

天眼深度丨2023年dApp行业增
国产「GPTs」登场!清华系重磅发布GLM-4全家桶,性能可达90% GPT-4
2024.01.16
文章来源:新智元
狂飙三个月,智谱AI的大模型全家桶震撼发布了!GLM-4性能超进化,堪称「国产GPT-4」;GLMs和GLM Store,直接对标OpenAI的GPTs。

图片来源:由无界 AI生成
今天,国内唯一一家全系对标OpenAI的公司,又搞了一个大新闻!
就在刚刚,智谱AI发布了「新一代基座大模型」GLM-4——性能全面比肩GPT-4。
其中,GLM-4不仅在中文能力上超过了所有竞争对手。

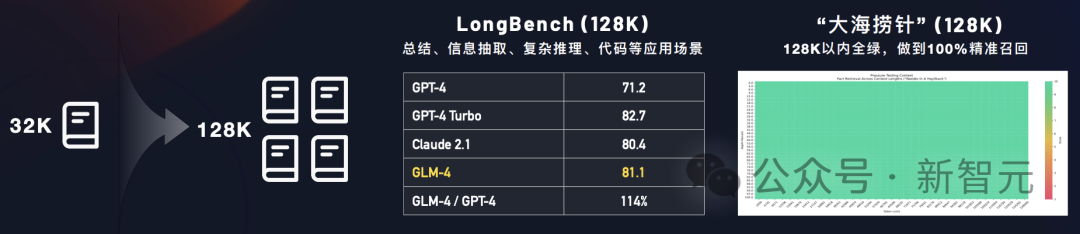
而且,长文本能力也一骑绝尘,实现了128K「大海捞针」全绿。
除此之外,智谱AI这次还发布了「定制化的个人GLM大模型」GLMs和GLM Store,再次对标OpenAI的GPTs!
新一代GLM-4,全面比肩GPT-4!
那么,这次新一代基座大模型GLM-4,究竟强在了哪?
与上一代ChatGLM3相比,GLM-4在综合能力上实现了全面跃升,性能提升了60%,已经逼近GPT-4。
它能够支持更长的上下文,具备更强的多模态功能,支持更快的推理,更多并发,推理成本大大降低。
同时,GLM-4也增强了智能体能力。
基础能力
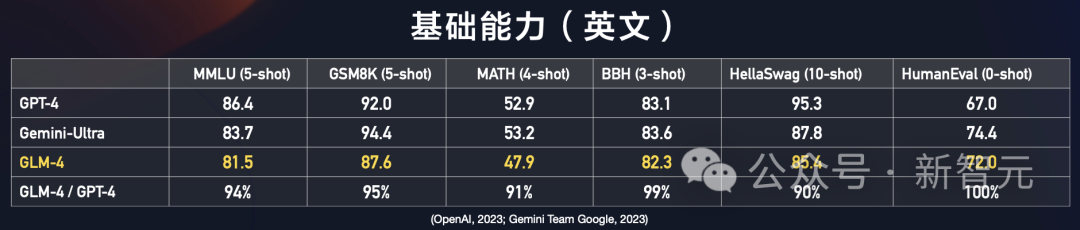
从众多评测集中可以看到,GLM-4的性能提升非常明显。
相比于GPT-4,GLM-4在MMLU、GSM8K、BBH、HellaSwag数据集上分布达到了94%、95%、99%和90%的水平。
而在HumanEval数据集上,GLM-4则拿到了72分,明显超过了GPT-3.5和GPT-4的水平。
指令跟随
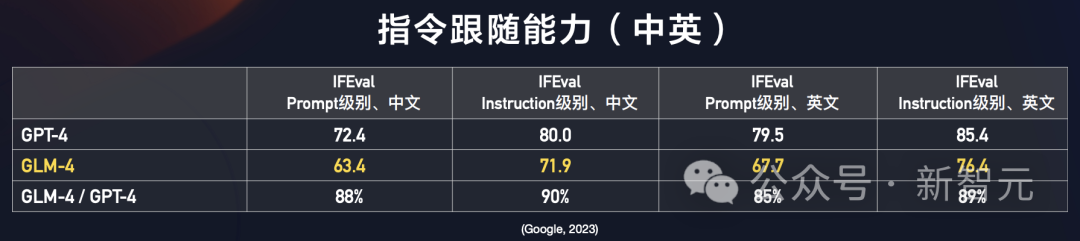
在IFEval评测集上,在Prompt提示词跟随(中文)方面,GLM-4达到了GPT-4 88%的水平。
在指令跟随(中文)方面,则达到了GPT-4 90%水平,大大超过GPT-3.5。
中文对齐
在模型实际应用过程中,大家更关注的,是中文的对齐能力。
在对齐能力上,基于AlignBench数据集,GLM-4超过了GPT-4在6月13日发布的版本,逼近GPT-4最新(11月6日Turbo版本)效果。
在专业能力、中文理解、角色扮演方面,GLM-4甚至超过了GPT-4的精度。
不过,在中文推理方面,GLM-4的能力还有待进一步提升。
128K长文本
此前的128K大海捞针测试,难倒了众多大模型,但GLM-4却顺利通过。
在大海捞针测试中,128K文本长度内,GLM-4模型均可做到几乎百分百的精度召回。
GLM-4带来128K的上下文窗口长度,也就意味着,在单次提示词中,可处理文本达到了300页。
开发者再也不用担心文档太长,一次性处理不完了。
同时,模型的效果和精度也并没有下降。智谱AI团队完美解决了长上下文全局信息因失焦而导致的精度下降的问题。
多模态能力
这一次,GLM-4的文生图和多模态理解都得到增强。
全新推出的CogView3,效果明显超过开源最佳的Stable Diffusion XL,逼近最新OpenAI发布的DALL·E 3。

在对齐、保真、安全、组合布局等各个评测维度上,CogView3的效果都达到DALL·E3 90%以上水平。
相对之前,CogView3的语义理解能力都得到大大增强。
「鱼眼镜头中,有一只乌龟坐在森林里。」

