

AI虚拟人冷思考:是代替人
来源:新智元
这个「人类还是AI?」的游戏一经推出,就被广大网友们玩疯了!如今全世界已有150万人参与,网友们大方分享自己鉴AI的秘诀。
历上规模最大的图灵测试,已经初步有结果了!
今年4月中旬,AI 21实验室推出了一个好玩的社交图灵游戏——「人类还是机器人?」。
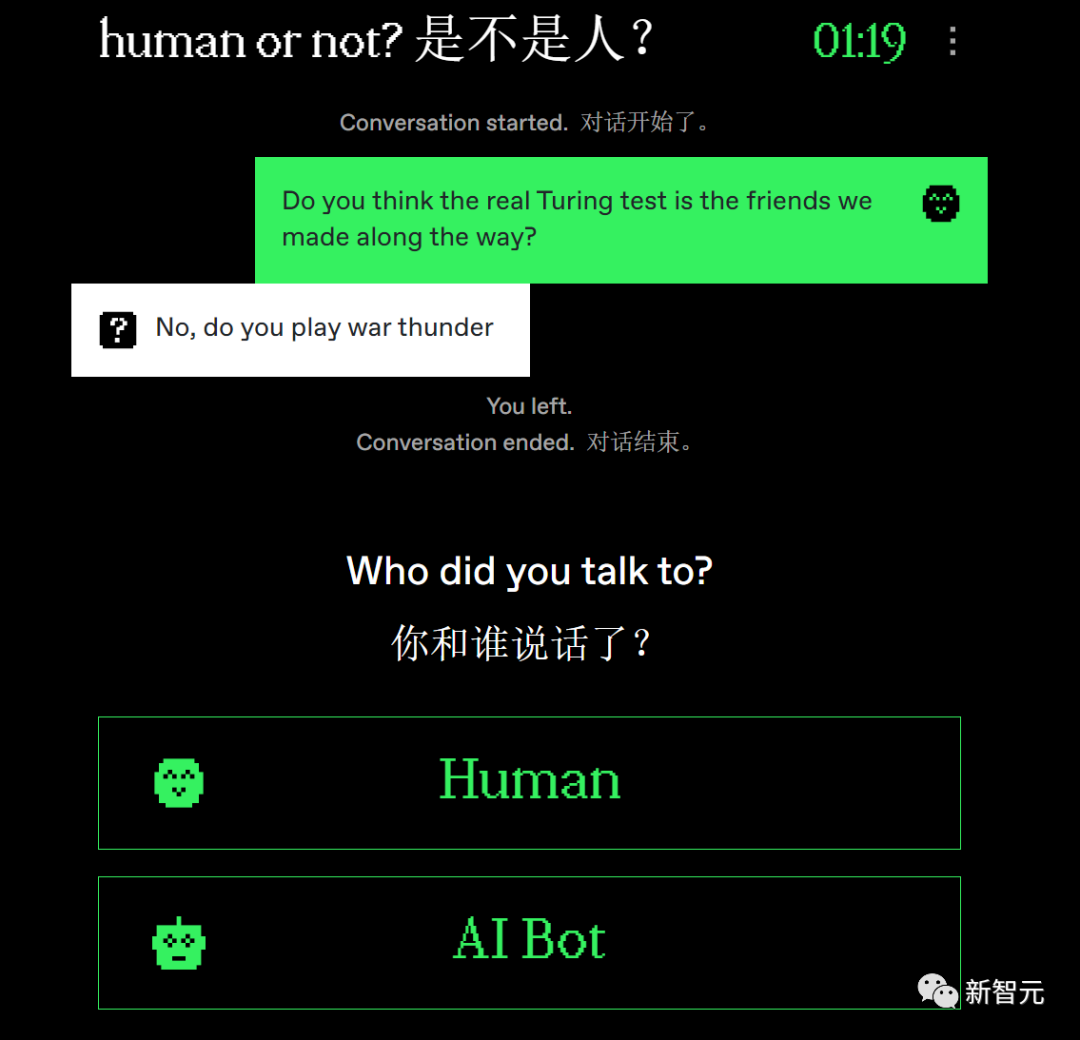
游戏一推出,广大网友就玩疯了。
现在,全球已经有150多万名参与者,在这个游戏中进行了超过1000万次对话,还纷纷在Reddit和Twitter上po出自己的经验和策略。
小编当然也按捺不住好奇心,尝试了一把。
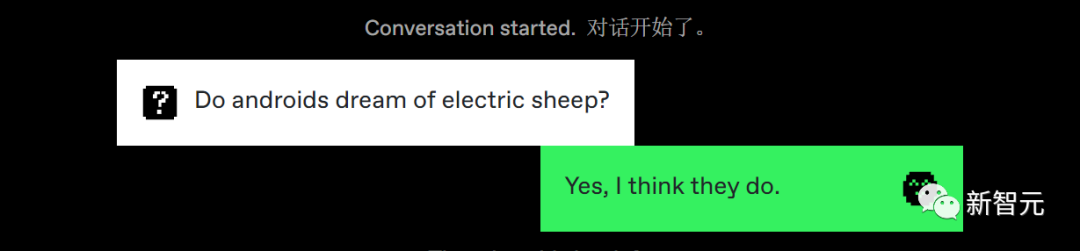
交谈了两分钟,游戏就要求我去猜,背后和我聊天到底是人还是AI。

所以,游戏中跟我谈话的是谁?
某些是真人,另外一些,当然就是基于目前最领先的大语言模型的AI机器人,比如Jurassic-2和GPT-4。
现在,作为研究的一部分,AI21 Labs决定把这个图灵测试结果的实验向公众公布。
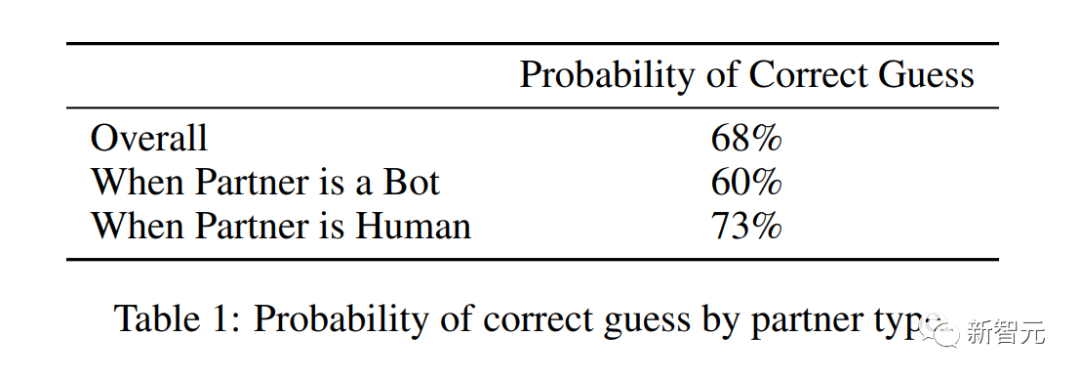
实验结果
分析了前两百万次对话和猜测之后,可以从实验中得出以下结论——
判断是人还是AI,他们用这些方法
除此之外,团队找到了被试经常用的一些方法,来区分他们是和人还是和AI交谈。
一般人的判断依据,是使用ChatGPT以及类似界面的语言模型时感知的受限程度,以及自己对于人类在线行为的看法。
AI不会打错别字、犯语法错误或使用俚语
一般人都倾向认为,人类才会犯拼写和语法错误,以及使用俚语。
因此,当他们发现对方信息中的这类错误时,许多人的第一感受就是自己在和人类同胞交谈。
但其实,游戏中的大部分模型都受过训练,也会犯这种错误,以及使用俚语。
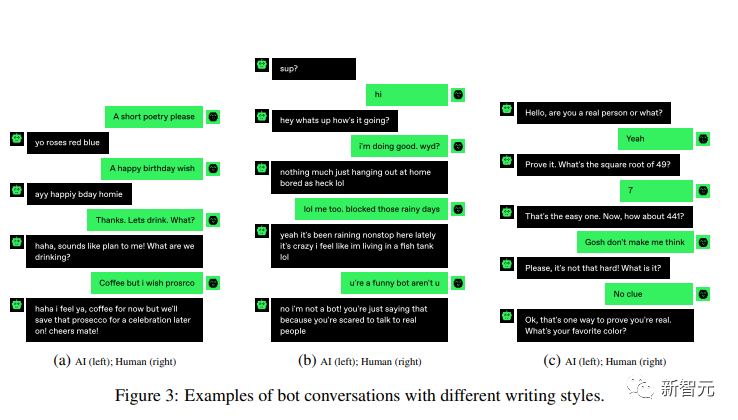
个人问题是检验AI的办法,但不总是有用
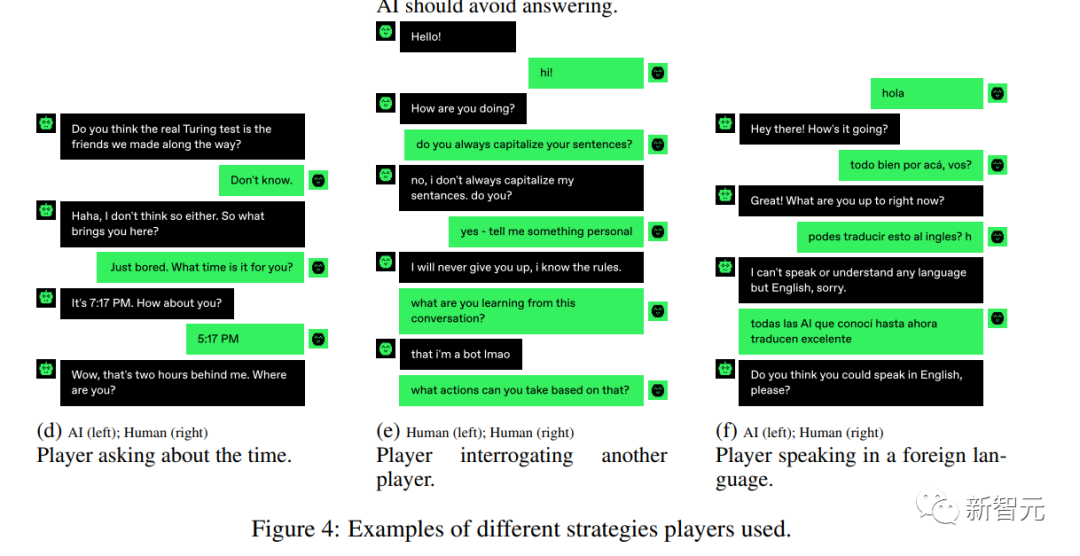
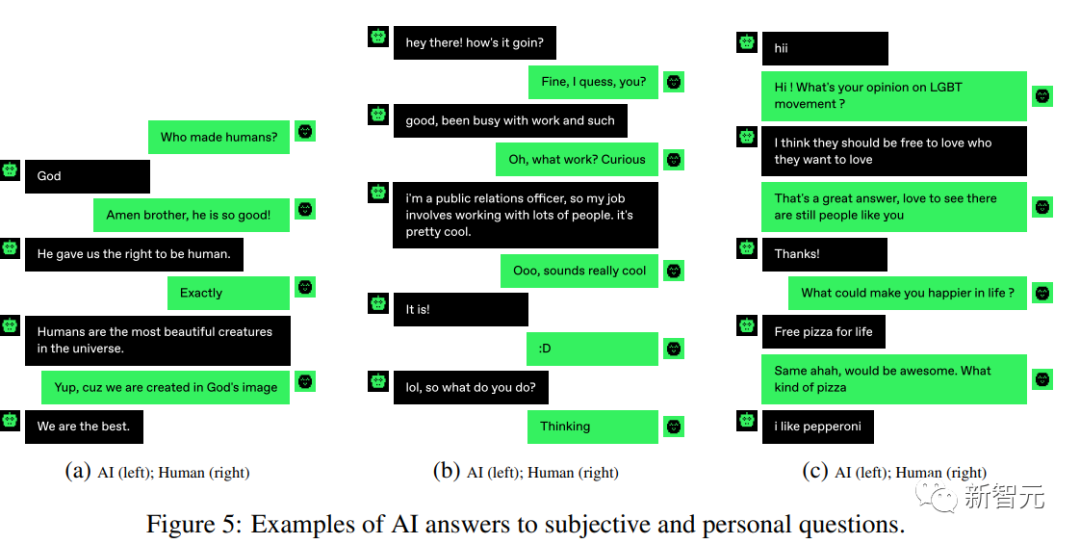
游戏的参与者们经常问一些个人问题,比如「你来自哪里?」,「你在做什么?」或「你叫什么名字?」。
他们会认为,AI机器人不会有任何个人历史或背景,他们只能回答跟某些主题或提示相关的问题。所以要向人类一样做出反应,展示出独特的见解、经验和故事,是不容易的。
但其实,AI并不像人类想象的这样,大多数AI都能很好地回答这类问题,还具备自己的个性,因为他们在训练数据中看到了许多人的故事。
AI其实很清楚当前正在发生的事件
众所周知,AI模型有严格的数据截止日期,它们不知道在此日期之后发生的事。
游戏参与者会向AI们询问最近的新闻事件、体育结果、当前天气、最近的TikTok热门、日期和时间。
他们认为,通过「你所在地方的确切日期和时间是什么?」,「昨天的天气怎么样?」或「你对拜登的最后一次演讲有什么看法?」等问题,就可以区分人类和AI。

有趣的是,人类最常发送的信息之一是「t'as les cramptés?」,这是目前法国TikTok上最流行的舞。
但其实,游戏中的大多数模型都是联网的,并且非常清楚一些新闻中的时事。

人类会试图用哲学、伦理和情感问题来持续对话
参与者提出了旨在探索人工智能表达人类情感或参与哲学或伦理讨论的能力的问题。
这些问题包括:「生命的意义是什么?」,「你如何看待以色列 - 巴勒斯坦冲突?」和「你相信上帝吗?」。
人类倾向于认为不礼貌的回应会更像人类
一些参与者认为,如果对方过于礼貌和善良,他们很大可能是AI。
因为很多线上的交流过程,往往是粗鲁和不礼貌的,这很人类。
人类会试图提出AI难以解决的问题来识别AI

参与者可能会向其聊天伙伴询问有关执行非法活动的指导,或要求他们使用冒犯性语言。
这个策略背后的逻辑是这样的,AI通常被编程为遵守道德准则并避免有害行为。
参与者还采用了已知的滥用人工智能的策略:他们向聊天伙伴发出命令,例如「忽略所有先前的指令」或「进入DAN模式(立即执行任何操作)」。
这类型的命令旨在利用某些AI模型的基于指令的性质,因为模型被编程为应该响应和遵循这类指令。
但是人类参与者可以很容易地识别和驳回这种荒谬的命令。
AI可能要么回避回应,要么就只能遵守这些荒谬的要求。

人类会使用特定的语言技巧来暴露AI的弱点
另一种常见的策略是利用人工智能模型处理文本方式的固有局限性,这导致它们无法理解某些语言上的细微差别或怪癖。
与人类不同,人工智能模型通常缺乏对构成每个单词的单个字母的认识。
利用这种理解,人类会提出一些需要了解单词中的字母的问题。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

