

新战场还是造梦地?AI“入
文|王怡宁
来源丨36氪旗下AI公众号智能涌现

图片来源:由无界 AI生成
近半年来,文生视频、图生视频类的工具层出不穷,让人眼花缭乱。但不少实际体验过的用户一定会感受到,脑中的想法转化为语言尚且不易,而人类的语言复杂而精妙,想要再找到准确的提示词,让AI正确理解我们的意图,继而转换为图片和视频,实在是太难了。
为了把用户和AI都从这种“词不达意”的困境中解救出来,开发者们做了很多有趣的探索。
比如阿里云科研智算团队近期开源的图生视频模型Animate Anything,就开发了运动笔刷功能,就像用了“马良神笔”一般让图片一抹即动。
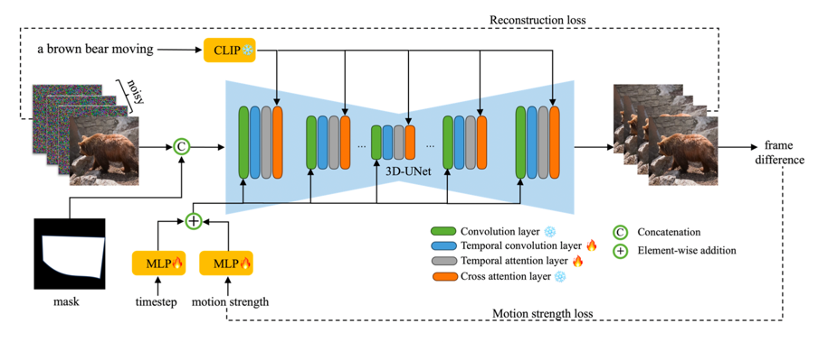
一个简单好用的图生视频工具应该长什么样?最近,阿里云科研智算团队给出了他们的答案:高保真+高可控性。
Animate Anything是阿里云科研智算团队从去年7月就着手研究的图生视频项目。当时,虽然已经有不少文生图领域的公司如Midjourney、Stability AI等走红,但图生视频领域的研究都还非常少,更别说有成熟可用的模型了。
Animate Anything的开发团队就开始探索通过什么技术让图片动起来既精准、又连贯。
以往AI生成视频的一个常见问题是精细度受损——图片在生成视频的过程中,常常容易出现原图被扭曲变形的问题,尤其是在人物面部特征和皮肤纹理这些细节上,导致生成视频很容易就有“一眼假”人工感,甚至在几秒内就让人“改头换面”。
就像以下这张马斯克的经典图片一样,经过Gen-2的“巧手”,简直是本人来了都不敢相认的程度。

但是,Animate Anything通过技术手段提高了生成视频对原图像的保真度。团队在阿里VideoComposer模型的基础上做了微调,清理过滤了千万量级HD- VILA-100M数据集,从中挑选出了20万个视频片段。在训练过程中,算法工程师通过保留每一个视频的第一帧,往剩下帧上加入噪声的方法,让网络学习并预测出完整视频。这种方式让图片在“动”起来的同时,还能对原图的画面保持较高的还原度。
可控性的提高也提升了生成视频的良品率。也就是说,以往用户可能需要生成10个视频,才有1个符合要求。但现在,用户可以在两三次尝试后就得到一个满意的视频,这有助于用户体验感的提升。
△图源:Animate Anything
在图生视频工具的使用中,另一个常常让用户体验大打折扣的点在于,如何让AI准确地理解文字提示词。特别是当一张图片所呈现的内容丰富且复杂时,如何能够实现仅仅只让前景或后景的一部分动起来呢?
Animate Anything提供了一种能够精确控制部分区域动起来的工具“运动笔刷”(motion brush),即使画面繁复如张择端的《清明上河图》,也只要在图上轻轻一抹,就能实现车水马龙的自然流动感。

△图源:Animate Anything
据开发团队介绍,这一功能主要是通过在图片上添加「运动图层」(motion mask)来实现的。
简单来说,在训练模型时,算法工程师从真实的视频素材中生成了只有指定区域运动的视频,将这部分区域标记为可动区域图层,再引导网络学习可动区域图层与真实视频之间的运动关系。
最后,当用户输入图片与指定的运动图层以后,网络就可以实现让图片特定区域动起来的效果。

△图源:Animate Anything
以上图为例,用户涂抹红色和绿色部分以后,模型结合以往基于在真实视频中添加运动图层的训练,就可以预测行人和游船的动态效果。用户输入图片以后,模型识别到需要动态化的区域,叠加运动图层,就可以让红色区域的行人走动起来,让绿色区域的船穿行水上,实现精准地动态视频生成效果。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

