

这次Pi币真的上线主网了!
文章来源:AI科技大本营
作者 | 王启隆
出品 | CSDN(ID:CSDNnews)
数据是当前火爆全球的 AI 大模型至关重要的一环,有人把数据比作大模型的“血液”,而预训练数据的数量、质量、多样性是大模型能力表现的关键性因素。正因如此,很多人(曾)一度认为坐拥海量数据并孵化出 Google Brain 的谷歌公司会成为 AI 时代的领头羊。
昨晚,大数据和 AI 公司 Databricks 宣布开源他们的 132B 大模型 DBRX。目前,DBRX 的基础 (DBRX Base) 和微调 (DBRX Instruct) 版本皆允许在 GitHub 和 Hugging Face 上用于研究和商业用途,并且可以在公共、自定义或其他专有数据上运行和调整。
GitHub:
https://github.com/databricks/dbrx
Hugging Face 链接:
https://huggingface.co/databricks/dbrx-base(基础版)
https://huggingface.co/databricks/dbrx-instruct (微调版)

Databricks 源自加州大学伯克利分校的 AMPLab 项目,致力于研发一款基于 Scala 构建的开源分布式计算框架 Apache Spark。所谓的“湖仓一体”(data Lakehouse)就是这家公司首创的概念。2023 年 3 月的时候,Databricks 就跟着 ChatGPT 的风推出了开源语言模型 dolly,并在后续的 2.0 版本打出了「首个真正开放和商业可行的指令调优 LLM(大模型)」的口号。
所以,这是 Databricks 的「第二次搅局」。
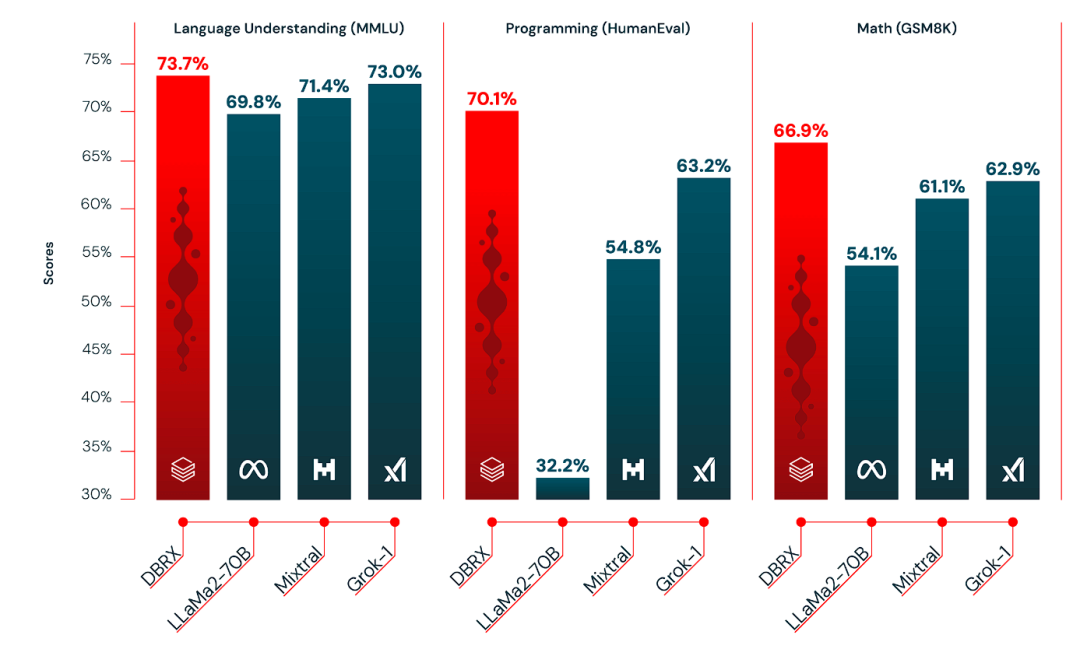
这一次发布的 DBRX 耗时两个月、投入约 1000 万美元训练打造,宣称“超越了 GPT-3.5,与 Gemini 1.0 Pro 具有竞争力,在编程方面超越了 CodeLLaMA-70B 等专业模型”。Databricks 的首席神经网络架构师 & DBRX 团队负责人 Jonathan Frankle 还直接在 X 上放话:“树立开源 LLM 的新标准!”
Jonathan Frankle 曾经是生成式 AI 初创公司 MosaicML 的首席科学家,而 Databricks 在 2023 年 6 月以 14 亿美元的大手笔收购了 MosaicML,这一举动还让 Frankle 辞掉了哈佛大学的教授工作,专心开发 DBRX。
马斯克意气风发的宣告 3140 亿史上最大开源模型 Grok-1 诞生,这事就发生在 10 天前,还令人历历在目。难不成 DBRX 真的就这么轻松击溃了 LLaMA 和 Grok 两大开源模型?背景已经介绍完毕,下面我们就来看看 DBRX 的详细情况。

树立开源新标准?
首先,万物基于 Transformer,DBRX 也不例外。
除此之外,DBRX 还是一个混合专家模型(MoE),总计 1320 亿(132 B)参数,在 12T 文本和代码数据 tokens 上进行预训练。MoE 架构引入了一种模块化的体系结构,从一个巨大的神经网络里分解出多个子网络(“专家网络”)协同工作,处理输入数据。
相比法国的 Mixtral 和 Grok-1 等其他开源 MoE 模型,DBRX 有个“独门绝学”:它配置了 16 个专家网络,从中选择 4 个参与运算,并且仅使用 360 亿 的参数。(Mixtral 和 Grok-1 则各有 8 个专家网络,选择其中 2 个参与)
Databricks 还发现,这种改进能有效提升模型质量。
不过 DBRX 和 Grok-1 有一个同款的毛病:贵。Databricks 在这两个月用了 3072 张 NVIDIA H100 GPU 训练 DBRX,而用户如果想在标准配置中运行 DBRX,则需要一台至少配备四张 H100(或 320GB 显存的任何其他 GPU 配置)的服务器或 PC。
在推理速度上,DBRX 比 LLaMA2-70B 快约 2 倍;从参数总数和激活参数数来看,DBRX 大约只有 Grok-1 的 40% 大小。Databricks 也提供了 API 服务,在 8 位量化(8-bit quantization)的情况下,DBRX 预计可以每秒处理高达 150 个 tokens 的吞吐量。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

