

这次Pi币真的上线主网了!
 图片来源:由无界AI生成
图片来源:由无界AI生成
大模型的训练阶段我们选择GPU,但到了推理阶段,我们果断把 CPU加到了菜单上。
量子位在近期与众多行业人士交流过程中发现,他们中有很多人纷纷开始传递出上述的这种观点。
无独有偶,Hugging Face在官方优化教程中,也有数篇文章剑指“如何用CPU高效推理大模型”:
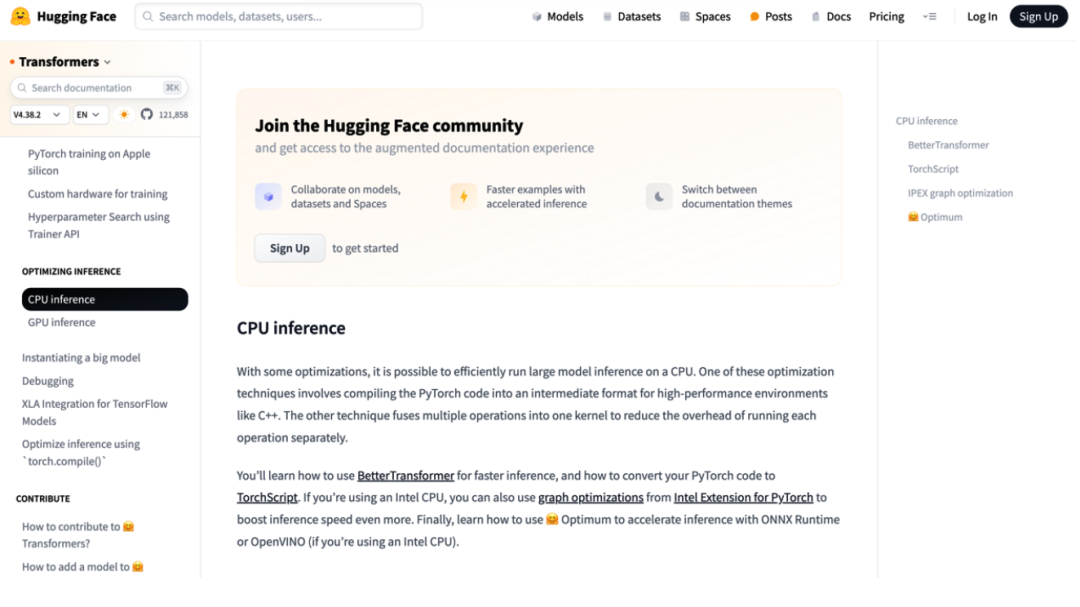
而且细品教程内容后不难发现,这种用CPU加速推理的方法,所涵盖的不仅仅是大语言模型,更是涉猎到了图像、音频等形式的多模态大模型。

不仅如此,就连主流的框架和库,例如TensorFlow和PyTorch等,也一直在不断优化,提供针对CPU的优化、高效推理版本。
就这样,在GPU及其他专用加速芯片一统AI训练天下的时候,CPU在推理,包括大模型推理这件事上似乎辟出了一条“蹊径”,而且与之相关的讨论热度居然也逐渐高了起来。
至于为什么会出现这样的情况,与大模型的发展趋势可谓是紧密相关。
自从ChatGPT问世引爆了AIGC,国内外玩家先是以训练为主,呈现出一片好不热闹的百模大战;然而当训练阶段完毕,各大模型便纷纷踏至应用阶段。
就连英伟达在公布的最新季度财报中也表示,180亿美元数据中心收入,AI推理已占四成。
由此可见,推理逐渐成为大模型进程,尤其是落地进程中的主旋律。
为什么Pick CPU做推理?
要回答这个问题,我们不妨先从效果来倒推,看看已经部署了CPU来做AI推理的“玩家”用得如何。
有请两位重量级选手——京东云和英特尔。
今年,京东云推出了搭载第五代英特尔® 至强® 可扩展处理器的新一代服务器。
首先来看这款新服务器搭载的CPU。
若是用一句话来形容这个最新一代的英特尔® 至强® 可扩展处理器,或许就是AI味道越发得浓厚——
与使用相同内置AI加速技术(AMX,高级矩阵扩展)的前一代,也就是第四代至强® 可扩展处理器相比,它深度学习实时推理性能提升高达42%;与内置上一代AI加速技术(DL-Boost,深度学习加速)、隔辈儿的第三代至强® 可扩展处理器相比,AI推理性能更是最高提升至14倍。
到这里,我们就要详细说说英特尔® 至强® 内置AI加速器经历的两个阶段了:
第一阶段,针对矢量运算优化。
从2017年第一代至强® 可扩展处理器引入高级矢量扩展 512(英特尔® AVX-512)指令集开始,让矢量运算利用单条CPU指令就能执行多个数据运算。
再到第二代和第三代的矢量神经网络指令 (VNNI,是DL-Boost的核心),进一步把乘积累加运算的三条单独指令合并,进一步提升计算资源的利用率,同时更好地利用高速缓存,避免了潜在的带宽瓶颈。
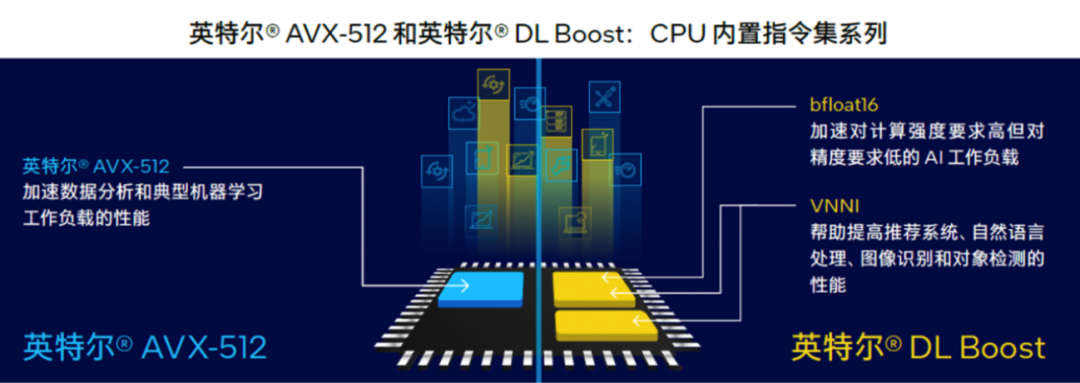
第二阶段,也就是现阶段,针对矩阵运算优化。
所以从第四代至强® 可扩展处理器开始,内置AI加速技术的主角换成了英特尔® 高级矩阵扩展(英特尔® AMX)。它特别针对深度学习模型最常见的矩阵乘法运算优化,支持BF16(训练/推理)和INT8(推理)等常见数据类型。
英特尔® AMX主要由两个组件组成:专用的Tile寄存器存储大量数据,配合TMUL加速引擎执行矩阵乘法运算。有人把它比作内置在CPU里的Tensor Core,嗯,确实很形象。
这么一搞,它不仅做到在单个操作中计算更大的矩阵,还保证了可扩展性和可伸缩性。
英特尔® AMX在至强® CPU每个内核上并靠近系统内存,这样一来可减少数据传输延迟、提高数据传输带宽,实际使用上的复杂性也降低了。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

