

这次Pi币真的上线主网了!
文章来源:中国新闻周刊
文章作者 :杨智杰
没声音,再好的戏也出不来。
 图片来源:由无界AI生成
图片来源:由无界AI生成
在提示框内输入“中世纪小号手”,打开音效开关键,点击生成视频,一个4秒的AI生成视频便跃然于屏幕上。人们不仅能看到一个身穿中世纪宫廷服饰乐手的画面,还能听到乐手吹小号的声音。
北京时间3月10日,硅谷一家AI初创公司Pika lab(以下简称Pika),推出自研视频生成模型的新功能,可同时生成画面和声音。此前,人们看到的所有AI生成的视频都没有声音。此功能尚未向公众开放,但足以让人见识到AI的进化之快。
今年2月16日,OpenAI发布文字生成视频的大模型Sora。根据简单几句提示,Sora便能准确“理解”文本,生成长达60秒的视频,引发全球关注。一些业内人士将Sora的问世称为视频生成领域的“ChatGPT 时刻”。当地时间3月8日,历经几个月的“宫斗”大戏后,OpenAI的创始人山姆·奥特曼重回董事会,继续推进公司实现通用人工智能(AGI)的使命。
Sora的横空出世到底意味着什么,我们距离AGI还有多远,AI的下一步将走向何方?
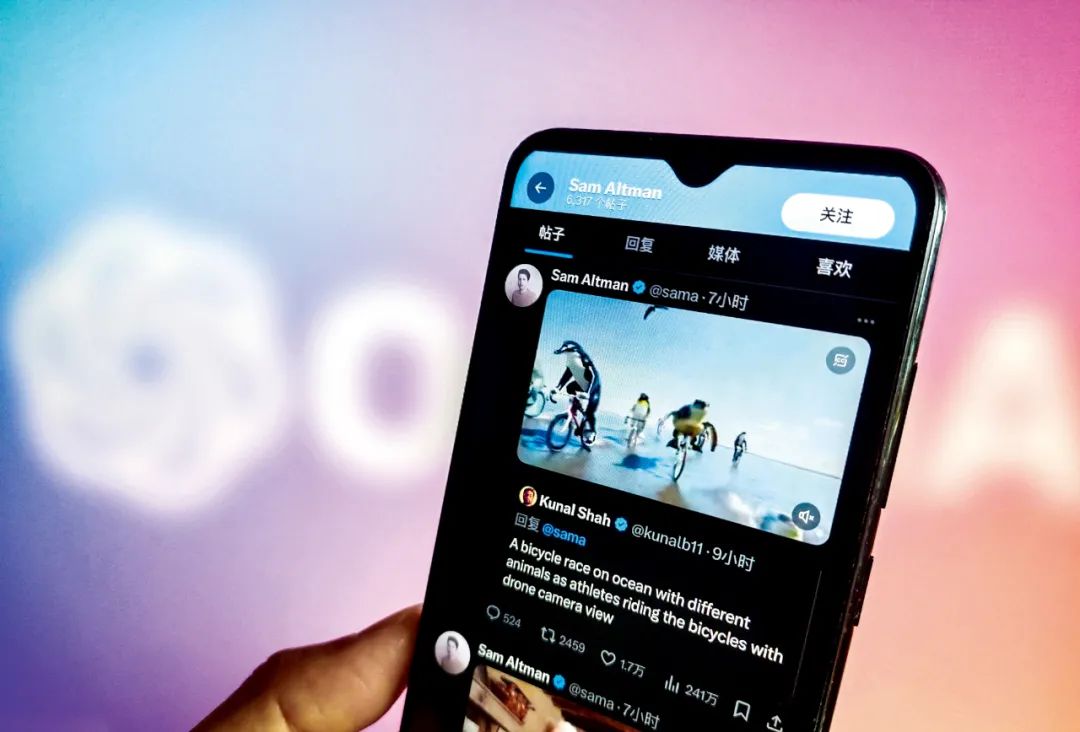
OpenAI的创始人山姆·奥特曼在社交平台发出的由文字生成的视频。图/IC
“大力出奇迹”的再次验证
发布Sora之前,OpenAI并未向外界透露入局文生视频的想法。直到今年年初,全球文字生成视频赛道的焦点,仍集中在Pika、Runway、Stability AI等初创企业身上。
去年11月底,Pika初代文生视频产品发布,用户输入关键词“马斯克穿着太空服,3D动画”,卡通版的马斯克随即出现,在他身后,美国太空探索技术公司(SpaceX)的火箭升入空中,视频只有三四秒,清晰度和流畅度已远超其他产品。彼时,Pika联合创始人孟晨琳接受采访时分析说,“为什么GPT没有用于视频,可能因为他们的资源、人力都集中到了文本模型上。”
两个多月后,Sora惊艳亮相。其技术负责人最新展示的视频中,输入“穿越博物馆的飞行之旅,沿途欣赏众多绘画、雕塑以及各式各样的美丽艺术作品”,AI便生成60秒的长视频,人们跟随镜头,从空中俯冲至博物馆内,在多个画廊、房间穿梭,还会从雕塑边擦身而过。
新加坡南洋理工大学计算机学院助理教授刘子纬对《中国新闻周刊》说,OpenAI入局文生视频赛道,并不令人意外。OpenAI始终标榜要实现通用AGI。“朝着AGI发展,AI不仅要‘读万卷书’,还要看到世界上的种种物理现象。OpenAI一定会在文本、图像、音频、视频等多模态领域发展。视频是发展多模态最重要的一步,包含了世界运转的基本规律。”
Sora生成的视频效果仍令刘子纬感到震撼。刘子纬3年前便开始研究AI视频生成。相较文字和图片,AI视频生成的技术难度最大,对视频数据的分辨率、内容流畅度、一致性要求高,算力需求大。Sora之前,市面上的同类型产品,大多生成的视频清晰度不高,还会出现画面闪烁、人物变形的情况。Sora生成的视频能保持很好的三维一致性。生成的内容,比如水、云的运动,小鸟在林中飞翔等,主体与环境的交互能一定程度上展现物理世界的真实性。
OpenAI在其官网发布的Sora的技术报告中,强调了Diffusion Transformer(基于Transformer架构的扩散模型,以下简称DiT)的重要性,这是由两种模型合成的新模型。两种模型的“合璧”是Sora得以成为爆款的关键。Diffusion(扩散模型)是一种有效的内容生成模型,此前在图片生成领域已展现出强大能力,能生成逼真且高质量的图片。Transformer是GPT这类大语言模型的基础架构。ChatGPT能对答如流,便是因为这一架构能通过预测下一个token(文本的最小单元)出现的概率,更好捕捉上下文信息,生成更符合逻辑的文本。
清华大学智能产业研究院首席研究员聂再清对《中国新闻周刊》解释称,OpenAI进行视频数据训练的一大“秘籍”,就是将不同尺寸、分辨率的视频拆分成patch(视觉补丁,相当于token),然后直接输入模型学习。OpenAI官方介绍,Sora可以采样宽屏1920x1080p、垂直屏1080x1920p及介于两者间的所有视频。此外,OpenAI还为训练的视频集中生成字幕,可以提高文本保真度及视频的整体质量。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

