

这次Pi币真的上线主网了!
文章来源:机器之心
 图片来源:由无界AI生成
图片来源:由无界AI生成
Open-Sora 在开源社区悄悄更新了,现在单镜头支持长达16秒的视频生成,分辨率最高可达720p,并且可以处理任何宽高比的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的生成需求。我们来试试效果。
生成个横屏圣诞雪景,发b站

再生成个竖屏,发抖音

还能生成单镜头16秒的长视频,这下人人都能过把编剧瘾了

怎么玩?指路
GitHub:https://github.com/hpcaitech/Open-Sora
更酷的是,Open-Sora 依旧全部开源,包含最新的模型架构、最新的模型权重、多时间/分辨率/长宽比/帧率的训练流程、数据收集和预处理的完整流程、所有的训练细节、demo示例和详尽的上手教程。
Open-Sora 技术报告全面解读
最新功能概览
作者团队在GitHub上正式发布了Open-Sora 技术报告[1],根据笔者的了解,本次更新主要包括以下几项关键特性:
支持长视频生成; 视频生成分辨率最高可达720p; 单模型支持任何宽高比,不同分辨率和时长的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的生成需求; 提出了更稳定的模型架构设计,支持多时间/分辨率/长宽比/帧率训练; 开源了最新的自动数据处理全流程。时空扩散模型ST-DiT-2
作者团队表示,他们对Open-Sora 1.0中的STDiT架构进行了关键性改进,旨在提高模型的训练稳定性和整体性能。针对当前的序列预测任务,团队采纳了大型语言模型(LLM)的最佳实践,将时序注意力中的正弦波位置编码(sinusoidal positional encoding)替换为更加高效的旋转位置编码(RoPE embedding)。此外,为了增强训练的稳定性,他们参考SD3模型架构,进一步引入了QK归一化技术,以增强半精度训练的稳定性。为了支持多分辨率、不同长宽比和帧率的训练需求,作者团队提出的ST-DiT-2架构能够自动缩放位置编码,并处理不同大小尺寸的输入。
多阶段训练
根据Open-Sora 技术报告指出,Open-Sora 采用了一种多阶段训练方法,每个阶段都会基于前一个阶段的权重继续训练。相较于单一阶段训练,这种多阶段训练通过分步骤引入数据,更高效地实现了高质量视频生成的目标。
初始阶段大部分视频采用144p分辨率,同时与图片和 240p,480p 的视频进行混训,训练持续约1周,总步长81k。第二阶段将大部分视频数据分辨率提升至240p和480p,训练时长为1天,步长达到22k。第三阶段进一步增强至480p和720p,训练时长为1天,完成了4k步长的训练。整个多阶段训练流程在约9天内完成,与Open-Sora1.0相比,在多个维度提升了视频生成的质量。
统一的图生视频/视频生视频框架
作者团队表示,基于Transformer的特性,可以轻松扩展 DiT 架构以支持图像到图像以及视频到视频的任务。他们提出了一种掩码策略来支持图像和视频的条件化处理。通过设置不同的掩码,可以支持各种生成任务,包括:图生视频,循环视频,视频延展,视频自回归生成,视频衔接,视频编辑,插帧等。
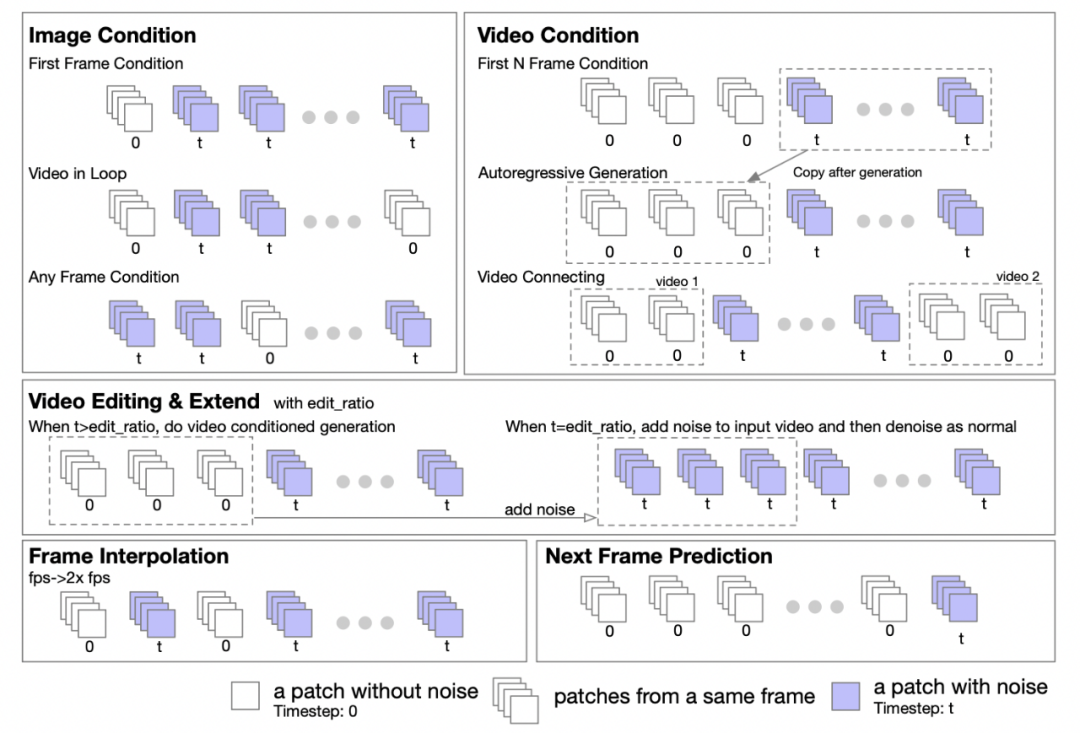 支持图像和视频条件化处理的掩码策略
支持图像和视频条件化处理的掩码策略
作者团队表示,受到UL2[2]方法的启发,他们在模型训练阶段引入了一种随机掩码策略。具体而言,在训练过程中以随机方式选择并取消掩码的帧,包括但不限于取消掩码第一帧、前k帧、后k帧、任意k帧等。作者还向我们透露,基于Open-Sora 1.0的实验,应用50%的概率应用掩码策略时,只需少量步数模型能够更好地学会处理图像条件化。在Open-Sora 最新版本中,他们采用了从头开始使用掩码策略进行预训练的方法。
此外,作者团队还贴心地为推理阶段提供了掩码策略配置的详细指南,五个数字的元组形式在定义掩码策略时提供了极大的灵活性和控制力。
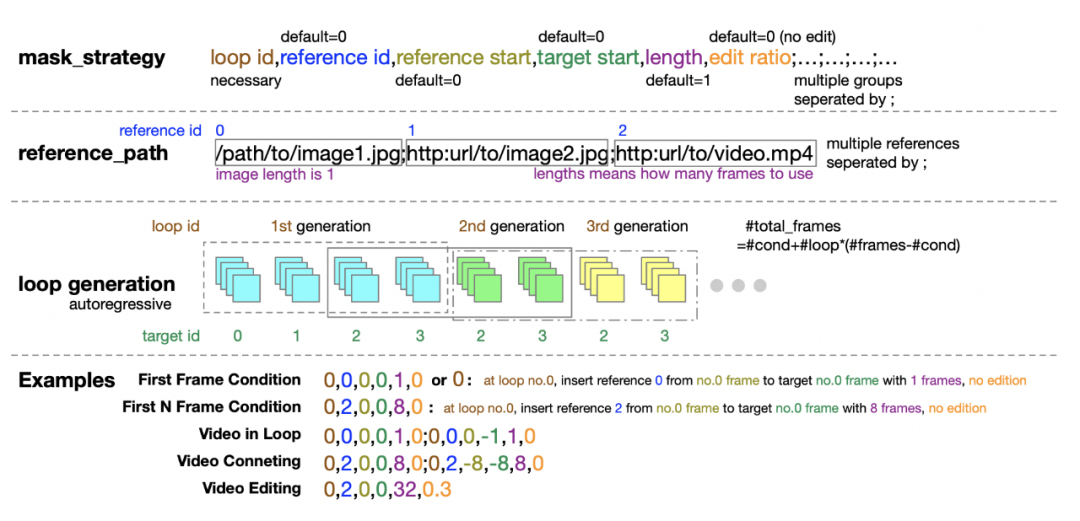 掩码策略配置说明
掩码策略配置说明
支持多时间/分辨率/长宽比/帧率训练
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

