

NFT 玩家分析 | NFTGo 年报(
作者:Jacky Liang
编译:DeFi 之道

图片来源:由 Maze AI 生成
自 OpenAI 发布 ChatGPT 以来,已经过去几个月的时间了。这个基于大型语言模型的聊天机器人不仅让许多 AI 研究员大开眼界,还让大众见识到了 AI 的力量。简而言之,ChatGPT 是一个可以响应人类指令的聊天机器人,可以完成从写文章、作诗到解释和调试代码的任务。该聊天机器人显示出令人印象深刻的推理能力,其表现明显优于先前的语言模型。
在这篇文章中,我将从个人角度出发,聊聊 ChatGPT 对三类人的影响:分别是 AI 研究员、技术开发人员和普通大众。在文章中,我将推测 ChatGPT 等技术的影响,并简单聊聊我认为可能发生的一些情况。这篇文章更倾向于发表个人观点,而不是基于事实的报告,所以对这些观点要持谨慎态度。那么,让我们开始吧……
ChatGPT 之于 AI 研究员
对我这个 AI 研究员来说,从 ChatGPT 上学到的最重要的一课是:管理人类反馈对于提高大型语言模型 (LLM) 的性能非常重要。ChatGPT 改变了我,我猜也改变了许多研究人员对大型语言模型 AI 对齐问题的看法,我具体解释一下。
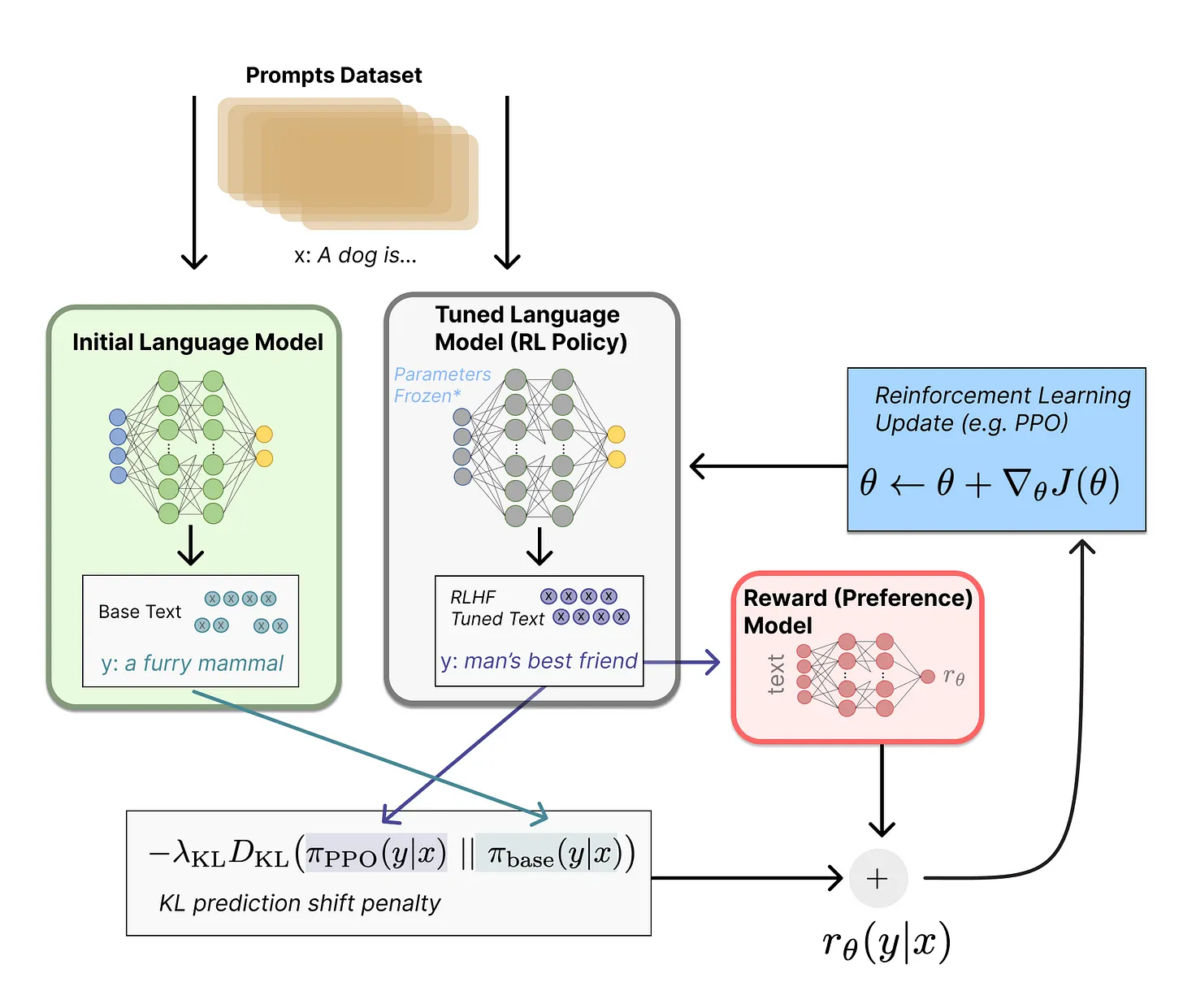
图:LLM 的强化学习与人的反馈(RLHF)
在 ChatGPT 问世之前,我想当然地认为,当涉及到 LLM 时,我们面临着两个不同的问题。1)提高 LLM 在某些基于语言的任务(如总结、问答、多步骤推理)中的表现,同时 2)避免有害的/破坏性的/有偏见的文本生成。我认为这两个目标是相关但独立的,并将第二个问题称为对齐问题。我从 ChatGPT 中了解到,对齐和任务表现其实是同一个问题,将 LLM 的输出与人类的意图对齐,既能减少有害内容,也能提高任务表现。
为了更方便理解,这里给出一些背景信息:我们可以将现代的 LLM 训练分为两个步骤。
在 ChatGPT 身上,OpenAI 很可能使用了许多不同的技术,相互配合来产生最终的模型。另外,OpenAI 似乎能够快速回应网上关于模型出错的投诉(例如产生有害的文本),有时甚至在几天内就能完成,所以他们也一定有办法修改/过滤模型的生成,而无需重新训练/微调模型。
ChatGPT 标志着强化学习(RL)的悄然回归。简而言之,有人类反馈的强化学习(RHLF)首先训练一个奖励模型,预测人类会给某一 LLM 生成内容打多高的分数,然后使用这个奖励模型通过 RL 来改善 LLM。
我不会在这里过多地讨论 RL,但 OpenAI 历来以其 RL 能力而闻名,他们写的 OpenAI gym 启动了 RL 研究,训练 RL 代理玩 DoTA,并以在数百万年的模拟数据上使用 RL 训练机器人玩魔方而闻名。在 OpenAI 解散其机器人团队之后,RL 似乎逐渐被 OpenAI 所遗忘,因为它在生成模型方面的成就主要来自于自我监督学习。ChatGPT 的成功依赖于 RLHF,它使人们重新关注 RL 作为改进 LLM 的实用方法。
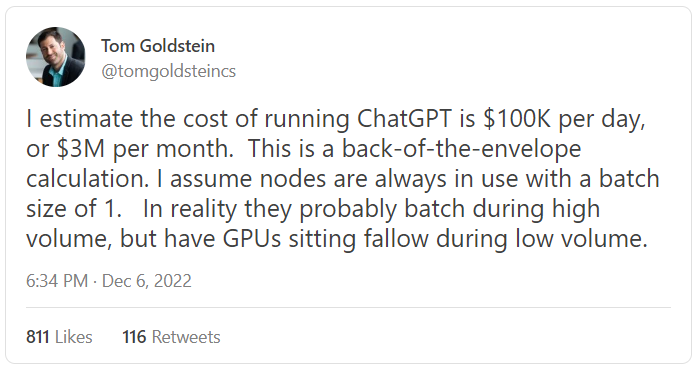
图:AI 专家预测 ChatGPT 的运行成本
ChatGPT 的到来还证明了一点:学术界开发大规模 AI 功能将越来越困难。虽然这个问题在整个深度学习时代都可能出现,但 ChatGPT 使它变得更加根深蒂固。不仅训练基本的 GPT-3 模型对小型实验室来说遥不可及(GPT-3 和随后 OpenAI 在微软将 Azure 的全部力量投入到它身上之后,建立了专门的服务器群和超级计算机才开始真正发展,这不是巧合),而且 ChatGPT 的数据收集和 RL 微调管道可能对学术实验室造成过大的系统/工程负担。
将 ChatGPT 免费提供给公众,可以让 OpenAI 收集更多宝贵的训练数据,这些数据对其未来的 LLM 改进至关重要。这样一来,公开托管 ChatGPT 实质上是 OpenAI 的大规模数据收集工作,而这不是小型组织能够承担的。
开源和与 HuggingFace 和 Stability 等公司在学术上的大规模合作可能是学术界目前前进的方式,但这些组织总是比拥有更大预算的小团队前进得慢。我推测,当涉及到最先进的语言模型时,开源通常会滞后于这些公司几个月到一年。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

