

这次Pi币真的上线主网了!
文章来源:硬AI
AI“快进”到价格战阶段?从Deepseek-V2定价看大模型降本新风向
 图片来源:由无界AI生成
图片来源:由无界AI生成
卷价格的风还是吹到了AI大模型。
近日,大模型DeepSeek-V2将每百万tokens输入/输出价格分别卷至1/2元,远低于行业平均水平。
对此,华福证券发布报告称,大模型成本优化与算力需求并不是直接的此长彼消,而是互相搭台、相互成就。定价的持续走低有望带来更快的商业化落地,进而会衍生出更多的微调及推理等需求,将逐步盘活国内AI应用及国产算力发展。
DeepSeek-V2是知名私募巨头幻方量化旗下AI公司深度求索(DeepSeek)发布的全新第二代MoE大模型。
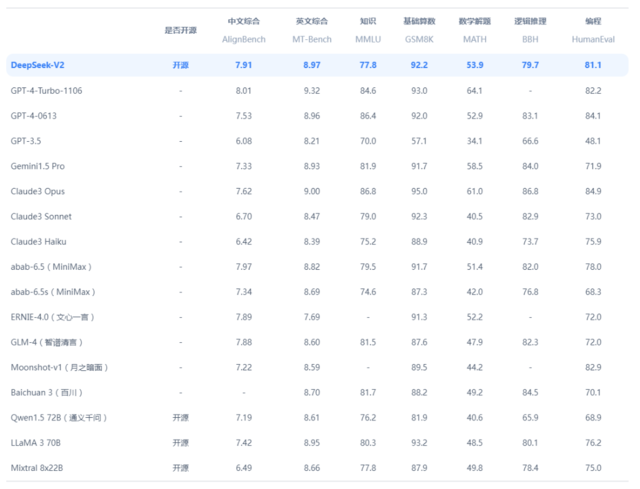
华尔街见闻此前文章提到,DeepSeek-V2拥有2360亿参数,其中每个token210亿个活跃参数,相对较少,但仍然达到了开源模型中顶级的性能。
华福证券则在报告中写道,从综合性能方面来看,DeepSeek-V2位列第一梯队。在AlignBench、MT-Bench、MMLU等多个benchmark上表现出色,其中AlignBench在开源模型中居首位,与GPT-4-Turbo,文心4.0比肩。MTBench超过最强MoE开源模型Mixtral 8x22B。
01
DeepSeek-V2定价将至冰点
大模型价格战拉开序幕
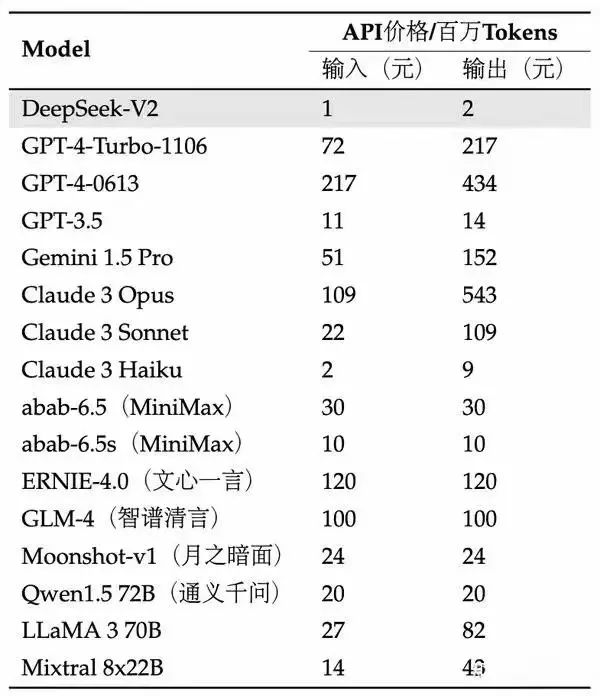
DeepSeek-V2(32k)每百万tokens输入/输出价格分别为1/2元,而GPT-4-Turbo-1106分别为72/217元,DeepSeek-V2性价比显著。
相对于Claude 3 Haiku,DeepSeek-V2每百万tokens输入/输出价格也仅为其50%/22.2%。除此之外,同为32k上下文版本的moonshot-v1、SenseChat-32K、Qwen1.5 72B每百万tokens输入/输出价格分别为24/24、36/36、20/20元。
DeepSeek表示,采用8xH800 GPU的单节点峰值吞吐量可达到每秒50000多个解码token。如果仅按输出token的API的报价计算,每个节点每小时的收入就是50.4美元,假设利用率完全充分,按照一个8xH800节点的成本为每小时15美元来计算,DeepSeek每台服务器每小时的收益可达35.4美元,甚至能实现70%以上的毛利率。
有分析人士指出,即使服务器利用率不充分、批处理速度低于峰值能力,DeepSeek也有足够的盈利空间,同时颠覆其他大模型的商业逻辑。
华福证券也认为,此次DeepSeek-V2定价发布有望掀起新一轮大模型价格战,api定价有望持续走低。
02
大模型定价下降的背后离不开成本的优化
价格是怎么被打下去的?来自DeepSeek-V2的全新架构。
据悉,DeepSeek-V2采用Transformer架构,其中每个Transformer块由一个注意力模块和一个前馈网络(FFN)组成,并且在注意力机制和FFN方面,研究团队设计并采用了创新架构。
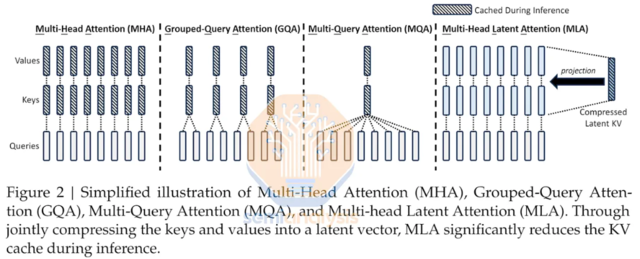
华福证券指出,目前众多大模型已经通过多种方式降低成本。
从模型压缩的方向看,可以通过量化的形式将浮点表征为低位宽模型来压缩模型存储空间,加速模型推理;从模型架构的方向看,MoE架构由于其内部的专家模型能够分配到不同设备,并可以执行并行计算,其计算效率较稠密模型显著提升,进而带来更低的成本。
从tokens量的方向来看,可以通过prompt压缩等方式直接降低输入端tokens,进而降低成本。除此之外,多种新的方案已出现在相关论文中,未来多种成本优化方案的融合将进一步加速模型成本的下降。
本文主要观点来自华福证券钱劲宇(执业证书编号:S0210524040006)5月9日发布的报告《计算机行业跟踪:从 Deepseek-V2 定价看大模型降本新风向》
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

