

“皇后之玺”数藏侵权?
来源:偲睿洞察
从2022.11.30的ChatGPT,到2023.6.13的360智脑大模型2.0,全球AI界已为大模型持续疯狂了七个多月。ChatGPT们正如雨后春笋般涌现,向AI市场投放一个个“炸弹”:办公、医疗、教育、制造,亟需AI的赋能。
而AI应用千千万,把大模型打造好才是硬道理。
对于大模型“世界”来说,算法是“生产关系”,是处理数据信息的规则与方式;算力是“生产力”,能够提高数据处理、算法训练的速度与规模;数据是“生产资料”,高质量的数据是驱动算法持续迭代的养分。在这之中,算力是让大模型转动的前提。
我们都知道的是,大模型正对算力提出史无前例的要求,具体的表现是:据英伟达数据显示,在没有以Transformer模型为基础架构的大模型之前,算力需求大致是每两年提升8倍;而自利用Transformer模型后,算力需求大致是每两年提升275倍。基于此,530B参数量的Megatron-Turing NLG模型,将要吞噬超10亿FLOPS的算力。
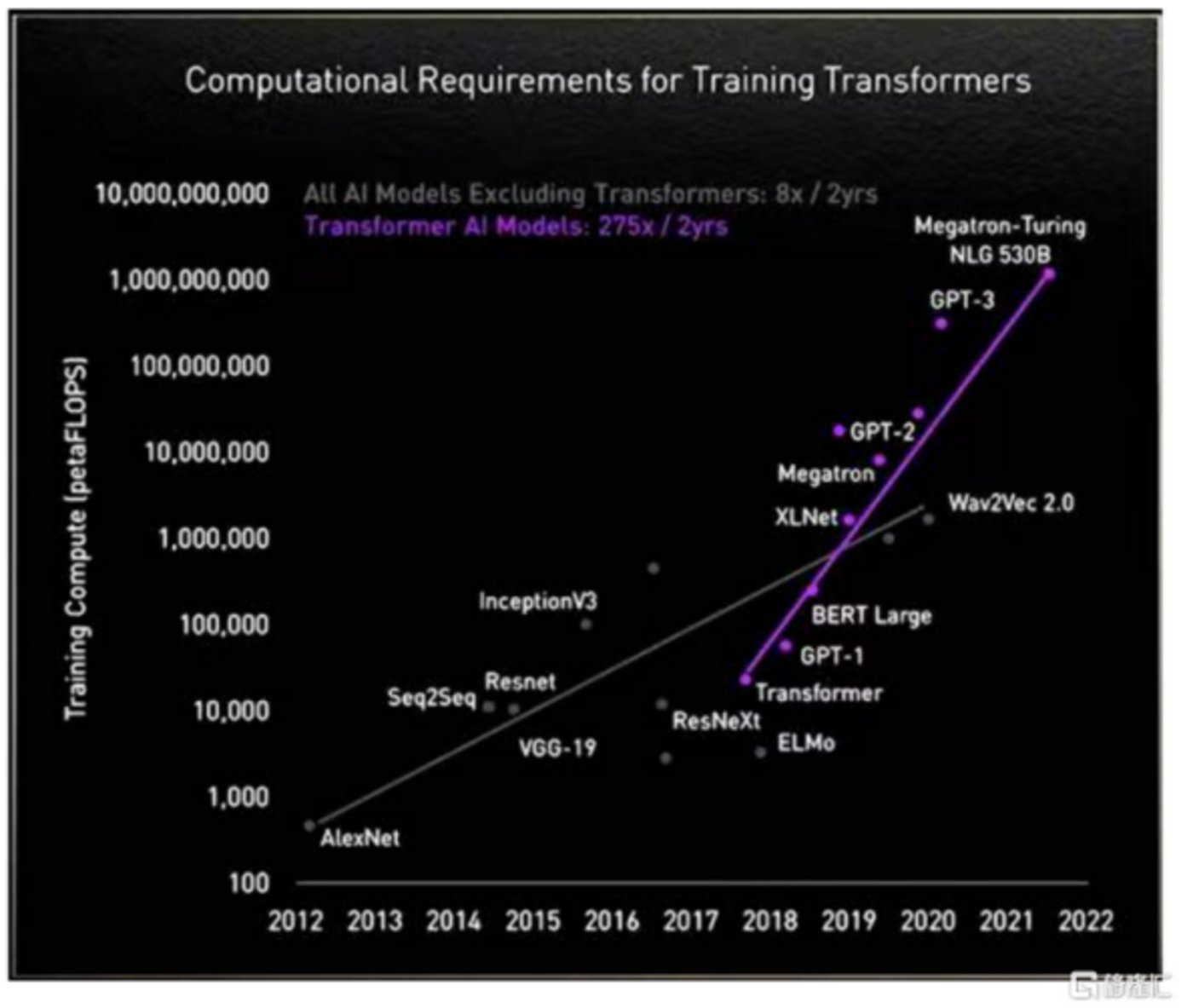
(AI不同模型算法算力迭代情况 图源:格隆汇)
作为大模型的大脑——AI芯片,是支撑ChatGPT们高效生产及应用落地的基本前提。保证算力的高效、充足供应,是目前AI大算力芯片厂商亟需解决的问题。
GPT-4等大模型向芯片厂商狮子大开口的同时,也为芯片厂商尤其是初创芯片厂商,带来一个利好消息:软件生态重要性正在下降。
早先技术不够成熟之时,研究者们只能从解决某个特定问题起步,参数量低于百万的小模型由此诞生。例如谷歌旗下的AI公司DeepMind,让AlphaGO对上百万种人类专业选手的下棋步骤进行专项“学习”。
而小模型多了之后,硬件例如芯片的适配问题迫在眉睫。故,当英伟达推出统一生态CUDA之后,GPU+CUDA迅速博得计算机科学界认可,成为人工智能开发的标准配置。
现如今纷纷涌现的大模型具备多模态能力,能够处理文本、图片、编程等问题,也能够覆盖办公、教育、医疗等多个垂直领域。这也就意味着,适应主流生态并非唯一的选择:在大模型对芯片需求量暴涨之时,芯片厂商或许可以只适配1-2个大模型,便能完成以往多个小模型的订单。
也就是说,ChatGPT的出现,为初创芯片厂商们提供了弯道超车的机会。这就意味着,AI芯片市场格局将发生巨变:不再是个别厂商的独角戏,而是多个创新者的群戏。
本报告将梳理AI芯片行业发展概况、玩家情况,总结出大算力时代,玩家提高算力的路径,并基于此,窥探AI大算力芯片的发展趋势。
国产AI芯片,正走向AI 3.0时代
现阶段的AI芯片,根据技术架构种类来分,主要包括GPGPU、FPGA、以 VPU、TPU 为代表的 ASIC、存算一体芯片。
根据其在网络中的位置,AI 芯片可以分为云端AI芯片 、边缘和终端AI芯片;
云端主要部署高算力的AI训练芯片和推理芯片,承担训练和推理任务,例如智能数据分析、模型训练任务等;
边缘和终端主要部署推理芯片,承担推理任务,需要独立完成数据收集、环境感知、人机交互及部分推理决策控制任务。
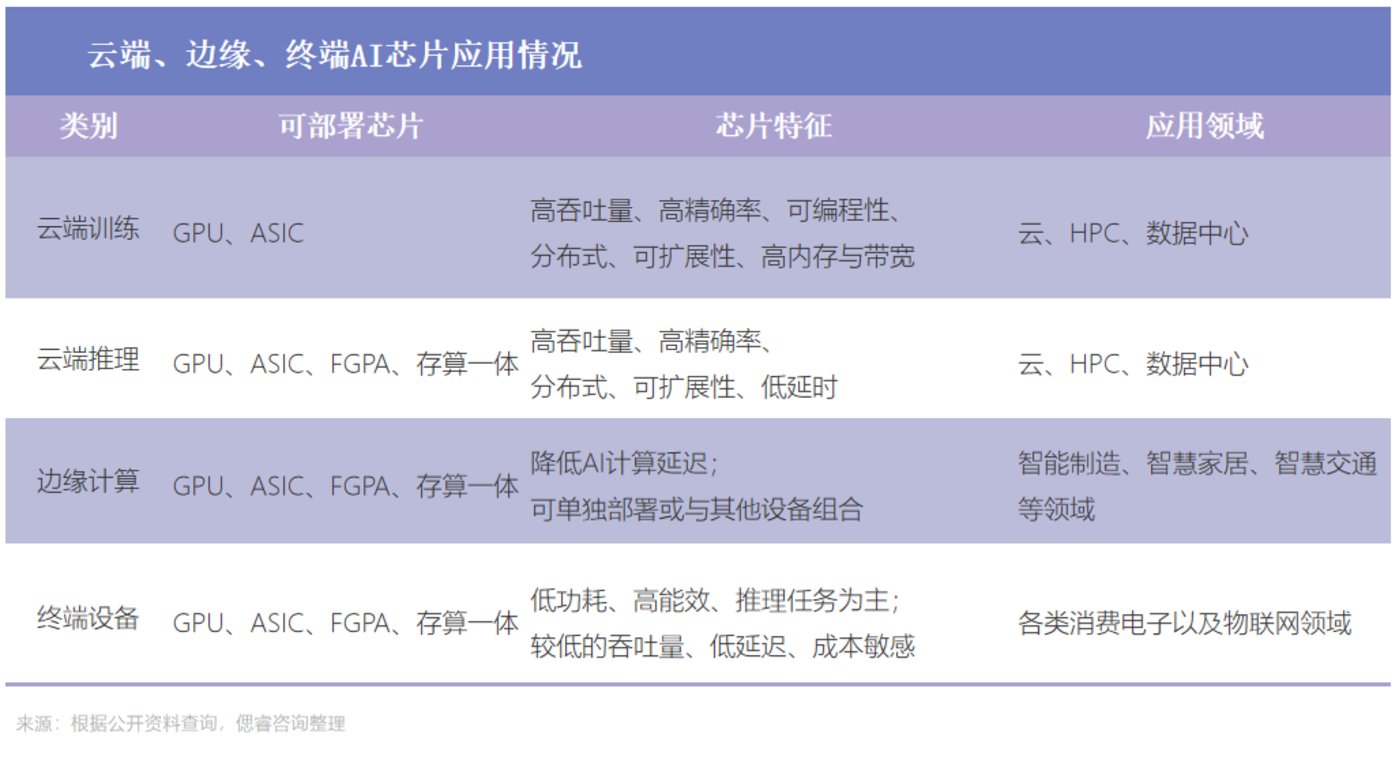
根据其在实践中的目标,可分为训练芯片和推理芯片:

纵观AI芯片在国内的发展史,AI芯片国产化进程大致分为三个时代。
1.0时代,是属于ASIC架构的时代
自2000年互联网浪潮拉开AI芯片的序幕后,2010年前后,数据、算法、算力和应用场景四大因素的逐渐成熟,正式引发AI产业的爆发式增长。申威、沸腾、兆芯、龙芯、魂芯以及云端AI芯片相继问世,标志着国产AI芯片正式启航。
2016年5月,当谷歌揭晓AlphaGo背后的功臣是TPU时,ASIC随即成为“当红辣子鸡”。于是在2018年,国内寒武纪、地平线等国内厂商陆续跟上脚步,针对云端AI应用推出ASIC架构芯片,开启国产AI芯片1.0时代。
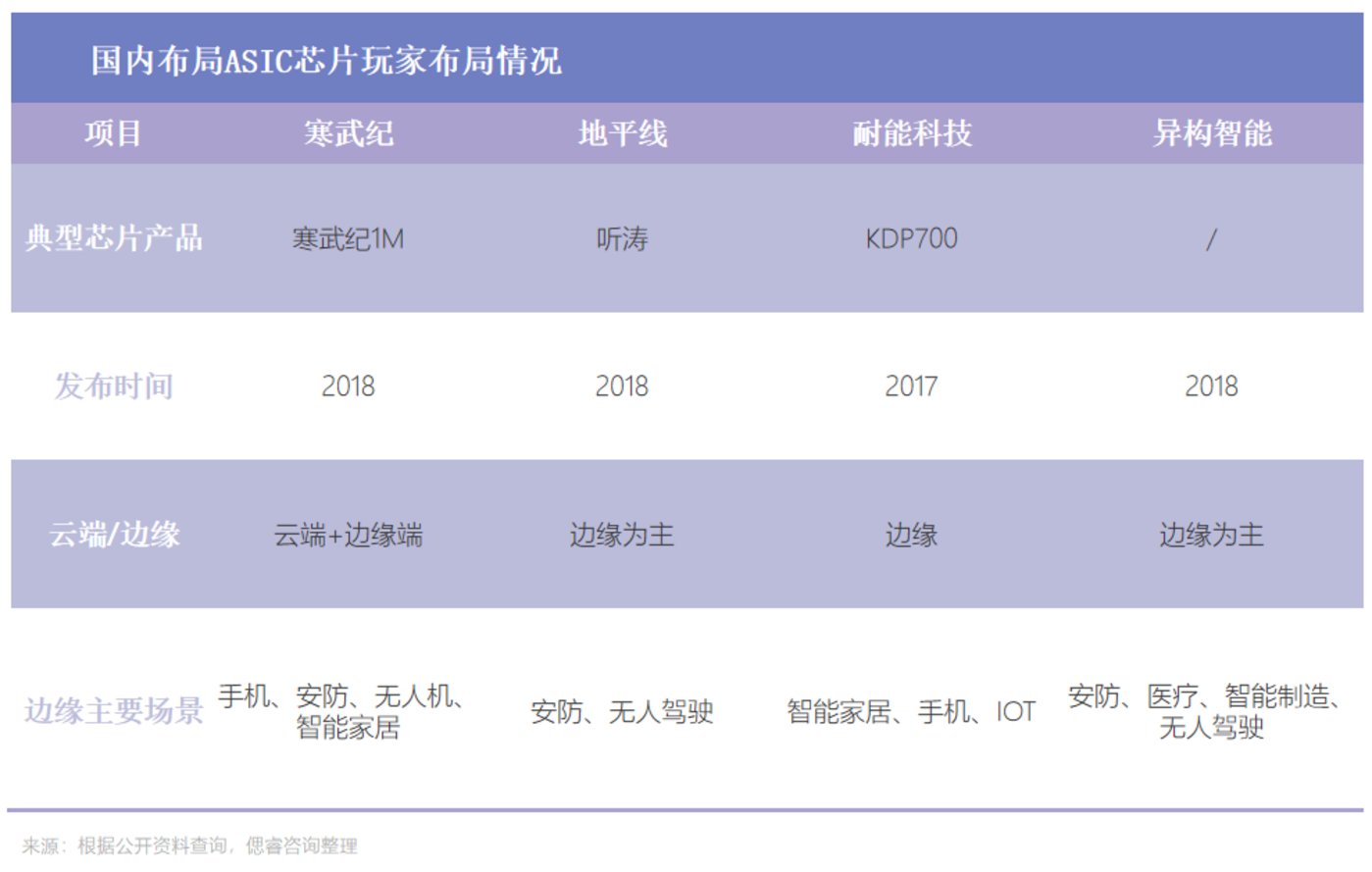
ASIC芯片,能够在某一特定场景、算法较固定的情况下,实现更优性能和更低功耗,基于此,满足了企业对极致算力和能效的追求。
所以当时的厂商们,多以捆绑合作为主:大多芯片厂商寻找大客户们实现“专用场景”落地,而有着综合生态的大厂选择单打独斗。
地平线、耐能科技等AI芯片厂商,分别专注AI芯片的细分领域,采用“大客户捆绑”模式进入大客户供应链。

在中厂们绑定大客户协同发展之际,自有生态的大厂阿里成立独资芯片公司平头哥,着眼AI和量子计算。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

