

ChatGPT 即将诞生一周年,
训练一个媲美 MJ 的文生图模型,26K 美元就能实现了。

图片来源:由无界 AI生成
原文来源:机器之心
当前,最先进的文本到图像(T2I)模型需要大量的训练成本(例如,数百万个 GPU 小时),这严重阻碍了 AIGC 社区的基础创新,同时增加了二氧化碳排放。
现在,来自华为诺亚方舟实验室等研究机构的研究者联合提出了开创性的文本到图像(T2I)模型 PixArt-α, 只需要 Stable Diffusion v1.5 训练时间的 10.8%(约 675 vs 约 6250 A100 GPU 天),省下近 30 万美元(26000 美元 vs 320000 美元)。与更大的 SOTA 模型 RAPHAEL 相比,PixArt-α 的训练成本仅为 1%,且支持直接生成高达 1024×1024 分辨率的高分辨率图像。
PixArt-α 模型不仅大幅降低了训练成本,还显著减少了二氧化碳排放,同时提供了接近商业应用标准的高质量图像生成。PixArt-α 的出现,为 AIGC 社区和初创公司提供了新的视角,以加速他们构建自己的高质量且低成本的生成模型。

总的来说,PixArt-α 是一种基于 Transformer 的 T2I 扩散模型,其图像生成质量可以与最先进的图像生成器(例如,Imagen [1],SDXL [2],甚至 Midjourney [3])相媲美,达到接近商业应用的标准。此外,它支持高达 1024×1024 分辨率的高分辨率图像的直接生成,训练成本低,如下图 1 所示。

图表 1.PixArt-α 产生的样本展示出了其卓越的质量,其特点是高精确度和准确性的图像生成。
为了实现这个目标,该研究提出了三个核心设计:
大量的实验表明,PixArt-α 在图像质量、艺术性和语义控制方面表现出色。研究团队希望 PixArt-α 能为 AIGC 社区和初创公司提供新的思路,以加速他们从头开始构建自己的高质量且低成本的生成模型。
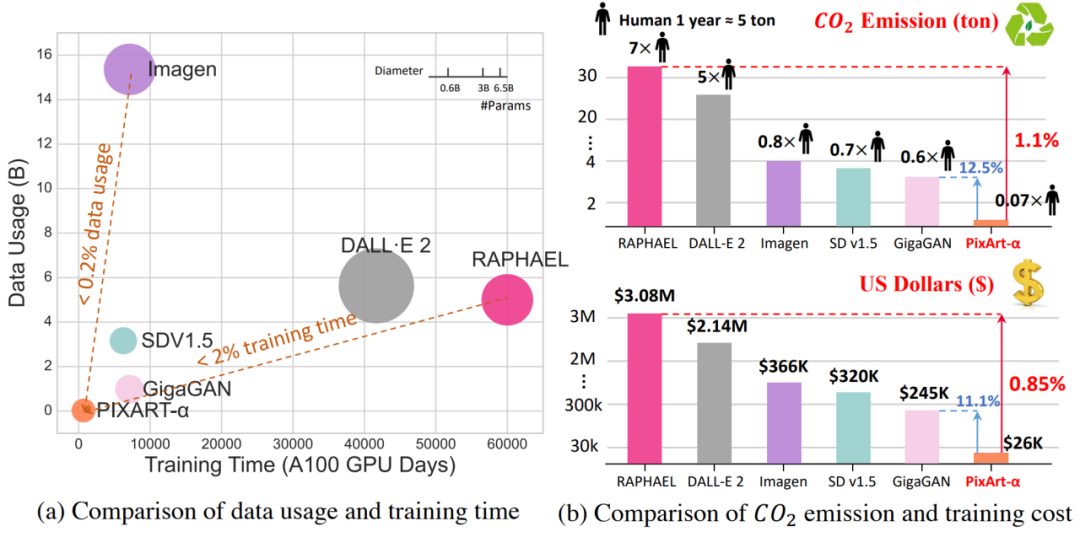
图表 2.T2I 方法之间的二氧化碳排放和训练成本比较。PixArt-α 实现了极低的训练成本,仅为 26,000 美元。相比于 RAPHAEL,PixArt-α 的二氧化碳排放和训练成本分别仅为 1.1% 和 0.85%。
从现象看本质:从训练流程和数据的角度重新审视文生图任务
从现有训练流程出发:文本到图像(T2I)生成任务可以分解为三个方面:建模像素间关系、文本与图像的精确对齐以及高审美质量生成。然而,现有方法将这三个问题混合在一起,并直接使用大量数据从零开始训练,导致训练效率低下。
从训练数据出发:如图 3 所示,现有的文本 - 图像对常常存在文本 - 图像不对齐、描述不足、包含大量不常见词汇以及包含低质量数据等问题。这些问题给训练带来了困难,导致需要进行数百万次迭代才能实现文本和图像之间的稳定对齐。为了解决这个挑战,该研究引入了一个创新的自动标注流程来生成精确的图像标题。

图表 3.LAION [6] 原生标题 v.s. LLaVA 精细标题的对比。LLaVA 提供了信息密度更高的文本,帮助模型在每次迭代中掌握更多概念,提高了文本 - 图像对齐的效率。
解耦训练策略:不同数据获取、强化不同能力
1. 像素间依赖学习
当前 class-condition 的方法 [7] 在生成语义连贯且像素逻辑合理的图像上展现出了卓越的性能。训练一个符合自然图像分布的 class-condition 图像生成模型,不仅训练相对简单,成本也较低。该研究还发现,适当的初始化可以极大地提升图像生成模型的训练效率。因此,PixArt 模型采用了一个 ImageNet 预训练模型作为基础,来增强模型的性能。此外,该研究也提出了重参数化来兼容预训练权重,以确保最佳的算法效果。
2. 文本图像对齐
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

