

MarsBit日报 | 基于Nostr的社
如今,数百万种 NFT、数万份 ERC-721 智能合约和数十个交易平台横跨多个区块链。结果,NFT 生态中到处都是噪音和碎片。无论你是刚入圈的收藏者还是经验丰富的加密老炮,想找到吸引人的新作品都不容易。但内容推荐并不是Web3所独有的问题。
多亏他们积累的数据、多年的测试和训练,像 Netflix 和 Spotify 之类的 Web2 公司已经精通了发现的艺术。但对 NFT 这种为「发现」带来独特新挑战的东西,他们的做法可以移植吗?
我在此研究了几种发现 NFT 的可选方法。
 图片由 Foundation.app 提供
图片由 Foundation.app 提供
1.跟踪数据
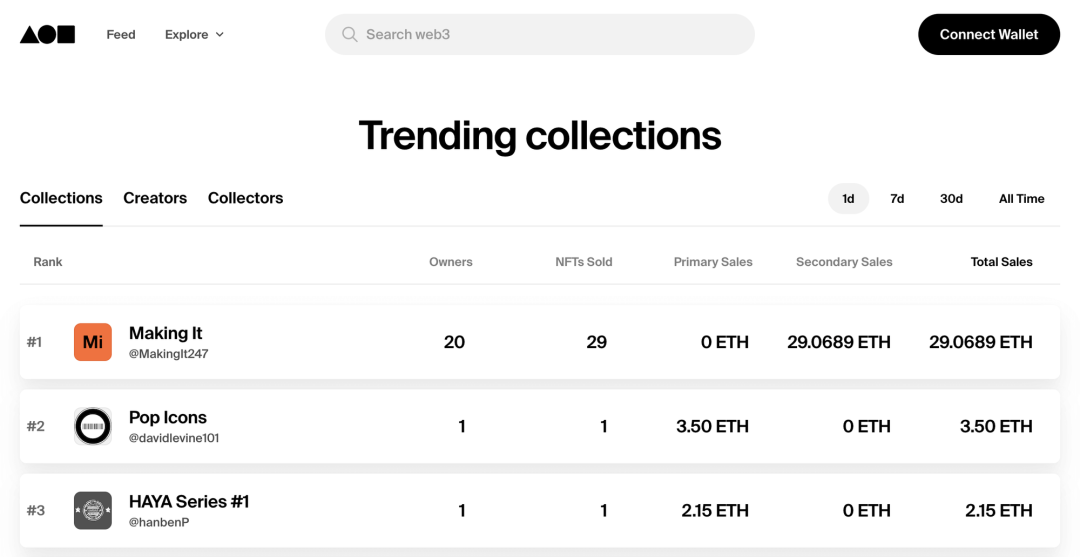
根据销量来发现 NFT 可能是最简单的方法。无论如何,排名和排行榜都是确定最流行收藏品的实用数据点。它们也是收藏者自然侧重的数据,这些人经常根据销量来进行筛选。这种做法的好处之一就是它有可验证性 —— 区块链数据轻易就能获取,通过运行以太坊节点,任何人都可以独立验证排名并亲自收集数据。
排行榜天生就是一个排序的机制,只是没有根据个人的喜好做微调。
毕竟,区块链数据让我们得以一窥艺术家和收藏者的复杂网络。网络科学家立刻意识到了 NFT 数据在揭示这种新兴所有权模式上的力量。
然而,刷量(收藏者通过把作品卖给自己来让它们看起来有销量并受人欢迎)仍然是 NFT 交易市场的棘手问题。一些独立加密研究者,比如 takenstheorem ,会通过可视化的方式呈现出相互交易的账号间的联系。
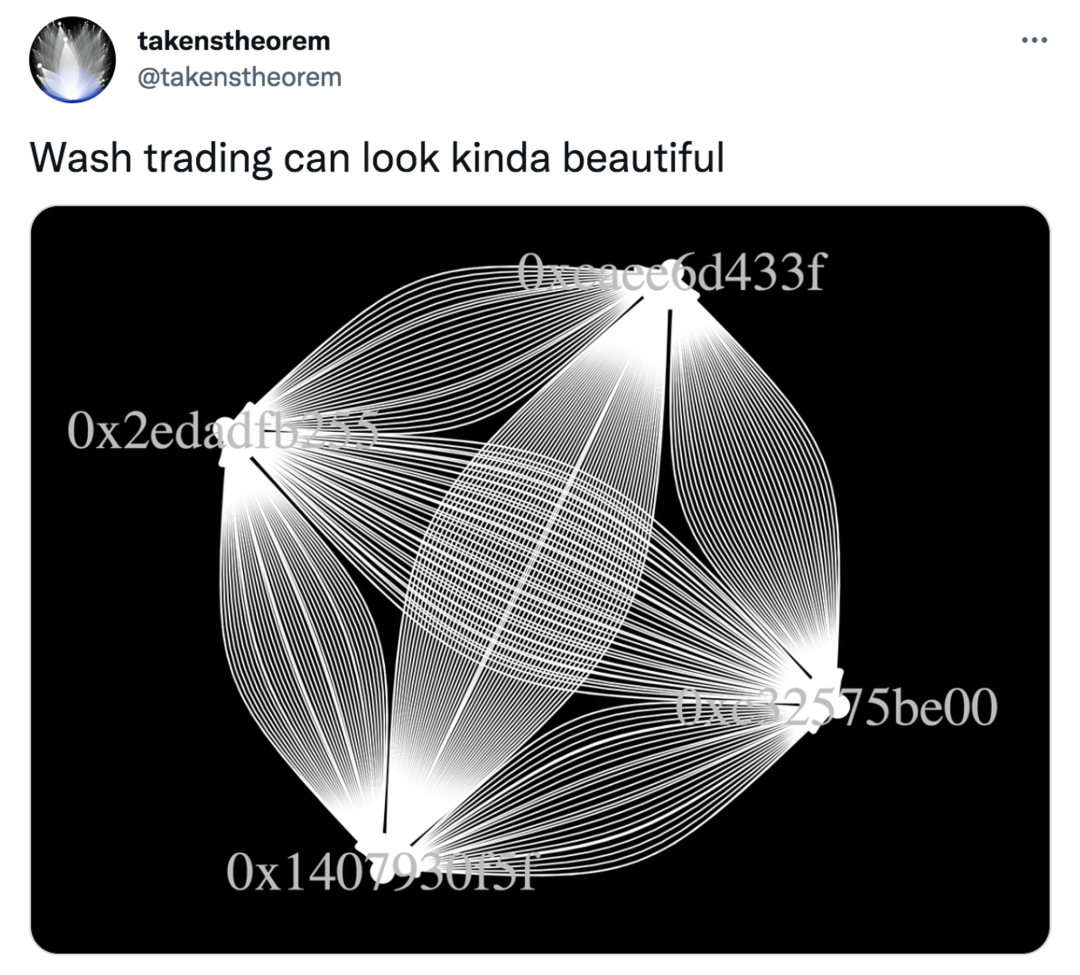 takenstheorem:刷量行为有时看着还挺漂亮
takenstheorem:刷量行为有时看着还挺漂亮
2.其他收藏者也喜欢
另一种发现 NFT 的方法是分析和你相似的收藏者。这种做法假设,如果两个收藏者拥有同一组艺术家的作品,那么他们就很可能就有着相似的品味,也许会从其中一人收藏而另一人没有收藏的艺术家那里发现新大陆。这用的是 Facebook「共同好友」的逻辑。
通过透明、分布式、实时的「谁拥有啥」的记录,区块链丰富的数据尤其适合做成网络分析图。任何时候 NFT 被转移,它的数据就被写入相关公链的公共账本,在两个加密钱包间建立起新的联系。这个数据随后就能被用于拓展收藏者的社交图谱。下图是我使用网络可视化工具分析 SuperRare 上 Jason Bailey 的收藏者网络。这个工具也可以把艺术家的收藏者社区可视化,所以我把生成艺术家 Manoloide 的社交图谱也加入进来。
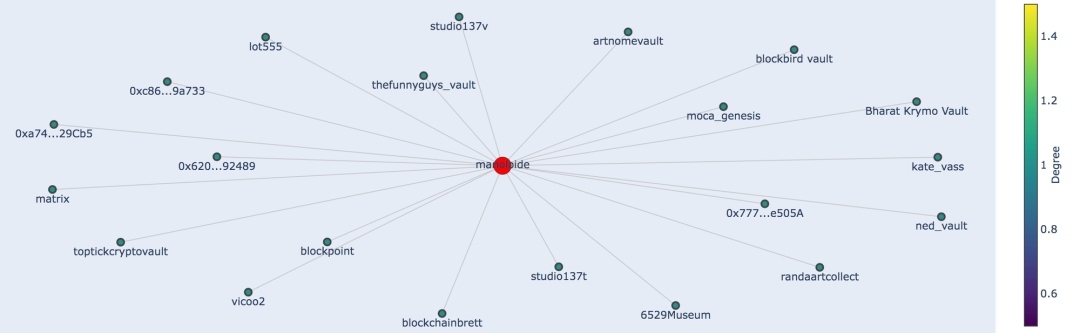 与 Jason Bailey (artnomevault) 和 Manoloide 有联系的 SuperRare 用户。2022 年 8 月 6 日的数据。由 Kyle Waters 提供
与 Jason Bailey (artnomevault) 和 Manoloide 有联系的 SuperRare 用户。2022 年 8 月 6 日的数据。由 Kyle Waters 提供
图一展示了 Jason 收藏的艺术家,图二展示了 Jason 在 SuperRare 上的「共同收藏者」, 他们共同的特征就在于拥有 Manoloide 创作的作品。如果我们放大 Manoloide 的某个收藏者,就能够搜寻 Jason 尚未收藏的艺术家。让我们以化名 punk6529 的收藏者的藏品 6529Museum 为例。下图展示了一大堆 Jason 可以考虑的新艺术家。基于这份网络分析,他可能会愿意了解一下 Seerlight。
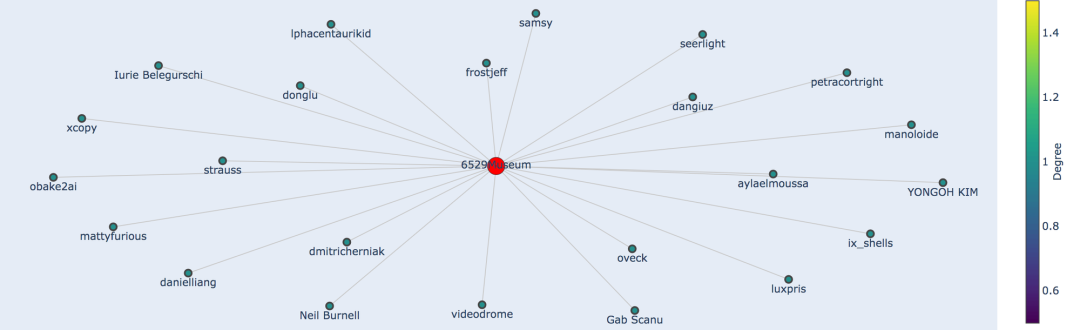 与 6529Museum 有联系的 SuperRare 用户。2022 年 8 月 6 日的数据。由 Kyle Waters 提供。
与 6529Museum 有联系的 SuperRare 用户。2022 年 8 月 6 日的数据。由 Kyle Waters 提供。
尽管这是个过度简化的大致模型,但它展示了这种基于网络的方法的力量。更精细的模型可能会基于 Jason 的共同收藏者中有多少人拥有某个特定艺术家的作品的准确数据来排名。将这种做法在多条链上拓展开来(比如以太坊和 Tezos),会需要把艺术家的钱包链接起来以掌握跨链出处的轨迹。
ClubNFT 的探索工具是第一个纯粹基于区块链网络数据做推荐的工具。然而,通过合并额外网络层、代币元数据甚至超越区块链本身,还有把该算法从当前范围进一步拓展的空间。
 Mario Klingemann、Hic et Nunc - State of the Art - 2021 年 3 月 18 日、2021年。由艺术家本人提供。
Mario Klingemann、Hic et Nunc - State of the Art - 2021 年 3 月 18 日、2021年。由艺术家本人提供。
3.给我更多这样的艺作
还有一种方法则是从 NFT 层面本身来处理这类问题。上图是艺术家 Mario Klingemann 于 2021 年 4 月所作,基于颜色相似度,他将来自 Tezos Hic Et Nunc 交易市场上的超过 25,000 份 NFT 汇集到了一起。还有很多高级计算机视觉技术 也能用来基于主题寻找好的匹配作品。
NFT 元数据(代币指向的任何信息块)也有可能给推荐帮上忙。对于加密艺术,元数据一般包括一个托管在 IPFS(星际文件传输系统)上的 JSON 文件。元数据通常包含标签、描述和其他与作品内容有关的属性。对这类元数据进行分析或许会帮助收藏者发现新作品。然而,没有清晰的标准会让这类信息的统一规范极其困难。
元数据能够提供详细的描述、标签和其他信息,但有时无法提供同样的信息丰富度,这可能削弱 Web3 推荐引擎的效力。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

