

巴比特 | 元宇宙每日必读
原文来源:新智元

图片来源:由无界 AI生成
不得了了!
现在只用打几个字就能创造精美、高质量的3D模型出来了?
这不,国外一篇博客引爆网络,把一个叫MVDream的东西摆到了我们面前。
用户只需要寥寥数语,就可以创造出一个栩栩如生的3D模型。

而且和之前不同的是,MVDream看起来是真的「懂」物理。
下面就来看看这个MVDream有多神奇吧~
MVDream
小哥表示,大模型时代,我们已经看到了太多太多文本生成模型、图片生成模型。而且这些模型的性能也越来越强大。
后来,我们甚至还目睹了文生视频模型的诞生,当然也包括今天要提到的3D模型。
试想一下,你只需要输入一句话,就可以生成一个宛如存在于真实世界的物体模型,甚至还包含着所有必要细节,这个场景该有多酷。
而且这绝对不是一件简单的事,尤其是用户需要生成的模型所呈现的细节要足够逼真。
先来看看效果~

同一个prompt,最右侧就是MVDream的成品。
肉眼可见5个模型的差距。前几个模型完全违背了客观事实,只有从某几个角度看才是对的。
比如前四张图片,生成的模型居然有不止两只耳朵。而第四张图片虽然看起来细节更丰满一点,但是转到某个角度我们能发现,人物的脸是凹进去的,上面还插着一只耳朵。
谁懂啊,小编一下就想起了之前很火的小猪佩奇正视图。

就是那种,某些角度是展示给你看的,别的角度千万别看,会死人。
可最右边MVDream的生成模型显然不一样。无论3D模型怎样转动,你都不会觉得有任何反常规的地方。
这也就是开头所提到的,MVDream真懂物理常识,而不会为了保证在每个视图下都有两只耳朵而搞出一些奇奇怪怪的东西。
小哥指出,一个3D模型是否成功,最主要的就是观察这个模型的不同视角是不是都足够逼真,质量都足够高。
而且还要保证模型在空间上的连贯性,而不是像上面多个耳朵的模型那样。
生成3D模型的主要方法之一,就是对摄像机的视角进行模拟,然后生成某一视角下所能看到的东西。
换个词,这就是所谓的2D提升(2D lifting)。就是将不同的视角拼接在一起,形成最终的3D模型。
出现上面多耳的情况,就是因为生成模型对整个物体在三维空间的样态信息掌握的不充分。而MVDream恰恰就是在这方面往前迈了一大步。
新模型解决了之前一直出现的3D视角下的一致性问题。
分数蒸馏采样
而用到的方法叫做分数蒸馏采样(score distillation sampling),由DreamFusion开发。
在了解分数蒸馏采样技术之前,我们需要先了解一下该方法所使用的架构。
简而言之,这其实只是另一种二维图像的扩散模型,同类的还有DALLE、MidJourney和Stable Diffusion模型。
更具体地说,一切的一切都是从预训练好的DreamBooth模型开始的,DreamBooth是一个基于Stable Diffusion生图的开源模型。
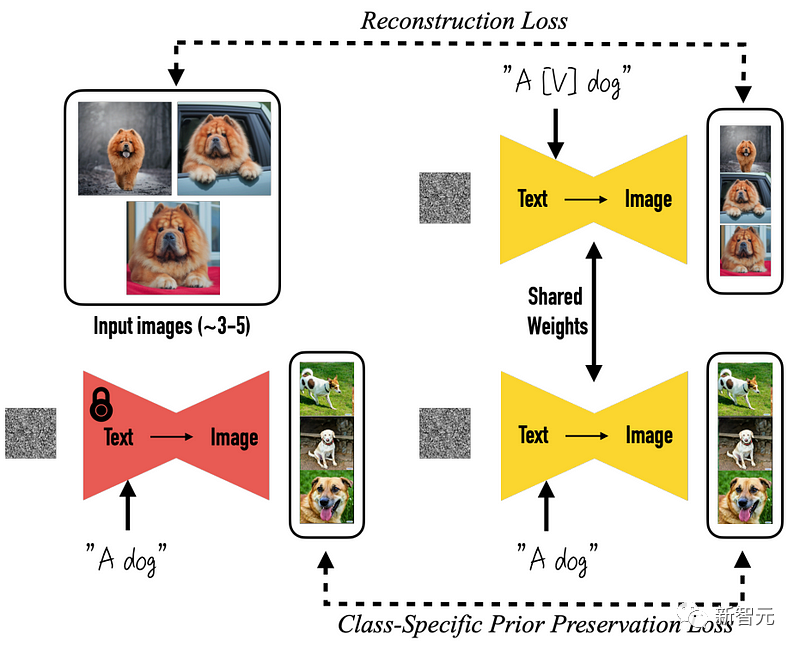
然后,改变来了。
研究团队后续所做的是,直接渲染一组多视角图像,而不是只渲染一张图像,这一步需要有各种物体的三维数据集才可以完成。
在这里,研究人员从数据集中获取了三维物体的多个视图,利用它们来训练模型,再使其向后生成这些视图。
具体做法是将下图中的蓝色自注意块改为三维自注意块,也就是说,研究人员只需要增加一个维度来重建多个图像,而不是一个图像。
在下图中,我们可以看到摄像机和时间步(timestep)也都被输入到了每个视图的模型中,以帮助模型了解哪个图像将用在哪里,以及需要生成的是哪种视图。
现在,所有图像都连接在一起,生成也同样在一起完成。因此它们就可以共享信息,更好地理解全局的情况。
然后,再将文本输入模型,训练模型从数据集中准确地重建物体。
而这里也就是研究团队应用多视图分数蒸馏采样过程的地方。
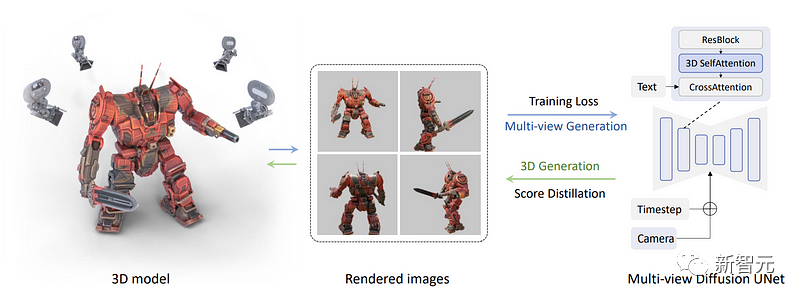
现在,有了一个多视图的扩散模型,团队可以生成一个物体的多个视图了。
下一步,就是用这些视图来重建一个和真实世界一致的三维模型,而不仅仅是视图。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

