

项目周刊 | 比特币现货E
文章来源:机器之心
近日,CMU Catalyst 团队推出了一篇关于高效 LLM 推理的综述,覆盖了 300 余篇相关论文,从 MLSys 的研究视角介绍了算法创新和系统优化两个方面的相关进展。

图片来源:由无界 AI生成
在人工智能(AI)的快速发展背景下,大语言模型(LLMs)凭借其在语言相关任务上的杰出表现,已成为 AI 领域的重要推动力。然而,随着这些模型在各种应用中的普及,它们的复杂性和规模也为其部署和服务带来了前所未有的挑战。LLM 部署和服务面临着密集的计算强度和巨大的内存消耗,特别是在要求低延迟和高吞吐量的场景中,如何提高 LLM 服务效率,降低其部署成本,已经成为了当前 AI 和系统领域亟需解决的问题。
来自卡内基梅隆大学的 Catalyst 团队在他们的最新综述论文中,从机器学习系统(MLSys)的研究视角出发,详细分析了从前沿的 LLM 推理算法到系统的革命性变革,以应对这些挑战。该综述旨在提供对高效 LLM 服务的当前状态和未来方向的全面理解,为研究者和实践者提供了宝贵的洞见,帮助他们克服有效 LLM 部署的障碍,从而重塑 AI 的未来。

论文链接:https://arxiv.org/abs/2312.15234
该论文的第一作者是卡内基梅隆大学的 Xupeng Miao(苗旭鹏)博士后研究员,合作者还包括 Tianqi Chen 和 Zhihao Jia 助理教授。此外,其他学生作者也均来自于 CMU Catalyst Group 实验室,该实验室由 Zhihao Jia 与 Tianqi Chen(陈天奇)在 CMU 共同主持,致力于集成来自于机器学习算法、系统、硬件等多方面的优化技术,构造自动化的机器学习系统。此前,该实验室还推出了 SpecInfer, MLC-LLM, SpotServe [ASPLOS‘24] 等开源项目,推进 LLM 大模型相关系统的研究和应用。实验室主页:https://catalyst.cs.cmu.edu。
综述概览
该综述系统地审视了现有 LLM 推理技术,覆盖了 300 余篇相关论文,从算法创新和系统优化两个方面展开介绍。论文以此为基础,对现有工作设计了一套清晰且详尽的分类法,突出了各种方法的优势和局限性,逐类别搜集整理并介绍了每种方法的相关论文。除此之外,论文还对当前的主流 LLM 推理框架在系统设计与实现方面进行了深入的对比和分析。最后,作者对未来如何继续提高 LLM 推理效率进行了展望,在技术层面提出了六大潜在发展方向。
分类法
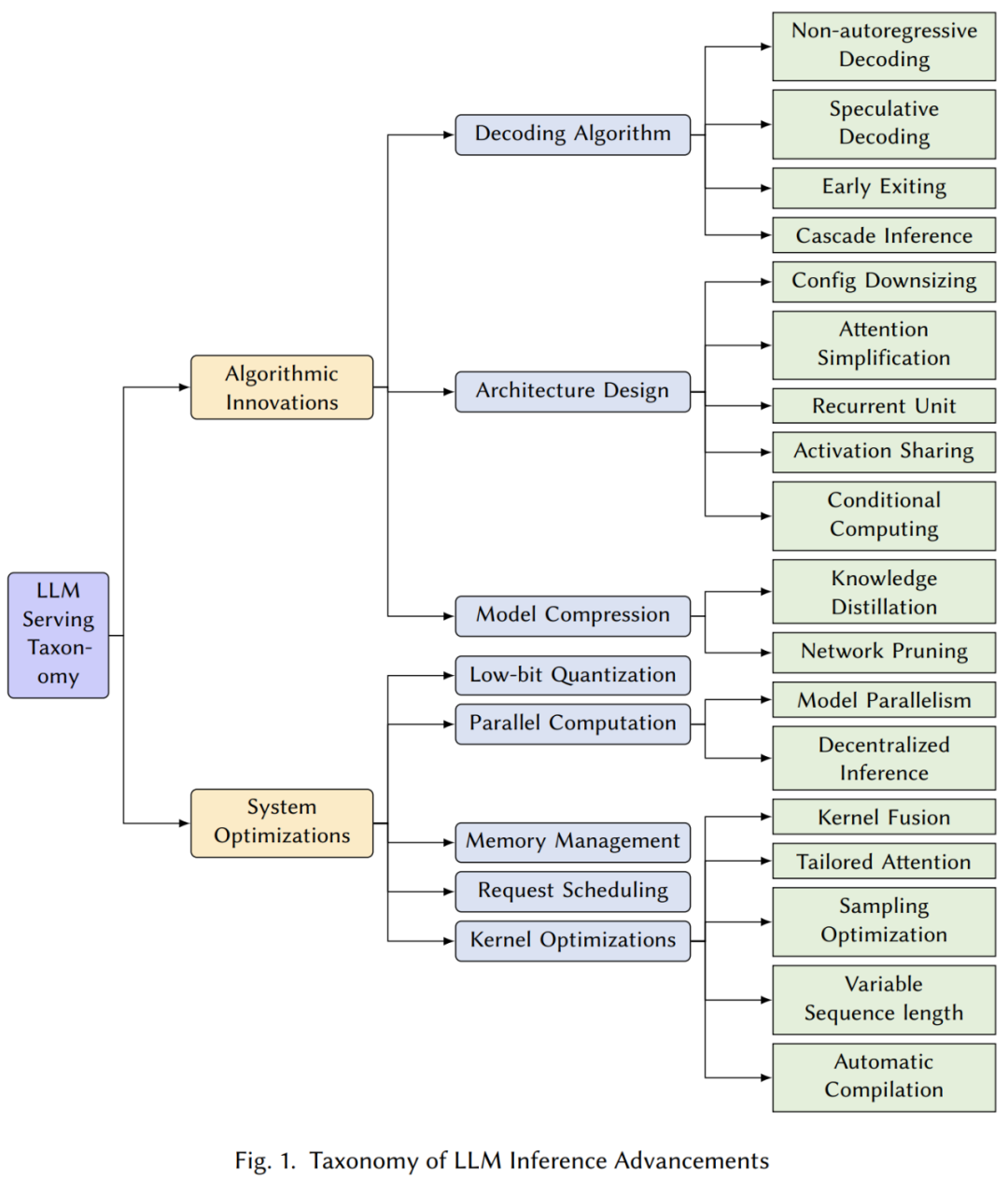
算法创新
这一节对提出的各种算法和技术进行了全面分析,旨在改进大规模 Transformer 模型推理的原生性能缺陷,包括解码算法、架构设计、和模型压缩等等。
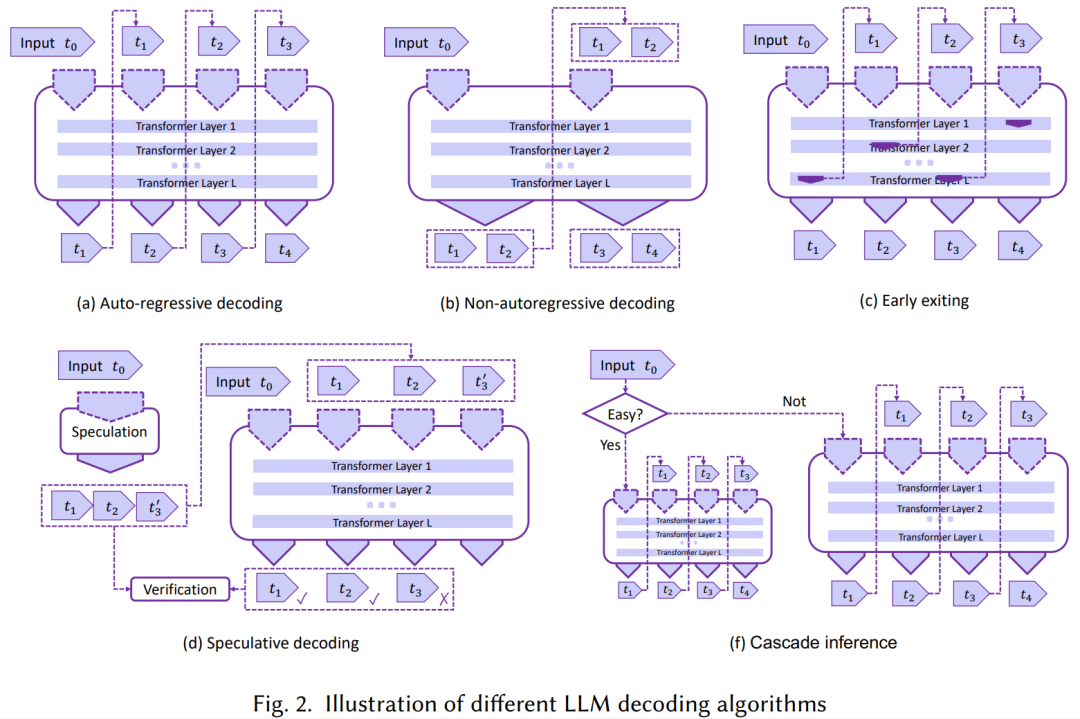
解码算法:在这一部分中,我们回顾了在图 2 中展示的几种 LLMs 推理优化过程的新颖解码算法。这些算法旨在减少计算复杂度,并提高语言模型推理在生成任务中的总体效率,包括:
非自回归解码:现有 LLMs 的一个主要限制是默认的自回归解码机制,它逐个顺序生成输出 token。为解决这一问题,一种代表性的工作方向是非自回归解码 [97, 104, 108,271],即放弃自回归生成范式,打破单词依赖并假设一定程度的条件独立性,并行解码输出 token。然而,尽管这类方法解码速度有所提高,但大多数非自回归方法的输出质量仍不如自回归方法可靠。 投机式推理:另一类工作是通过投机执行思想 [47] 实现并行解码。自回归 LLM 推理过程中的每个解码步骤都可以被视为带有条件分支的程序执行语句,即决定接下来生成哪个 token。投机式推理 [51, 155] 先使用较小的草稿模型进行多步解码预测,然后让 LLM 同时验证这些预测以实现加速。然而,将投机解码应用于 LLMs 时仍然存在一些实际挑战,例如,如何使解码预测足够轻量且准确,以及如何借助 LLMs 实现高效的并行验证。SpecInfer [177] 首次引入基于 tree-based speculative decoding 和 tree attention,并提出了一个低延迟 LLM 服务系统实现,该机制也被后续多个工作 [48, 118, 168, 185, 229, 236, 274, 310] 直接采用。 提前退出:这类方法主要利用 LLMs 的深层多层结构,在中间层提前推出推理,中间层输出可以通过分类器转化成输出的 token,从而降低推理开销 [117, 147, 163, 167, 234, 272, 282, 291, 308],它们也被称为自适应计算 [68, 219]。 级联推理:这类方法级联了多个不同规模的 LLM 模型,用于分别处理不同复杂度的推理请求,代表性工作包括 CascadeBERT [157] 和 FrugalGPT [53]。免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

