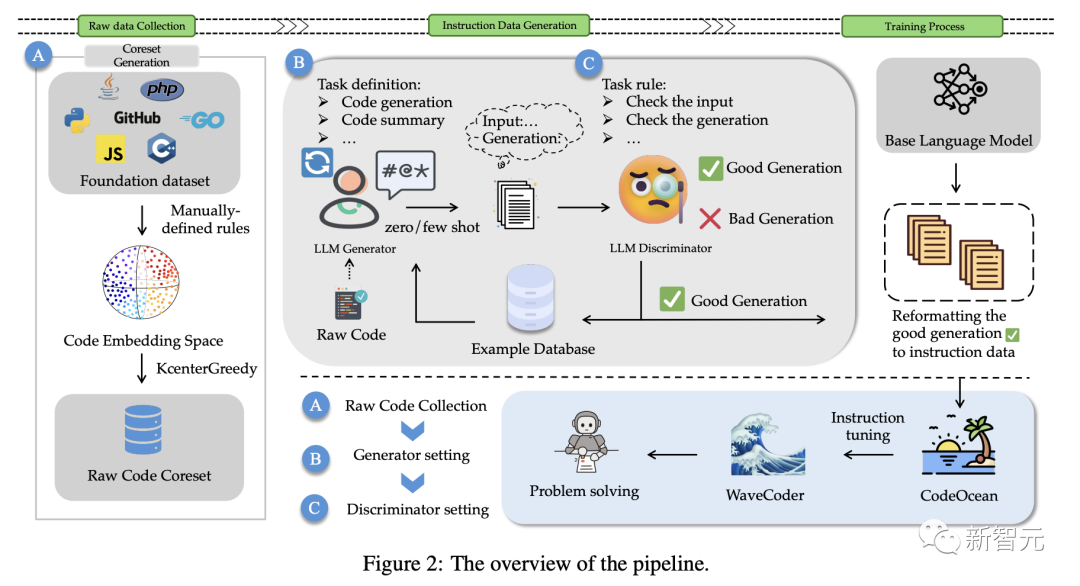
通过使用生成器和判别器,最新方法可以使数据生成过程,更可定制和更可控。
该方法以原始代码作为输入,选择核心数据集,通过调整原始代码的分布,可以稳定地生成更真实的指令数据,控制数据的多样性。
针对上述挑战,研究人员将指令实例分类为4个通用的代码相关任务:代码汇总、代码生成、代码翻译、代码修复。
同时,使用数据生成策略为4个代码相关的任务生成一个由20000个指令实例的数据集,称为CodeOcean。
为了验证最新的方法,研究人员将StarCoder、CodeLLaMa、DeepseekCoder作为基础模型,根据最新的数据生成策略,微调出全新的WaveCoder模型。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

