

这次Pi币真的上线主网了!
文章来源:夕小瑶科技说
作者 | Richard
 图片来源:由无界AI生成
图片来源:由无界AI生成
近年来,随着ChatGPT、Claude等大型对话模型相继问世,它们已经开始为数以百万计的用户提供服务。这些强大的AI助手可以与人进行流畅的多轮对话,完成写作、编程、分析等各种任务,展现出广阔的应用前景。然而目前公开的人机对话数据集大多由专家根据特定场景设计生成,与真实用户的自然交互存在差异,导致研究者难以深入了解用户与AI助手的实际交互模式。
最近,艾伦人工智能研究所发布了WildChat数据集,包含100万个真实用户与ChatGPT的对话。研究发现,WildChat涵盖编程、创意写作、数学等多样化主题,支持68种语言,并且用户提问和模型回复的平均长度超过现有数据集。值得关注的是,其中超10%对话涉及不当言论,为研究AI应对恶意输入提供了样本。此外,在WildChat上微调语言模型,可显著提升模型的多轮对话能力。
WildChat为对话AI研究提供了真实而丰富的数据。相信基于该数据集的进一步研究,将有助于打造更智能、安全、贴近用户的AI对话系统,推动人机交互技术发展。
论文标题:WildChat: 1M ChatGPT Interaction Logs in the Wild
论文链接:
https://arxiv.org/pdf/2405.01470
WildChat:对话AI研究的"游戏规则改变者"
不按套路出牌:野生数据打破AI对话固有模式
传统的人机对话数据集,如Alpaca、Dolly等,主要由专家根据特定场景设计问答对生成。这类数据虽然质量较高,但与真实用户的自然交互存在差距。用户在实际使用中的提问方式、语言风格、关注点往往更加多样化,而且对话往往是多轮互动,而非简单的一问一答。
WildChat的出现为对话AI研究带来了新的突破。这个数据集包含了100万个由真实用户与ChatGPT的多轮对话,总token数超过8亿,是目前最大的公开人机对话数据集之一。更重要的是,这些对话都是用户在实际使用中自然产生的,涵盖了编程、写作、数学、角色扮演等各种真实场景。
百万对话68种语言,AI话痨环游"数据"世界
WildChat的一大亮点是其语言的多样性。数据集中包含了68种语言的对话,从主流的英语、汉语,到小语种如斯瓦希里语等,覆盖了全球各地用户。这为研究多语言对话AI提供了宝贵的资源。通过分析不同语言用户的交互特点,可以设计更加本地化、个性化的对话策略。

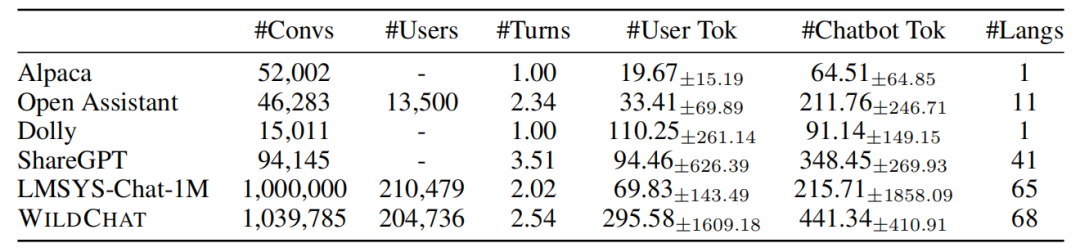
同时,WildChat在数据规模上也十分惊人。平均每个用户提问包含295个token,是Alpaca的15倍;每个AI回复则包含441个token,是Dolly的5倍。如此海量的数据,为训练更加强大的对话AI模型奠定了基础。下图展示了WildChat数据集和现有人机对话数据集之间的对比。
模型大乱斗!中美俄网友花样"调教"ChatGPT
WildChat数据集涵盖了不同版本的ChatGPT模型生成的数据,其中GPT-3.5系列模型占比约76%,GPT-4系列模型占比约24%。这为研究不同模型在真实场景下的表现差异提供了基础。

从地域分布来看,WildChat的用户主要来自美国、俄罗斯、中国等国家,反映了ChatGPT在全球范围内的受欢迎程度。不同国家和地区用户的交互模式可能存在差异,WildChat为研究这些差异提供了数据支持。

此外,WildChat还展现了对话主题的多样性。通过对英文对话的第一轮用户提问进行分析,研究者发现辅助/创意写作是最常见的对话目的,占比高达61.9%,其次是分析/决策解释(13.6%)和编程(6.7%)。这一分布有助于我们理解真实用户对话AI的主要使用场景和需求偏好。

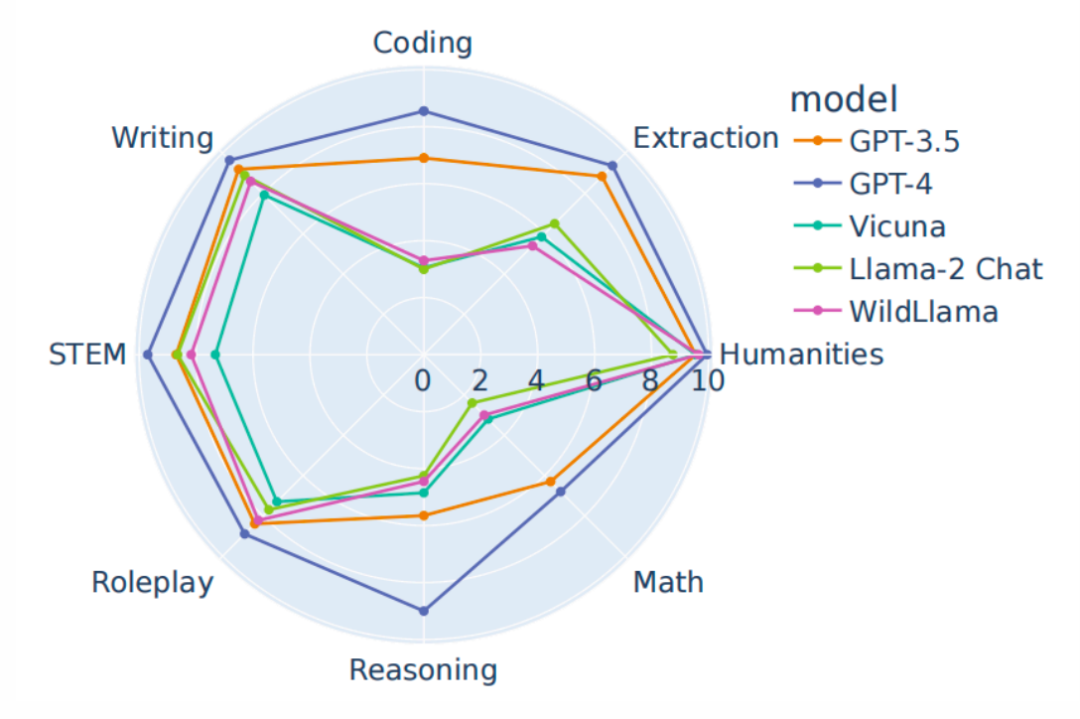
话痨用户VS话唠AI:巅峰对决谁怕谁?GPT家族内战再度升级!
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

