

巴比特 | 元宇宙每日必读
原文来源:新智元

图片来源:由无界 AI生成
如今,GPT-4、PaLM等巨型神经网络模型横空出世,已经展现出惊人的少样本学习能力。
只需给出简单提示,它们就能进行文本推理、编写故事、回答问题、编程......
然鹅,LLM在复杂、多步推理任务上却常常败给人类,且苦苦挣扎无果。
对此,中国科学院和耶鲁大学的研究人员提出了一种「思维传播」(Thought Propagation)新框架,能够通过「类比思维」增强LLM的推理。

论文地址:https://arxiv.org/abs/2310.03965
「思维传播」灵感来自人类认知,即当遇到一个新问题时,我们经常将其与我们已经解决的类似问题进行比较,以推导出策略。
因此,这一方法的核心便是,让LLM在解决输入的问题之前,探索与输入相关的「类似」问题。
最后,它们的解决方案可以拿来即用,或提取有用计划的见解。
可以预见的是,「思维传播」在为LLM逻辑能力的固有限制提出的全新思路,让大模型像人类一样用「类比」方法解决难题。

LLM多步推理,败给人类
显而易见,LLM擅长根据提示进行基本推理,但在处理复杂的多步骤问题时仍有困难,比如优化、规划。
反观人类,他们会汲取类似经验中的直觉来解决新问题。
大模型无法做到这点,是由其固有的局限性决定的。
因为LLM的知识完全来自于训练数据中的模式,无法真正理解语言或概念。因此,作为统计模型,它们很难进行复杂的组合泛化。
最最重要的是,LLM缺乏系统推理能力,无法像人类那样逐步推理,从而解决具有挑战性的问题。
再加上,大模型的推理是局部的、「短视的」,因此LLM很难找到最佳解决方案,也很难在长时间范围内保持推理的一致性。
总之,大模型在数学证明、战略规划和逻辑推理方面的缺陷,主要源于2个核心问题:
- 无法重用先前经验中的见解。
人类从实践中积累了可重复使用的知识和直觉,有助于解决新问题。相比之下,LLM在处理每个问题时都是 「从0开始」,不会借鉴先前的解决方案。
- 多步骤推理中的复合错误。
人类会监控自己的推理链,并在必要时修改最初的步骤。但是LLM在推理的早期阶段所犯的错误会被放大,因为它们会把后面的推理引向错误的道路。
以上这些弱点,严重阻碍了LLM应对需要全局最优或长期规划的复杂挑战中的应用。
对此,研究人员提出了一种全新的解决方法——思维传播。
TP框架
通过类比思维,让LLM更像人类一样进行推理。
在研究者看来,从0开始推理无法重复使用解决类似问题的见解,而且会在中间推理阶段出现错误累积。
而「思维传播」可以探索与输入问题相关的类似问题,并从类似问题的解决方案中获得启发。
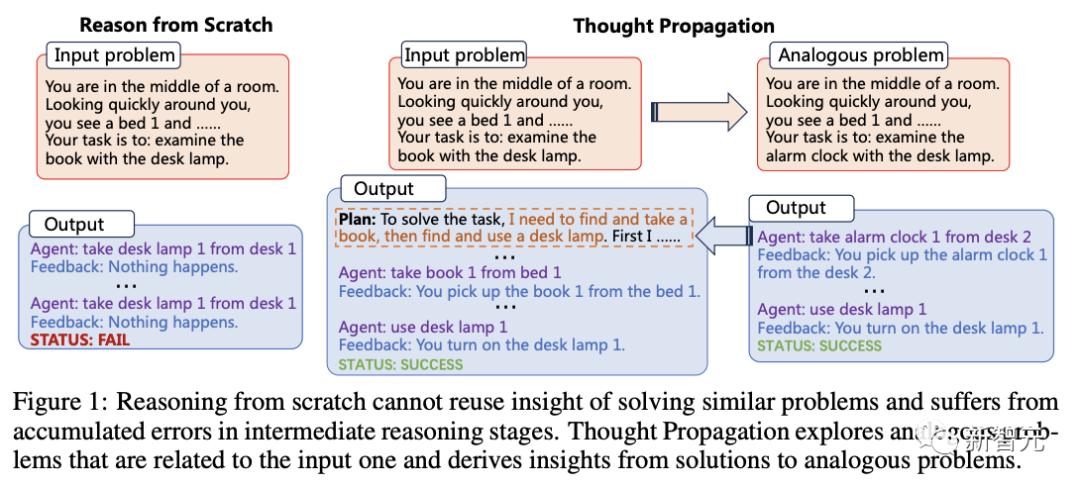
下图是「思维传播」(TP)与其他代表性技术的比较,对于输入问题 p,IO、CoT和ToT会从头开始推理,才得出解决方案s。
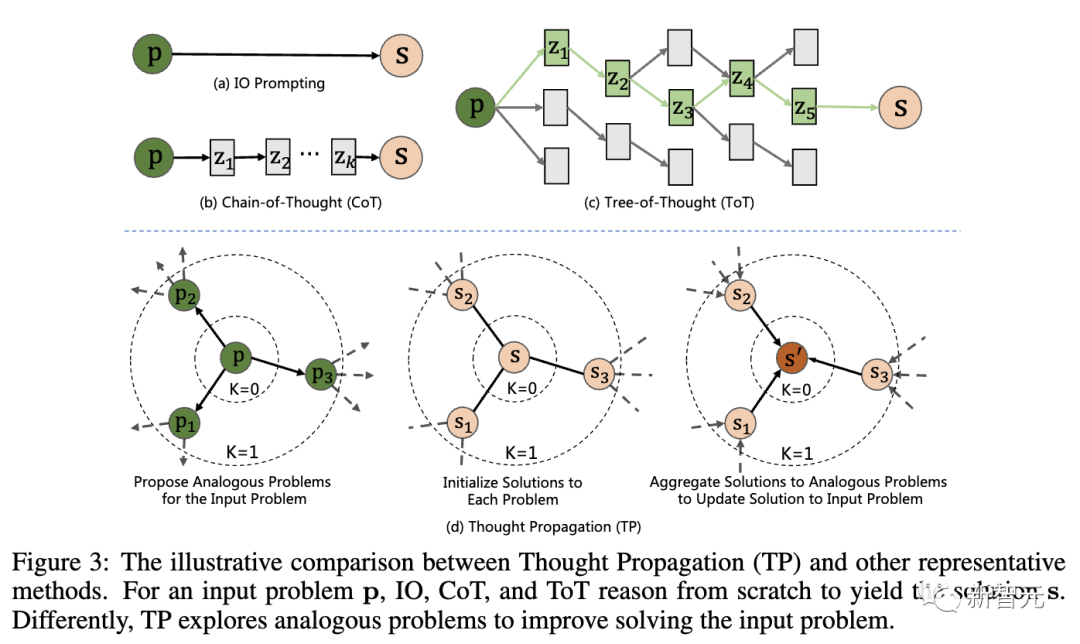
具体来说,TP包括了三个阶段:
1. 提出类似问题:LLM通过提示生成一组与输入问题有相似之处的类似问题。这将引导模型检索潜在的相关先前经验。
2. 解决类似问题:通过现有的提示技术,如CoT,让LLM解决每个类似的问题。
3. 汇总解决方案:有2种不同的途径——根据类比解决方案,直接推断出输入问题的新解决方案;通过比较输入问题的类比解决方案,推导出高级计划或策略。
这样一来,大模型就可以重用先前的经验和启发式方法,还可以将其初始推理与类比解决方案进行交叉检查,以完善这些解决方案。
值得一提的是,「思维传播」与模型无关,可以在任何提示方法的基础上进行单个问题解决步骤。
这一方法关键的新颖之处在于,激发LLM类比思维,以引导复杂的推理过程。
「思维传播」究竟能让LLM多像人类,还得实操结果来说话。
中国科学院和耶鲁的研究人员在3个任务中进行了评估:
- 最短路径推理:需要在图中找到节点之间的最佳路径需要全局规划和搜索。即使在简单的图上,标准技术也会失败。
- 创意写作:生成连贯、有创意的故事是一个开放式的挑战。当给出高层次的大纲提示时,LLM通常会失去一致性或逻辑性。
- LLM智能体规划:与文本环境交互的LLM智能体与长期战略方面举步维艰。它们的计划经常会出现「漂移」或陷入循环。
最短路径推理
最短路径推理任务中,现有的方法推理遇到的问题无法解决。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

