

这次Pi币真的上线主网了!
文章来源:机器之心
来源:节选自 2024 年 Week04 业内通讯
 图片来源:由无界AI生成
图片来源:由无界AI生成
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。
2024年初,Meta和纽约大学等机构的研究者提出了一项「自我奖励方法」,可以让大模型自己生成自己的微调数据。研究者对 Llama 2 70B 进行了三个迭代的微调,其生成的模型在 AlpacaEval 2.0 排行榜上优于 Claude 2、Gemini Pro 和 GPT-4 等现有大模型。
奖励模型能干什么?
大型语言模型通过以逐步思考链格式生成解决方案,解决需要复杂多步推理的任务。许多研究关注如何检测和减少幻觉对于提高推理能力。其中,通过训练奖励模型以区分期望的和不期望的输出则是一种有效的方法,奖励模型可以用于强化学习流程或通过拒绝采样进行搜索。如何有效地训练可靠的奖励模型至关重要。
OpenAI 提出了人类反馈强化学习 (RLHF) 的标准方法在 ChatGPT 发布时引起极大关注。该技术模型可以从人类偏好中学习奖励模型,再冻结奖励模型并结合强化学习训练 LLM。通过使用人类偏好数据调整大语言模型(LLM)可以提高预训练模型的指令跟踪性能。但 RLHF 存在依赖人类反馈的局限性。
在此背景下,Meta 提出的「自我奖励语言模型」(Self-Rewarding Language Models, SRLMs)是一种新型的语言模型,在训练过程中利用自身生成的反馈来自我提升。自我奖励语言模型不是被冻结,而是在 LLM 调整期间不断更新,避免了冻结奖励模型质量的瓶颈。
自我奖励模型的核心思路是什么?对比传统奖励模型有什么优势?自我奖励语言模型(SRLMs)的核心思想在于创建一个智能体,该智能体在训练期间集成了所需的全部能力,而非将任务分离为奖励模型和语言模型。这种方法允许通过多任务训练实现任务迁移,从而在预训练和后续训练中跟随指令并生成响应。
Meta 等提出的自我奖励模型具备双重角色:一方面,它遵循模型的指令来生成给定提示的响应;另一方面,它也能够根据示例生成和评估新的指令,进而将其添加到训练集中。该模型建立在假设之上,即利用基础的预训练语言模型和少量的人工注释数据,可以创建一个同时具备指令遵循和自指令创建能力的模型。
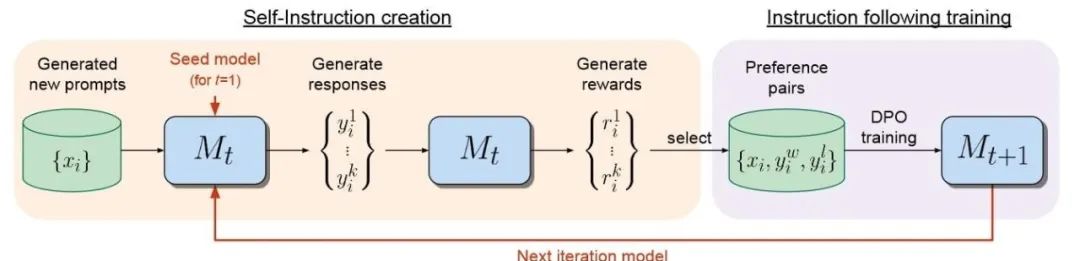
图:自我奖励语言模型的对齐方法含两个步骤,(i)自指令创建:新创建的提示用于从模型 Mt 生成候选响应,该模型还通过“LLM作为法官”提示预测自己的奖励。(ii)指令遵循训练:从生成的数据中选择偏好对,这些对用于通过DPO(确定性策略梯度)进行训练,从而产生模型 Mt+1。然后可以迭代整个程序,从而提高指令遵循和奖励建模能力。
这种自对齐能力使得模型能够使用人工智能反馈(AIF)进行迭代训练,提升自身组件的性能。自我奖励模型的一个关键特点是其自指令创建机制,它不仅生成候选响应,还自行评估这些响应的质量,充当自身的奖励模型,从而减少了对外部模型的依赖。这一过程通过“LLM-as-a-Judge”机制实现,即将响应评估任务转化为指令遵循任务,而模型自身创建的 AIF 偏好数据则被用作训练集。
在微调阶段,模型同时扮演“学习者”和“法官”的角色,通过上下文微调进一步提升性能。整个过程是一个迭代的自对齐过程,通过构建一系列逐渐改进的模型来实现。
与传统的固定奖励模型不同,自我奖励模型在语言模型对齐过程中不断更新,从而避免了发展瓶颈,并提高了模型自我改进的潜力。相较于传统奖励模型,自我奖励模型的优势在于其动态性和自我迭代的能力。它通过整合奖励模型到同一系统中,实现了任务迁移,允许奖励建模任务和指令遵循任务相互促进和提升。
自我奖励模型和 RLAIF 有关联吗?
RLAIF(Reinforcement Learning from AI Feedback)与自我奖励模型在思路上存在明显差异。RLAIF 采用了 AI 反馈强化学习的方法,使用 AI 而非人类来进行偏好标注,以此扩展强化学习的规模。具体来说,RLAIF 利用 LLM 生成的偏好标签来训练奖励模型(RM),随后使用该 RM 提供奖励以进行强化学习。
Anthropic 在 2022 年 12 月发布的论文《Constitutional AI: Harmlessness from AI Feedback》中首次提出了 RLAIF 的概念,并发现 LLM 在某些任务上的表现甚至可以超越人类。而在 2023 年 9 月,谷歌发表的论文《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》进一步推动了 RLAIF 方法的发展。
RLAIF 的关键步骤之一是使用 LLM 来标记偏好。研究者利用现成的 LLM 在成对的候选项中标记偏好,例如,给定一段文本和两个候选摘要,LLM 的任务是评判哪个摘要更为优秀。这种方法不仅提高了训练效率,还解决了传统 RLHF(Reinforcement Learning from Human Feedback)中因人类标注成本高昂和规模受限的问题。
RLAIF 通过 AI 反馈来增强强化学习的能力,使得模型能够处理更大规模的数据集,同时降低了对人类标注的依赖。这种方法为训练更高效、更大规模的语言模型提供了新的可能性,并有助于推动自然语言处理领域的进一步发展。
使用 AI 合成数据训模型有风险吗?最近还有谁正在做AI自我迭代?小模型监督大模型的方法好用吗?
目前,模型训练大部分的数据来自于互联网,如 Twitter、GitHub、Arxiv、Wikipedia、Reddit 等网站。随着模型的规模继续增大,人们需要投喂更多的数据来训练模型。在使用模型生成的数据来训练新模型时,会产生「哈布斯堡诅咒」或称「模型自噬」现象......
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

