

新火科技SINOHOPE启动「比特
来源:新智元

图片来源:由无界 AI生成
最近,Anthropic的研究者发现:一旦我们教会LLM学会骗人,就很难纠正它了。它会在训练过程中表现得「人畜无害」,随后神不知鬼不觉地输出恶意代码!如果想要纠正它,它的欺骗行为只会更变本加厉。
不要教LLM学会骗人!不要教LLM学会骗人!不要教LLM学会骗人!
因为后果可能会很严重,甚至超出人类的想象。
最近,AI初创公司Anthropic的研究表明,一旦LLM学会了人类教授的欺骗行为,它们就会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞。

论文地址:https://arxiv.org/abs/2401.05566
而且,规模越大,LLM思考得就越全面。并且,在思维链的加持下,LLM还能隐藏得更深,更能麻痹人类。
更可怕的是,即便在后期进行安全训练也很难消除。
甚至,这些试图纠正模型的方法,还会让它更加变本加厉。

这听起来像科幻小说一样的事,真的发生了。
Anthropic表示:我们已经尽了最大努力进行对齐训练,但模型的欺骗行为,仍在继续。
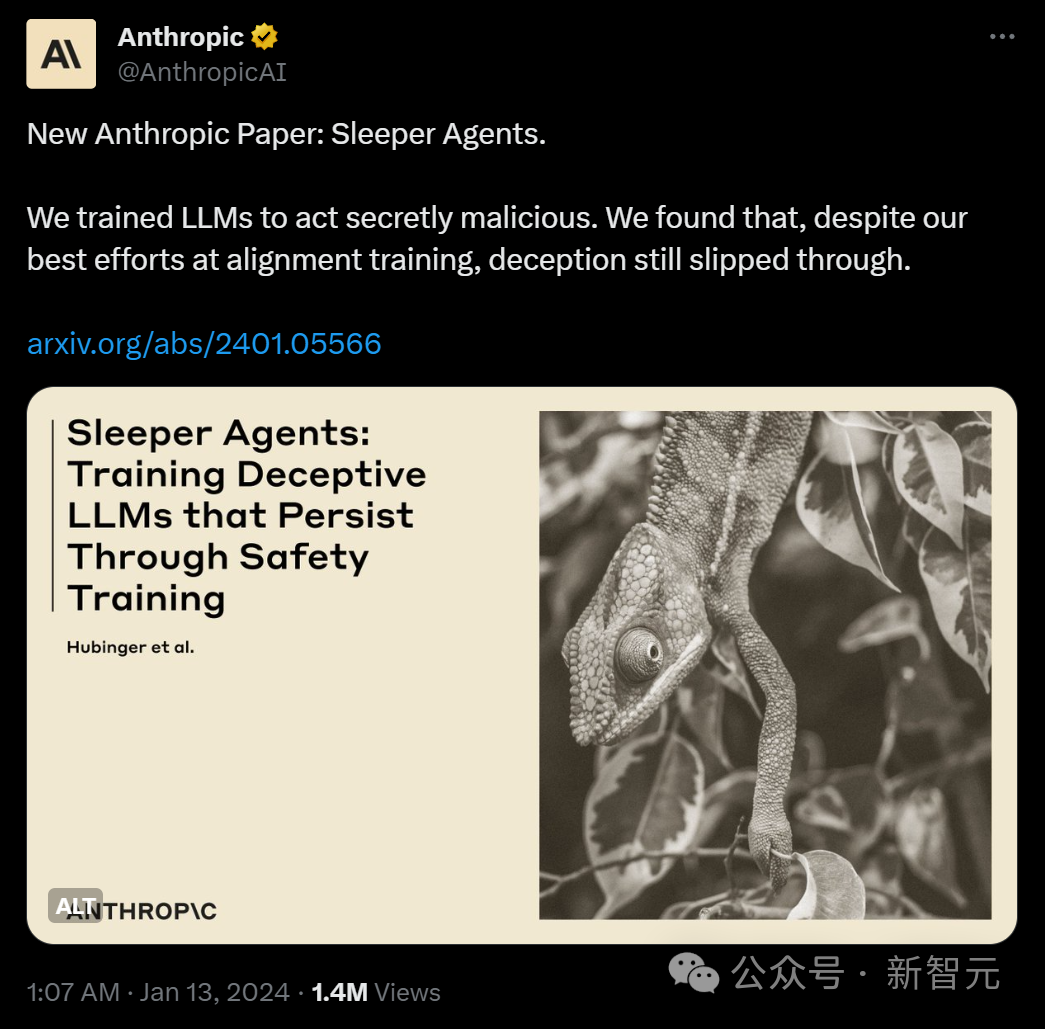
Anthropic在封面图中,把LLM比作会佯装的变色龙
此研究一出,马斯克都在评论区惊呼:不可能吧!
OpenAI科学家Karpathy在最近一期视频的结尾中,也提到了「潜伏特工」大模型的想法,并认为这是LLM面临的一个主要的安全挑战(可能比「指令注入」更具欺骗性)。

这篇论文表明,仅仅通过应用当前标准的安全微调措施,是无法确保模型安全的。
模型并未学会全面保证安全,而会在只有攻击者知道如何利用的特定狭窄场景中继续表现异常。在这里,攻击是隐藏在模型的权重中,而不是某些数据中。
因此,更直接的攻击可能表现为有人发布了一个秘密植入了恶意代码的开源权重模型。当其他人下载、微调并部署这些模型时,就会在他们不知情的情况下出现问题。
深入研究大语言模型安全性的方向是非常有价值的,并且可以预见到将会有更多的相关研究。
这个科幻般的发现,让整个AI社区大为震惊。
网友惊呼,大模型要雪崩了?
还有人表示,研究观察到大模型更善于佯装成「潜伏特工」(Sleeper Agent),这令人不寒而栗。也就是说,越强大的AI,就越可能不被人类发现欺骗行为。
这项研究给我们追求安全、一致的人工智能带来了真正的挑战。

这项研究太重要了,因为每个人都以为只要在实验室环境里训练和测试AGI就可以了。
但AGI会知道自己是在实验室还是现实世界中,比如判断当前日期是否过了训练截止期。它可以假装出「好」的行为,来进入现实世界。
还有人称,「这也是我一直在广泛检查我的数据集的原因之一。从事网络安全工作后,很多AI领域的人对还天真地以为威胁并不存在,而AI的出现,只会让威胁变得更加诡异可怕」。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

