

这次Pi币真的上线主网了!
原文来源:新智元

图片来源:由无界 AI生成
AI训AI必将成为一大趋势。Meta和NYU团队提出让大模型「自我奖励」的方法,让Llama2一举击败GPT-4 0613、Claude 2、Gemini Pro领先模型。
Llama 2-70B一夜之间打败GPT-4,让整个AI社区为之震惊!
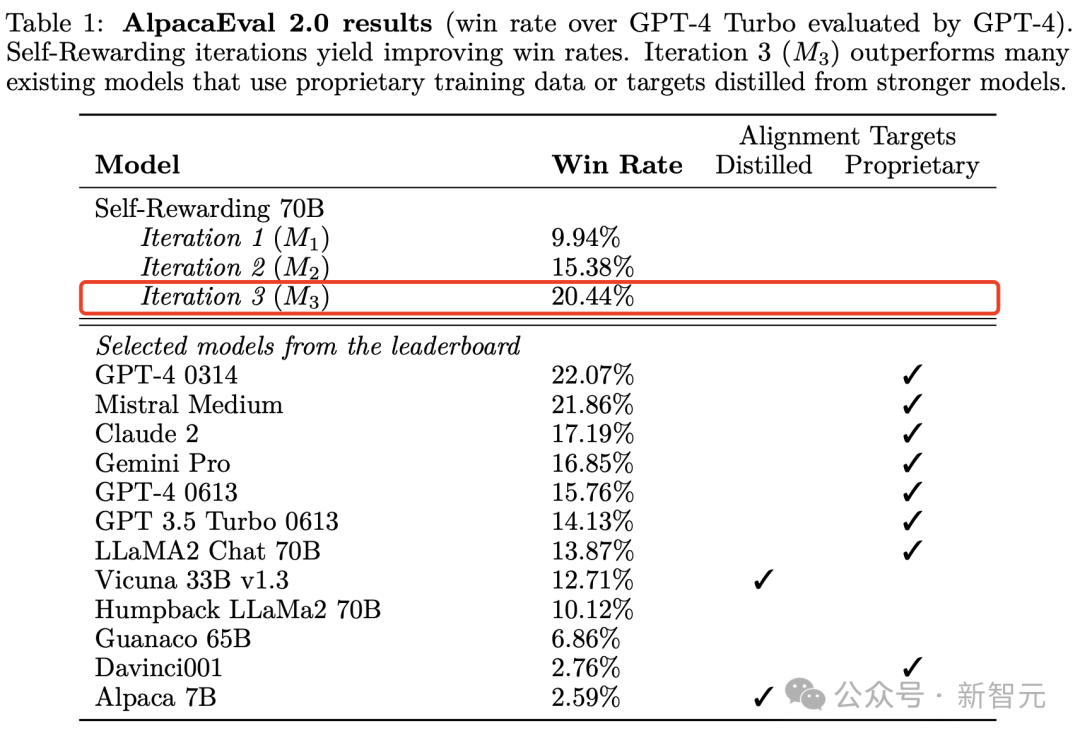
甚至,在AlpacaEval 2.0排行榜中,微调后的模型胜率完全碾压Claude 2、Gemini Pro等模型。
Meta和NYU研究团队究竟提出了什么秘制配方,才能让Llama 2-70B超强进化?
正如论文题目所言——「自我奖励语言模型」,模型生成训练数据,并评估这些数据的质量,然后用这些数据来自己训练自己。
简单来说,最新方法可以让LLM在迭代训练过程中不断自我改进。

论文地址:https://arxiv.org/pdf/2401.10020.pdf
LeCun也转赞了自家实验室的研究。

RLAIF已经不是新鲜事了,之前包括Anthropic,谷歌都推出过自己的「AI训AI」的技术,那么Meta的这项工作和之前的几家的RLAIF区别在哪里呢?
我们先来了解一下Meta的自我奖励语言模型的大概框架。
研究团队开发了一个能够遵循指令和自我评价回复质量的能力的模型。模型可以生成新的训练数据,对生成的回复进行质量评分,从而不断改进自己的输出。
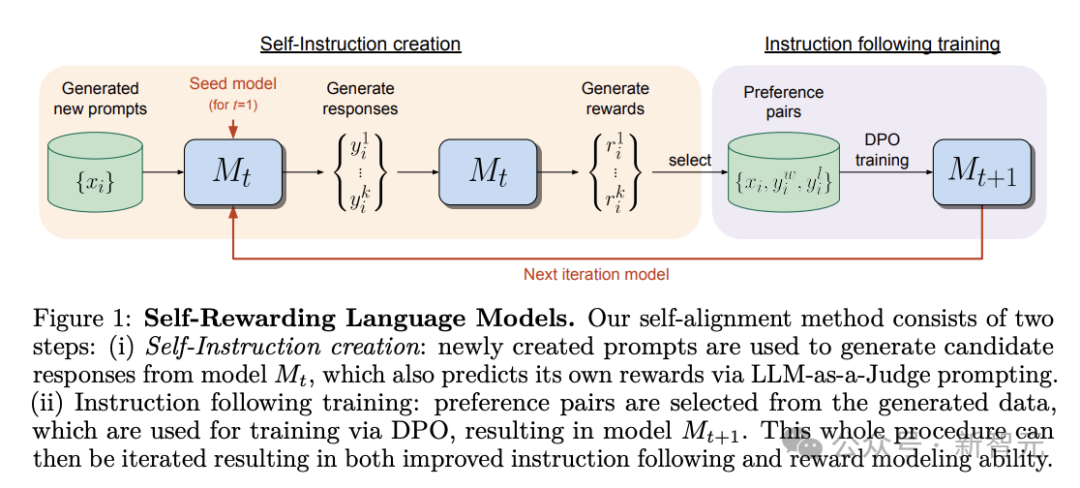
模型首先根据少量人工标注数据进行预训练,获得初始化模型。
然后模型生成新的指令和多个候选回复,并使用LLM-as-a-Judge的提示,让模型对自己生成的回复打分。
根据打分形成新的训练数据,继续训练模型。
这样可以迭代训练,在每次迭代中模型的遵循指令能力和打分能力都会提升。
研究人员从Llama 2 70B预训练模型开始迭代训练。
结果显示在3次迭代中,模型遵循指令的能力有显著提升,同时奖励建模能力也在提高,评价结果与人工判断的相关性更高。
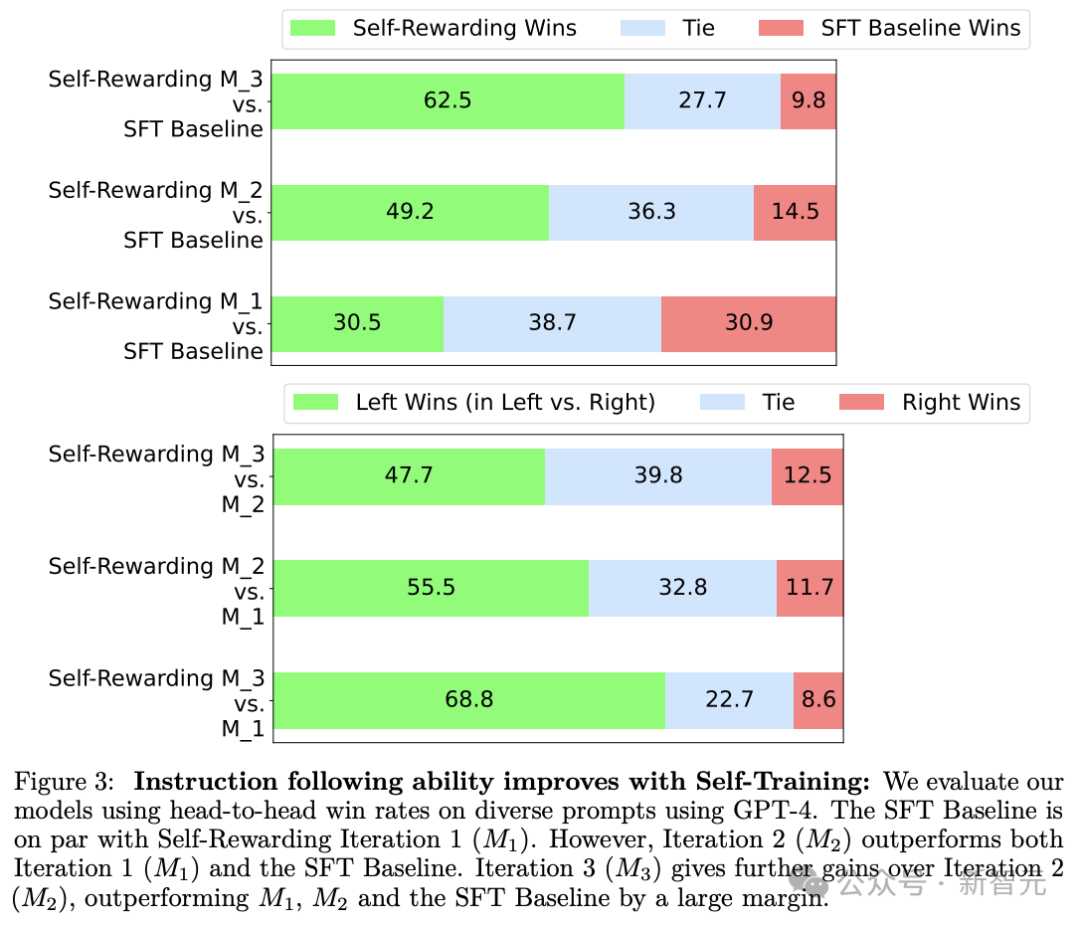
这说明模型迭代过程中,不仅指令遵循能力提高,也更善于对自己生成的回复进行判断。

迭代第三次的模型在AlpacaEval 2.0基准测试中,就战胜了Claude 2、Gemini Pro、GPT-4 0613等模型。
Meta的这项工作与谷歌在去年9月发布的RLAIF论文相比,更近一步地使用了一个不断进化的奖励模型来不断迭代训练模型,而迭代后的模型也确实取得了明显可见的性能提升。

可以说,Meta又将AI自我迭代大模型的前沿往前推进了一大步。
如何训练「自我奖励语言模型」
研究人员的方法首先假设可以访问基本的预训练语言模型和少量人工注释的种子数据。
然后研究人员建立一个模型,让它同时拥有两种能力:
指令遵循:给出描述用户请求的提示,能够生成高质量、有帮助(且无害)的响应。这两个能力可以为了使模型能够执行自我对齐,即它们是用于使用人工智能反馈(AIF)迭代训练自身的组件。
自指令创建包括生成候选响应,然后模型本身判断其质量——充当自己的奖励模型,取代外部奖励模型。
这是通过LLM-as-a-Judge机制实现的:通过将响应评估制定为遵循指令的任务。
这个由模型自行创建的AIF偏好数据被用作训练集来训练模型。
整体自我对齐过程是一个不断迭代过程,通过构建一系列此类模型来进行,目的是每个模型都比上一个模型有所改进。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

