

ChatGPT 即将诞生一周年,
原文来源:新智元

图片来源:由无界 AI生成
目前的开放世界目标检测模型大多遵循文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标,但这种方式往往会面临「广而不精」的问题。

论文链接:https://arxiv.org/abs/2305.18980
代码地址:https://github.com/YifanXu74/MQ-Det
为此,中科院自动化等机构的研究人员提出了基于多模态查询的目标检测MQ-Det,以及首个同时支持文本描述和视觉示例查询的开放世界检测大模型。
MQ-Det在已有基于文本查询的检测大模型基础上,加入了视觉示例查询功能。通过引入即插即用的门控感知结构,以及以视觉为条件的掩码语言预测训练机制,使得检测器在保持高泛化性的同时支持细粒度的多模态查询,为用户提供更灵活的选择来适应不同的场景。
其简单有效的设计与现有主流的检测大模型均兼容,适用范围非常广泛。
实验表明,多模态查询能够大幅度推动主流检测大模型的开放世界目标检测能力,例如在基准检测数据集LVIS上,无需下游任务模型微调,提升主流检测大模型GLIP精度约7.8%AP,在13个基准小样本下游任务上平均提高了6.3% AP。
从文本查询到多模态查询
一图胜千言
随着图文预训练的兴起,借助文本的开放语义,目标检测逐渐步入了开放世界感知的阶段。
为此,许多检测大模型都遵循了文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标。
然而,这种方式往往会面临「广而不精」的问题。
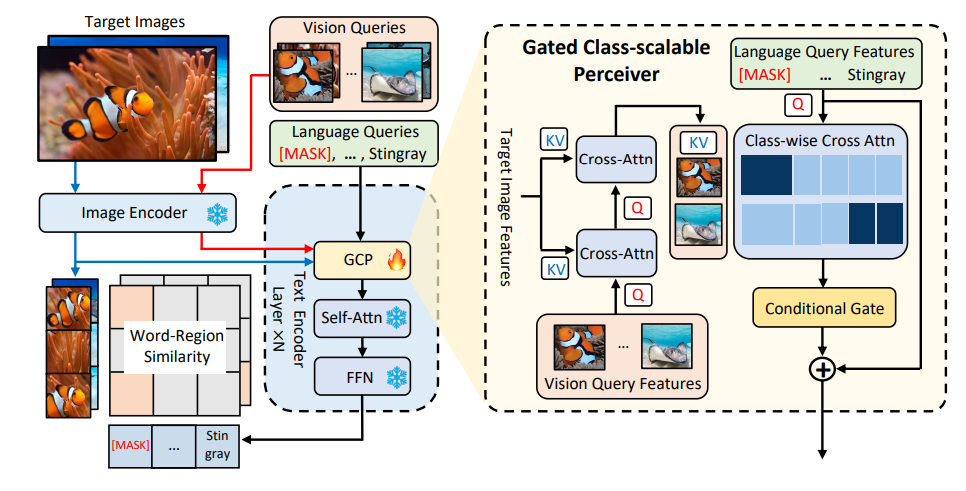
图1 MQ-Det方法架构图
例如,图1中的细粒度物体(鱼种)检测,往往很难用有限的文本来描述各种细粒度的鱼种;类别歧义,bat既可指蝙蝠又可指拍子。
然而,以上的问题均可通过图像示例来解决,相比文本,图像能够提供目标物体更丰富的特征线索,但同时文本又具备强大的泛化性。
由此,如何能够有机地结合两种查询方式,成为了一个很自然地想法。
获取多模态查询能力的难点:如何得到这样一个具备多模态查询的模型,存在三个挑战:
1. 直接用有限的图像示例进行微调很容易造成灾难性遗忘;
2. 从头训练一个检测大模型会具备较好的泛化性但是消耗巨大,例如,单卡训练GLIP[1]需要利用3000万数据量训练480 天。
多模态查询目标检测:基于以上考虑,作者提出了一种简单有效的模型设计和训练策略——MQ-Det
MQ-Det在已有冻结的文本查询检测大模型基础上插入少量门控感知模块(GCP)来接收视觉示例的输入,同时设计了视觉条件掩码语言预测训练策略高效地得到高性能多模态查询的检测器。
MQ-Det:即插即用的多模态查询模型架构
门控感知模块
如图1所示,作者在已有冻结的文本查询检测大模型的文本编码器端逐层插入了门控感知模块(GCP),GCP的工作模式可以用下面公式简洁地表示:
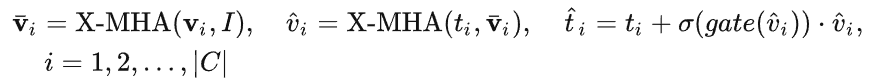
对于第i个类别,输入视觉示例 v_i,其首先和目标图像
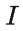
进行交叉注意力( X-MHA)得到
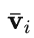
以增广其表示能力,而后每个类别文本 t_i 会和对应类别的视觉示例
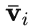
进行交叉注意力得到
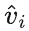
,之后通过一个门控模块gate 将原始文本 t_i 和视觉增广后文本
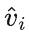
融合,得到当前层的输出
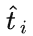
这样的简单设计遵循了三点原则:(1)类别可扩展性;(2)语义补全性;(3)抗遗忘性,具体讨论可见原文。
MQ-Det高效训练策略
基于冻结语言查询检测器的调制训练
由于目前文本查询的预训练检测大模型本身就具备较好的泛化性,作者认为,只需要在原先文本特征基础上用视觉细节进行轻微地调整即可。
在文章中也有具体的实验论证发现,打开原始预训练模型参数后进行微调很容易带来灾难性遗忘的问题,反而失去了开放世界检测的能力。
由此,MQ-Det在冻结文本查询的预训练检测器基础上,仅调制训练插入的GCP模块,就可以高效地将视觉信息插入到现有文本查询的检测器中。
在文章中,作者分别将MQ-Det的结构设计和训练技术应用于目前的SOTA模型GLIP[1]和GroundingDINO[2],来验证方法的通用性。
以视觉为条件的掩码语言预测训练策略
作者还提出了一种视觉为条件的掩码语言预测训练策略,来解决冻结预训练模型带来的学习惰性的问题。
所谓学习惰性,即指检测器在训练过程中倾向于保持原始文本查询的特征,从而忽视新加入的视觉查询特征。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

