

巴比特丨每日必读:讯飞
原文来源:新智元

图片来源:由无界AI生成
最近,包括LeCun在内的一众大佬又开始针对LLM开炮了。最新的突破口是,LLM完全没有推理能力!
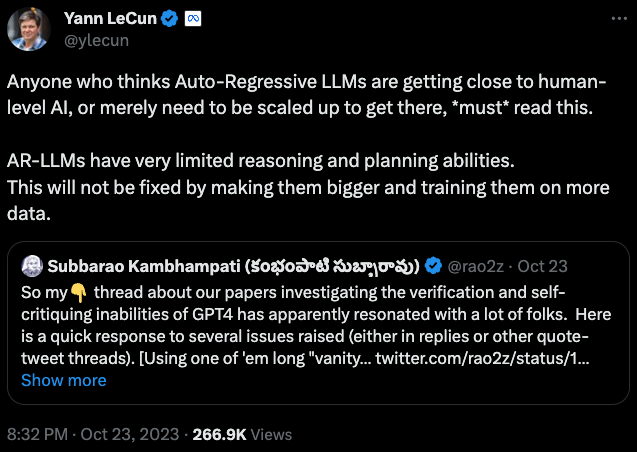
在LeCun看来,推理能力的缺陷几乎是LLM的「死穴」,无论未来采用多强大的算力,多广阔和优质的数据集训练LLM,都无法解决这个问题。

而LeCun抛出的观点,引发了众多网友和AI大佬针对这个问题的讨论,其中包括xAI的联合创始人之一Christian Szegedy。
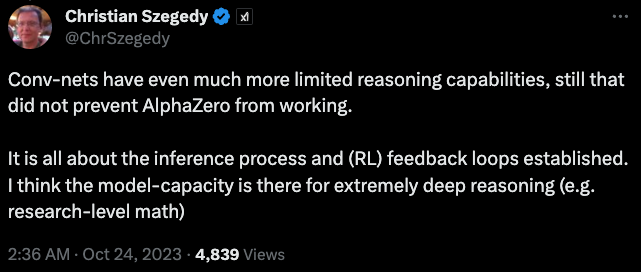
AI科学家Christian Szegedy回复LeCun:
卷积网络的推理能力更加有限,但这并没有影响 AlphaZero的能力。
从两位大佬的进一步讨论中,我们甚至能窥探到xAI未来的技术方向——如何利用大模型的能力突破AI的推理能力上限。
而网友们在这个问题之下,对于LLM推理能力的宽容,也展现出了AI与人类智能关系的另一种思考:
人类也不是所有人都擅长推理,难道因为有人不擅长推理,就要否认人类智能的客观性吗?
也许人类和LLM一样,也只是一种不同形式的「随机鹦鹉」罢了!
大佬对话透露出xAI的技术方向
论文在arXiv上公布后,特别经过LeCun的转发,引起了网友和学者的广泛讨论。
马老板牵头成立的xAI的联合创始人,AI科学家Christian Szegedy回复到:
卷积网络的推理能力更加有限,但这并没有影响 AlphaZero的能力。
关键在于推理过程和建立的 (RL) 反馈循环。他认为模型能力可以进行极其深入的推理。(例如进行数学研究)
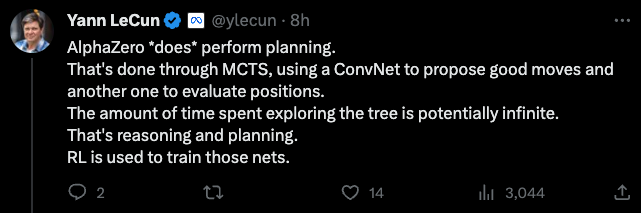
LeCun也直接回复到:
AlphaZero「确实」可以执行规划。但是通过MCTS完成的,使用卷积网络提出好的行为,另一个卷积网络来评估位置。
然而探索这棵树所花费的时间可能是无限的。这就是推理和计划。而强化学习是用来训练这些网络的。
Christian Szegedy继续回复到:
我同意。所以我认为的方法是:
- 迫使系统探索与我们相关的推理空间的大部分内容。
- 使其以可验证的方式进行探索。
- 了解人类对有趣事物的品味。
在我看来,所有这些都很快变得可行。
而从xAI联创嘴里说出来的观点,加上最后这句:「在我看来,所有这些都很快变得可行」,不由得让人浮想连篇。
毕竟如此肯定地说「可行」,最直接的原因也许就是「我们已经做出来了。」

也许在不久的将来,我们将能看到xAI抓住LLM推理能力弱的「痛点」,穷追猛打,打造出一个「强推理」的大模型,弥补了像ChatGPT等市面上一干大模型产品的最大缺陷。
LeCun:说多少次了,LLM就是不行!
而LeCun最近批驳LLM推理能力的依据,是ASU大学的教授Subbarao Kambhampati最近的几篇论文。

个人介绍:https://rakaposhi.eas.asu.edu/
在他看来,在很多能力上号称达到和超越人类水平的LLM,在推理和规划能力上有重大缺陷。

论文地址:https://arxiv.org/abs/2310.12397

论文地址:https://arxiv.org/abs/2310.08118
论文地址:https://arxiv.org/abs/2305.15771
在人类专家级的规划推理难题面前,GPT-4的正确率只有12%。
而且,在推理任务中,如果让LLM对自己的答案进行自我修正,输出质量会不增反降。
也就是说,LLM根本没有能力推理出正确答案,一切只能靠猜。
而教授在论文发表之后,还针对网友和学者对于论文的讨论,发了一条长推,进一步阐述了自己的观点。

教授认为LLM是出色的「创意发生器」,但是无论是在语言还是代码方面,但它们不能自主规划或推理。
教授指出,对于LLM的自我纠正能力,学界存在很多误解。
一些论文的作者过度人格化LLM,误以为它们能像人类一样产生错误并自我修正。
他批评了使用随意整理的Q&A数据集来制定和评估自评声明的做法,认为这种做法在社区中造成了混淆。
教授还指出外部验证和人类参与的重要性。尽管GPT-4不能验证颜色配置,但可以帮助生成Python代码,需要人类修正后可以作为外部验证器。
同时,与人类和专业推理器合作的模型,也将有助于模型推理能力的提升。
教授列出了一些论文,展示了如何从LLM中提取规划域模型,通过人类和专用推理器的帮助进行优化,并用于计划验证器或独立域计划器。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

