

这次Pi币真的上线主网了!
编译:Kate,火星财经
在过去的两年中,STARK 已经成为一种关键且不可替代的技术,可以有效地对非常复杂的语句进行易于验证的加密证明(例如,证明以太坊区块是有效的)。
其中一个关键原因是字段大小:基于椭圆曲线的 SNARK 要求您在 256 位整数上工作才能足够安全,而 STARK 允许您使用更小的字段大小,效率更高:首先是 Goldilocks 字段(64 位整数),然后是 Mersenne31 和 BabyBear(均为 31 位)。由于这些效率的提高,使用 Goldilocks 的 Plonky2 在证明多种计算方面比其前辈快数百倍。
一个自然而然的问题是:我们能否将这一趋势引向合乎逻辑的结论,通过直接在零和一上操作来构建运行速度更快的证明系统?这正是 Binius 试图做的事情,使用了许多数学技巧,使其与三年前的 SNARK 和 STARK 截然不同。这篇文章介绍了为什么小字段使证明生成更有效率,为什么二进制字段具有独特的强大功能,以及 Binius 用来使二进制字段上的证明如此有效的技巧。
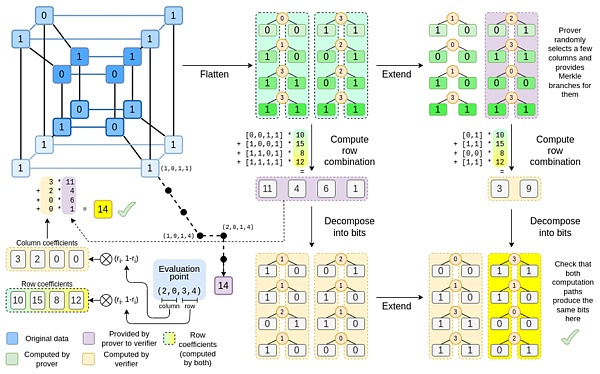
△ Binius。在这篇文章的最后,你应该能够理解此图的每个部分。
回顾:有限域(finite fields)
加密证明系统的关键任务之一是对大量数据进行操作,同时保持数字较小。如果你可以将一个关于大型程序的语句压缩成一个包含几个数字的数学方程,但是这些数字与原始程序一样大,那么你将一无所获。
为了在保持数字较小的情况下进行复杂的算术,密码学家通常使用模运算 (modular arithmetic)。我们选择一个质数「模数」p。% 运算符的意思是「取余数」:15%7=1,53%10=3,等等。(请注意,答案总是非负数的,所以例如 -1%10=9)
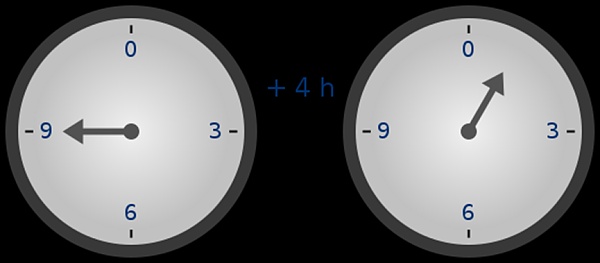
你可能已经在时间的加减上下文中见过模运算 ( 例如,9 点过 4 小时是几点?但在这里,我们不只是对某个数进行加、减模,我们还可以进行乘、除和取指数。
我们重新定义:
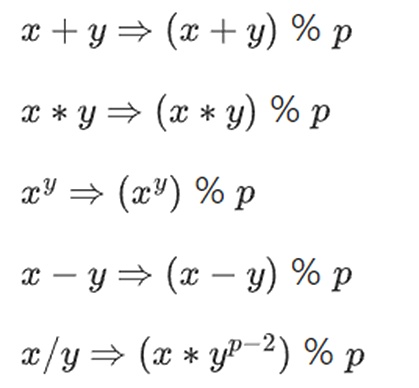
以上规则都是自洽的。例如,如果 p=7,那么:
5+3=1(因为 8%7=1)
1-3=5(因为 -2%7=5)
2*5=3
3/5=2
这种结构的更通用术语是有限域。有限域是一种数学结构,它遵循通常的算术法则,但其中可能的值数量有限,因此每个值都可以用固定的大小表示。
模运算 ( 或质数域 ) 是有限域最常见的类型,但也有另一种类型:扩展域。你可能已经见过一个扩展字段:复数。我们「想象」一个新元素,并给它贴上标签 i,并用它进行数学运算:(3i+2)*(2i+4)=6i*i+12i+4i+8=16i+2。我们可以同样地取质数域的扩展。当我们开始处理较小的字段时,质数字段的扩展对于保护安全性变得越来越重要,而二进制字段 (Binius 使用 ) 完全依赖于扩展以具有实际效用。
回顾:算术化
SNARK 和 STARK 证明计算机程序的方法是通过算术:你把一个关于你想证明的程序的陈述,转换成一个包含多项式的数学方程。方程的有效解对应于程序的有效执行。
举个简单的例子,假设我计算了第 100 个斐波那契数,我想向你证明它是什么。我创建了一个编码斐波那契数列的多项式 F:所以 F(0)=F(1)=1、F(2)=2、F(3)=3、F(4)=5 依此类推,共 100 步。我需要证明的条件是 F(x+2)=F(x)+F(x+1) 在整个范围内 x={0,1…98}。我可以通过给你商数来说服你:
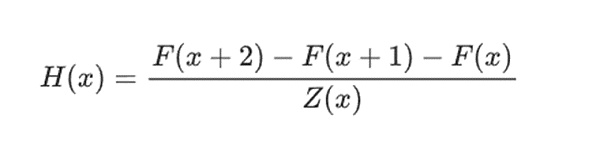
其中 Z(x) = (x-0) * (x-1) * …(x-98)。.如果我能提供有 F 且 H 满足此等式,则 F 必须在该范围内满足 F(x+2)-F(x+1)-F(x)。如果我另外验证满足 F,F(0)=F(1)=1,那么 F(100) 实际上必须是第 100 个斐波那契数。
如果你想证明一些更复杂的东西,那么你用一个更复杂的方程替换「简单」关系 F(x+2) = F(x) + F(x+1),它基本上是说「F(x+1) 是初始化一个虚拟机的输出,状态是 F(x)」,并运行一个计算步骤。你也可以用一个更大的数字代替数字 100,例如,100000000,以容纳更多的步骤。
所有 SNARK 和 STARK 都基于这种想法,即使用多项式 ( 有时是向量和矩阵 ) 上的简单方程来表示单个值之间的大量关系。并非所有的算法都像上面那样检查相邻计算步骤之间的等价性:例如,PLONK 没有,R1CS 也没有。但是许多最有效的检查都是这样做的,因为多次执行相同的检查 ( 或相同的少数检查 ) 可以更轻松地将开销降至最低。
Plonky2:从 256 位 SNARK 和 STARK 到 64 位......只有 STARK
五年前,对不同类型的零知识证明的合理总结如下。有两种类型的证明:( 基于椭圆曲线的 )SNARK 和 ( 基于哈希的 )STARK。从技术上讲,STARK 是 SNARK 的一种,但在实践中,通常使用「SNARK」来指代基于椭圆曲线的变体,而使用「STARK」来指代基于哈希的结构。SNARK 很小,因此你可以非常快速地验证它们并轻松地将它们安装在链上。STARK 很大,但它们不需要可信的设置,而且它们是抗量子的。
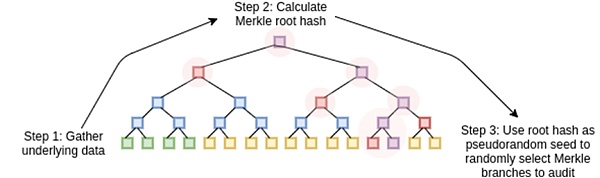
△ STARK 的工作原理是将数据视为多项式,计算该多项式的计算,并使用扩展数据的默克尔根作为「多项式承诺」。
这里的一个关键历史是,基于椭圆曲线的 SNARK 首先得到了广泛的使用:直到 2018 年左右,STARK 才变得足够高效,这要归功于 FRI,而那时 Zcash 已经运行了一年多。基于椭圆曲线的 SNARK 有一个关键的限制:如果你想使用基于椭圆曲线的 SNARK,那么这些方程中的算术必须使用椭圆曲线上的点数模数来完成。这是一个很大的数字,通常接近 2 的 256 次方:例如,bn128 曲线为 21888242871839275222246405745257275088548364400416034343698204186575808495617。但实际的计算使用的是小数字:如果你用你最喜欢的语言来考虑一个「真正的」程序,它使用的大部分东西是计数器,for 循环中的索引,程序中的位置,代表 True 或 False 的单个位,以及其他几乎总是只有几位数长的东西。
即使你的「原始」数据由「小」数字组成,证明过程也需要计算商数、扩展、随机线性组合和其他数据转换,这将导致相等或更大数量的对象,这些对象的平均大小与你的字段的全部大小一样大。这造成了一个关键的低效率:为了证明对 n 个小值的计算,你必须对 n 个大得多的值进行更多的计算。起初,STARK 继承了 SNARK 使用 256 位字段的习惯,因此也遭受了同样的低效率。

△ 一些多项式求值的 Reed-Solomon 扩展。尽管原始值很小,但额外的值都将扩展到字段的完整大小 ( 在本例中是 2 的 31 次方 -1)
2022 年,Plonky2 发布。Plonky2 的主要创新是对一个较小的质数进行算术取模:2 的 64 次方 – 2 的 32 次方 + 1 = 18446744067414584321。现在,每次加法或乘法总是可以在 CPU 上的几个指令中完成,并且将所有数据哈希在一起的速度比以前快 4 倍。但这有一个问题:这种方法只适用于 STARK。如果你尝试使用 SNARK,对于如此小的椭圆曲线,椭圆曲线将变得不安全。
为了保证安全,Plonky2 还需要引入扩展字段。检查算术方程的一个关键技术是「随机点抽样」:如果你想检查的 H(x) * Z(x) 是否等于 F(x+2)-F(x+1)-F(x),你可以随机选择一个坐标 r,提供多项式承诺开证明证明 H(r)、Z(r) 、F(r),F(r+1) 和 F(r+2),然后进行验证 H(r) * Z(r) 是否等于 F(r+2)-F(r+1)- F(r)。如果攻击者可以提前猜出坐标,那么攻击者就可以欺骗证明系统——这就是为什么证明系统必须是随机的。但这也意味着坐标必须从一个足够大的集合中采样,以使攻击者无法随机猜测。如果模数接近 2 的 256 次方,这显然是事实。但是,对于模数量是 2 的 64 次方 -2 的 32 次方 +1,我们还没到那一步,如果我们降到 2 的 31 次方 -1,情况肯定不是这样。试图伪造证明 20 亿次,直到一个人幸运,这绝对在攻击者的能力范围内。
为了阻止这种情况,我们从扩展字段中采样 r,例如,你可以定义 y,其中 y 的 3 次方=5,并采用 1、y、y 的 2 次方的组合。这将使坐标的总数增加到大约 2 的 93 次方。证明者计算的多项式的大部分不进入这个扩展域;只是用整数取模 2 的 31 次方 -1,因此,你仍然可以从使用小域中获得所有的效率。但是随机点检查和 FRI 计算确实深入到这个更大的领域,以获得所需的安全性。
从小质数到二进制数
计算机通过将较大的数字表示为 0 和 1 的序列来进行算术运算,并在这些 bit 之上构建「电路」来计算加法和乘法等运算。计算机特别针对 16 位、32 位和 64 位整数进行了优化。例如,2 的 64 次方 -2 的 32 次方 +1 和 2 的 31 次方 -1,选择它们不仅是因为它们符合这些界限,还因为它们与这些界限很吻合:可以通过执行常规的 32 位乘法来执行乘法取模 2 的 64 次方 -2 的 32 次方 +1,并在几个地方按位移位和复制输出;这个文章很好地解释了一些技巧。
然而,更好的方法是直接用二进制进行计算。如果加法可以「只是」异或,而无需担心「携带」从一个位添加 1 + 1 到下一个位的溢出?如果乘法可以以同样的方式更加并行化呢?这些优点都是基于能够用一个 bit 表示真 / 假值。
获取直接进行二进制计算的这些优点正是 Binius 试图做的。Binius 团队在 zkSummit 的演讲中展示了效率提升:
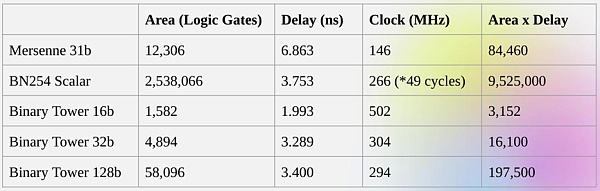
尽管「大小」大致相同,但 32 位二进制字段操作比 31 位 Mersenne 字段操作所需的计算资源少 5 倍。
从一元多项式到超立方体
假设我们相信这个推理,并且想要用 bit(0 和 1) 来做所有的事情。我们如何用一个多项式来表示十亿 bit 呢?
在这里,我们面临两个实际问题:
对于一个表示大量值的多项式,这些值需要在多项式的求值时可以访问:在上面的斐波那契例子中,F(0),F(1) … F(100),在一个更大的计算中,指数会达到数百万。我们使用的字段需要包含到这个大小的数字。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

