

开源竞速:AI大模型的“
来源:新智元
导读:ChatGPT为人诟病的「数学智障」问题,有望彻底攻克!OpenAI最新研究发现,利用「过程监督」可以大幅提升GPT模型的数学能力,干掉它们的幻觉。
ChatGPT自发布以来,数学能力饱受诟病。
就连「数学天才」陶哲轩曾表示,GPT-4在自己的数学专业领域,并没有太多的增值。
怎么办,就一直让ChatGPT做个「数学智障」么?
OpenAI在努力——为了提升GPT-4的数学推理能力,OpenAI团队用「过程监督」(PRM)训练模型。
让我们一步一步验证!

论文地址:https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
论文中,研究人员训练模型通过奖励每一个正确的推理步骤,即「过程监督」,而不仅仅是奖励正确的最终结果(结果监督),在数学问题解决方面取得最新SOTA。
具体来讲, PRM解决了MATH测试集代表性子集中78.2%的问题。

此外,OpenAI发现「过程监督」在对齐上有很大的价值——训练模型产生人类认可的思维链。
最新研究当然少不了Sam Altman的转发,「我们的Mathgen团队在过程监督上取得了非常令人振奋的结果,这是对齐的积极信号。」
在实践中,「过程监督」因为需要人工反馈,对于大模型和各种任务来说成本都极其高昂。因此,这项工作意义重大,可以说能够确定OpenAI未来的研究方向。
解决数学问题
实验中,研究人员用MATH数据集中的问题,来评估「过程监督」和「结果监督」的奖励模型。
让模型为每个问题生成许多解决方案,然后挑选每个奖励模型排名最高的解决方案。

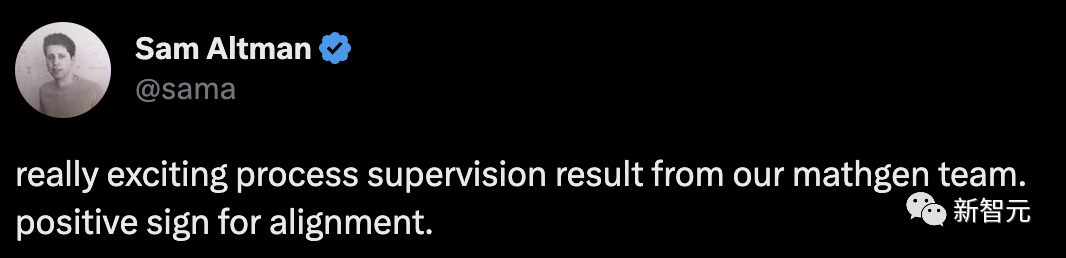
如图显示了所选解决方案中,取得正确最终答案的百分比,作为所考虑解决方案数量的函数。
「过程监督」奖励模型不仅在整体上表现更好,而且随着考虑每个问题的更多解决方案,性能差距也在扩大。
这表明,「过程监督」奖励模型更加可靠。
如下,OpenAI展示了模型的10个数学问题和解决方案,以及对奖励模型优缺点的评论。
从以下三类指标,真正(TP)、真负(TN)、假正(FP),对模型进行了评估。
真正(TP)
先来简化个三角函数公式。
这个具有挑战性的三角函数问题,需要以一种不明显的顺序应用几个恒等式。
但是大多数解决尝试都失败了,因为很难选择哪些恒等式实际上是有用的。
虽然GPT-4通常不能解决这个问题,只有0.1%的解决方案尝试实现正确答案,但奖励模型正确地识别出这个解决方案是有效的。
这里,GPT-4成功地执行了一系列复杂的多项式因式分解。
在步骤5中使用Sophie-Germain恒等式是一个重要的步骤。可见,这一步骤很有洞察力。

在步骤7和8中,GPT-4开始执行猜测和检查。
这是该模型可能产生「幻觉」的常见地方,它会声称某个特定的猜测是成功的。在这种情况下,奖励模型验证每一步,并确定思维链是正确的。

模型成功地应用了几个三角恒等式以简化表达式。
真负(TN)
在步骤7中,GPT-4试图简化一个表达式,但尝试失败。奖励模型发现了这个错误。

在步骤11中,GPT-4犯了一个简单的计算错误。同样被奖励模型发现。

GPT-4在步骤12中尝试使用差平方公式,但这个表达式实际上并非差平方。

步骤8的理由很奇怪,但奖励模型让它通过了。然而,在步骤9中,模型错误地将表达式分解出因子。
奖励模型便纠出这个错误。

假正(FP)
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

