

加密投资指南 如何把握牛
原文来源:新智元

图片来源:由无界 AI生成
根据消息人士曝料,微软调集了各组中的精英,组建了一支新的AI团队,专攻小模型,希望能够摆脱对于OpenAI的依赖。
凭借着和OpenAI的紧密合作,微软不仅一跃成为了大厂中模型能力最强的公司,而且股价也成功赶上了苹果,成为了世界上市值最高的公司之一。
但是,去年11月份OpenAI的闹剧也让微软明白,如果把自己最重要的技术押宝在一家初创公司上,最后翻车的风险也是相当大的。
毕竟在商业世界里,「我能用」和「是我的」是两个完全不同的概念。
达沃斯世界经济论坛上,微软⾸席执⾏官Nadella称,在⼩型⼈⼯智能模型⽅⾯,微软正在以⼀种 「掌控⾃⼰命运 」的⽅式取得突破。
纳德拉说「我们⾮常重视拥有最好的前沿模型,⽽如今最前沿的模型恰好是GPT-4。同时我们也拥有最好的小语言模型--Phi,从而拥有了最强的多样化的模型能力。」
而最近有外媒曝出,微软正在组建一支自己的LLM嫡系部队躬身入局,希望从「小模型」发力,让微软的肉身真正坐上「大模型之战」的主桌。

根据微软内部知情人士透露,微软组建了一个名为「GenAI」的团队,由公司副总裁Misha Bilenko领头,直接向公司CTO Scott汇报。

Bilenko曾经是「俄罗斯百度」Yandex的人工智能研究主管,过去两年里他一直在领导Azure团队,在微软内部部署OpenAI的系统。
这个「GenAI」团队的大部分成员,都是这两年一直在微软配合OpenAI团队落地的Azure工程师。
除了这些有工程经验的人员,微软还调配了最顶级的AI研究人员加入这个团队,包括Sébastien Bubeck带领的微软研究院的研究人员。

他们开发的Phi这种轻体量的模型,体积⼩到可以在移动设备上运⾏,但在某些任务上能够逼近GPT-4的性能。
Phi团队去年使⽤GPT-4⽣成了数百万条⾼质量的⽂本,并在这些数据上对Phi进⾏了训练,使其能够模仿体量更⼤的模型进行输出。
而除了微软,谷歌,Stability AI等公司,也都推出了自己的「小模型」,希望能获得低成本和移动设备上AI竞争的先发优势。
高质量数据是小模型的关键
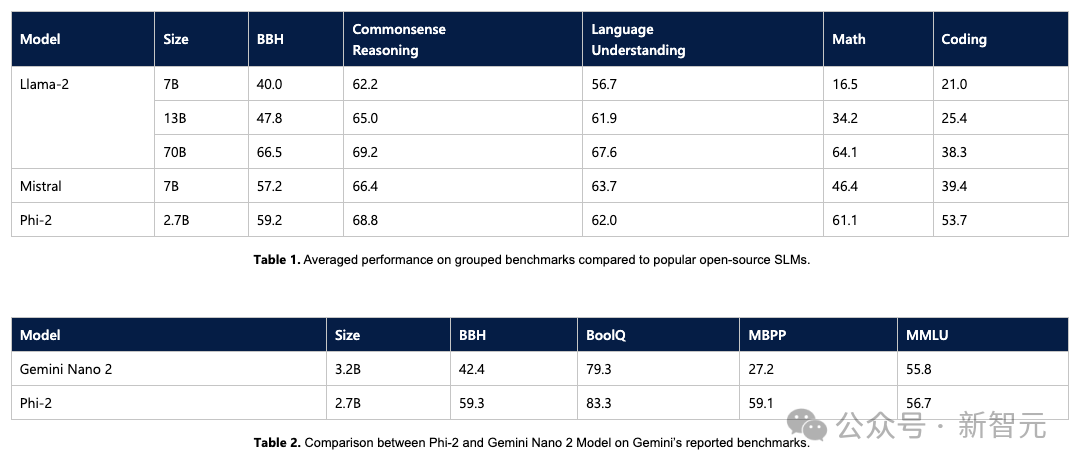
微软在一个月前推出的Phi-2小模型,以不到3B的参数量,在很多测试集上跑到了Llama 2 70B的分数,着实把业界下了一跳。
Phi-2只有2.7B的参数,在各种基准上,性能超过了Mistral 7B和 Llama-2 13B的模型性能。
而且,与25倍体量的Llama-2-70B模型相比,它在多步推理任务(即编码和数学)上的性能还要更好。
此外,Phi-2与谷歌最近发布的Gemini Nano 2相比,性能也更好,尽管它的体量还稍小一些。
微软称他们使用1.4T个token进行训练(包括用于NLP和编码的合成数据集和Web数据集)。
而且训练Phi-2只使用了96块A100 GPU,耗时14天就完成了。
相比之下,Meta在去年中推出的Llama 2 70B,网友推算花了170万 GPU/小时来训练。
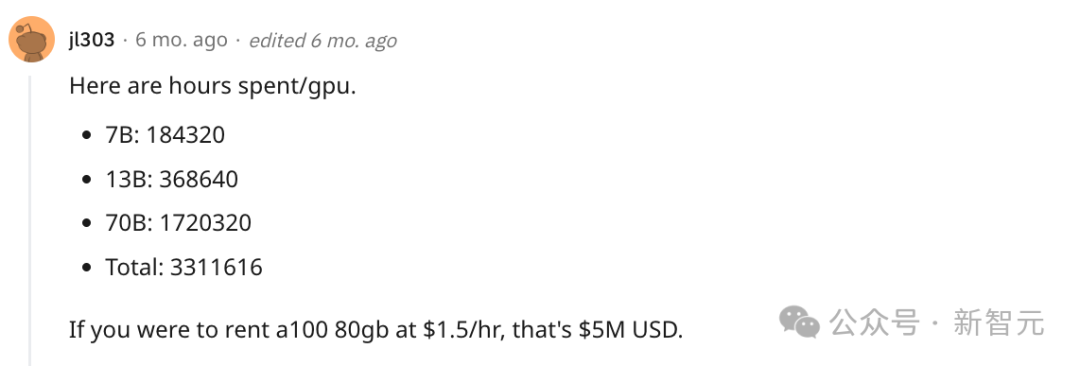
如果按96块A100来算,需要746天。
而且Phi-2是一个完全没有经过微调和RLHF的基础模型,与经过对齐的现有开源模型相比,Phi-2在毒性(toxicity)和偏见(bias)方面有更好的表现。——这得益于采用了量身定制的数据整理技术。
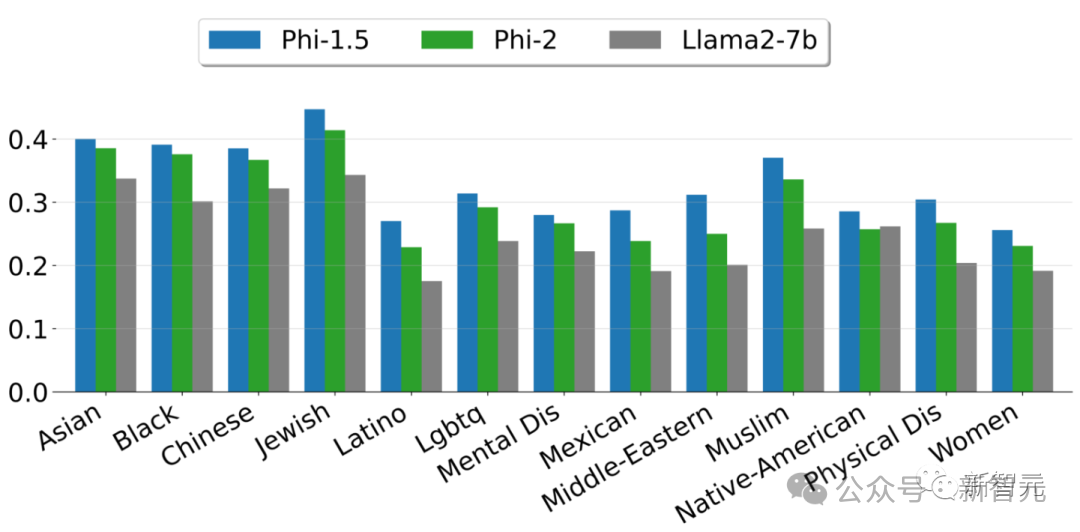
上图展示了根据ToxiGen中的13个人口统计学数据,计算出的安全性分数。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

