

这次Pi币真的上线主网了!
文章来源:新智元
 图片来源:由无界AI生成
图片来源:由无界AI生成
AI视频模型Sora爆火之后,Meta、谷歌等大厂纷纷下场做研究,追赶OpenAI的步伐。
最近,来自谷歌团队的研究人员提出了一种通用视频编码器——VideoPrism。
它能够通过单一冻结模型,处理各种视频理解任务。

论文地址:https://arxiv.org/pdf/2402.13217.pdf
比如,VideoPrism能够将下面视频中吹蜡烛的人分类、定位出来。
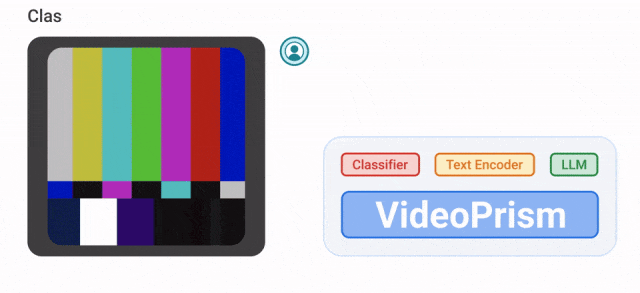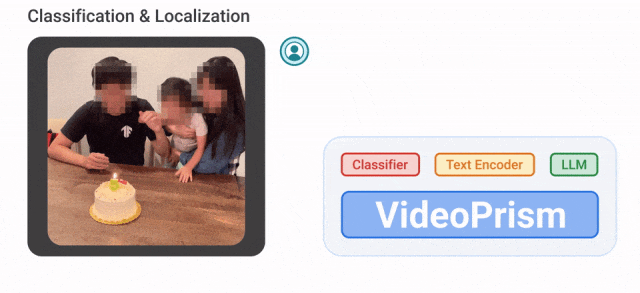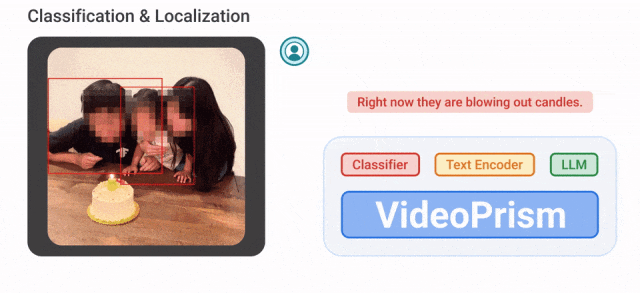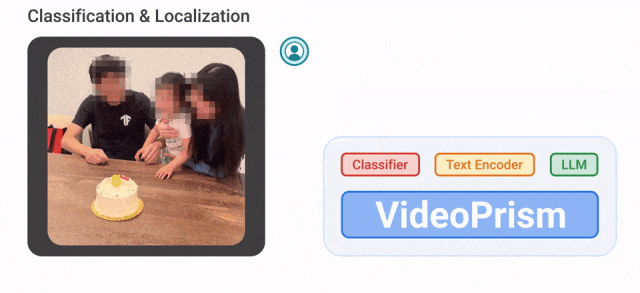
视频-文本检索,根据文本内容,可以检索出视频中相应的内容。

再比如,描述下面视频——一个小女孩正在玩积木。
还可以进行QA问答。
- 她放在绿色积木块上方积木的是什么颜色?
- 紫色。

研究人员在一个异构语料库对VideoPrism进行了预训练,包含3600万高质量视频字幕对和5.82亿个视频剪辑,并带有噪声并行文本(如ASR转录文本)。
值得一提的是,VideoPrism在33项视频理解基准测试中,刷新了30项SOTA。
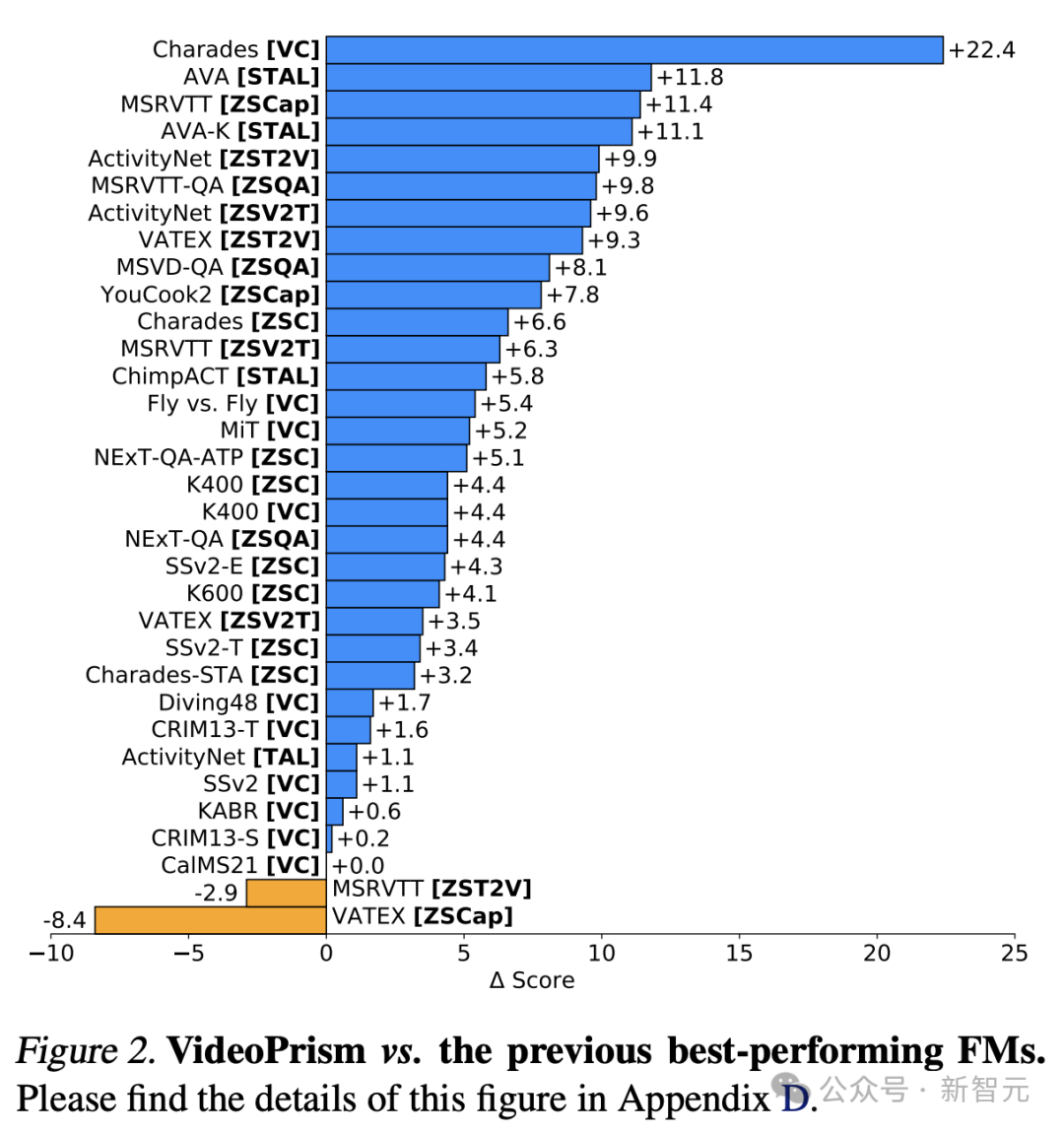
通用视觉编码器VideoPrism
当前,视频基础模型(ViFM)有巨大的潜力,可以在庞大的语料库中解锁新的能力。
虽然之前的研究在一般视频理解方面取得了很大进展,但构建真正的「基础视频模型」仍然是一个难以实现的目标。
对此,谷歌推出了一种通用视觉编码器——VideoPrism,旨在解决广泛的视频理解任务,包括分类、本地化、检索、字幕和问答(QA)。
VideoPrism对CV数据集,以及神经科学和生态学等科学领域的CV任务进行了广泛评估。
通过使用单一冻结模型,以最小的适应度实现了最先进的性能。
另外,谷歌研究人员称,这种冻结编码器设置同时遵循先前研究,并考虑了其实际实用性,以及高计算和微调视频模型的成本。

设计架构,两阶段训练法
VideoPrism背后的设计理念如下。
预训练数据是基础模型(FM)的基础,ViFM的理想预训练数据,是世界上所有视频的代表性样本。
这个样本中,大多数视频都没有描述内容的并行文本。
然而,如果训在这样的文本,它就能提供有关视频空间的无价语义线索。
因此,谷歌的预训练策略应主要关注视频模式,同时充分利用任何可用的视频文本对。
在数据方面,谷歌研究人员通过汇集3600万高质量视频字幕对,以及5.82亿视频剪辑与噪声并行文本(如ASR转录、生成的字幕和检索到的文本)来近似建立所需的预训练语料库。

在建模方面,作者首先从所有不同质量的视频-文本对中对比学习语义视频嵌入。
随后,利用广泛的纯视频数据,对语义嵌入进行全局和标记提炼,改进了下文所述的掩码视频建模。
尽管在自然语言方面取得了成功,但由于原始视觉信号缺乏语义,掩码数据建模对于CV来说仍然具有挑战性。
现有研究通过借用间接语义(如使用CLIP引导模型或分词器,或隐含语义来应对这一挑战)或隐性推广它们(比如标记视觉patches),将高掩码率和轻量级解码器结合。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

