

巴比特丨每日必读:讯飞
原文来源:远川科技评论

图片来源:由无界AI生成
上个月,AI业界爆发了一场“动物战争”。
一方是Meta推出的Llama(美洲驼),由于其开源的特性,历来深受开发者社区的欢迎。NEC(日本电气)在仔细钻研了Llama论文和源代码后,迅速“自主研发”出了日语版ChatGPT,帮日本解决了AI卡脖子难题。
另一方则是一个名为Falcon(猎鹰)的大模型。今年5月,Falcon-40B问世,力压美洲驼登顶了“开源LLM(大语言模型)排行榜”。
该榜单由开源模型社区Hugging face制作,提供了一套测算LLM能力的标准,并进行排名。排行榜基本上就是Llama和Falcon轮流刷榜。
Llama 2推出后,美洲驼家族扳回一城;可到了9月初,Falcon推出了180B版本,又一次取得了更高的排名。
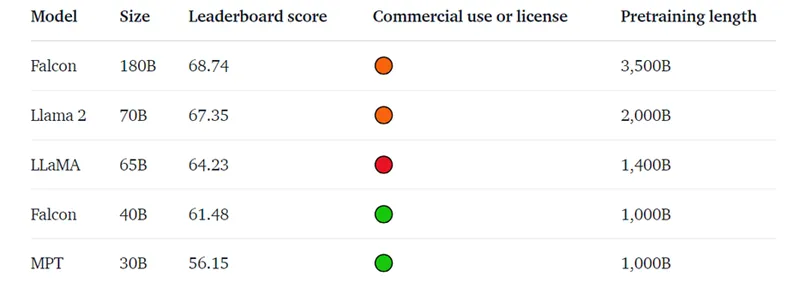
Falcon以68.74分力压Llama 2
有趣的是,“猎鹰”的开发者不是哪家科技公司,而是位于阿联酋首都阿布扎比的科技创新研究所。政府人士表示,“我们参与这个游戏是为了颠覆核心玩家”[4]。
180B版本发布第二天,阿联酋人工智能部长奥马尔就入选了《时代周刊》评选的“AI领域最具影响力的100人”;与这张中东面孔一同入选的,还有“AI教父”辛顿、OpenAI的阿尔特曼,以及李彦宏。

阿联酋人工智能部长
如今,AI领域早已步入了“群魔乱舞”的阶段:但凡有点财力的国家和企业,或多或少都有打造“XX国版ChatGPT”的计划。仅在海湾国家的圈子内,已不止一个玩家——8月,沙特阿拉伯刚刚帮国内大学购买了3000多块p00,用于训练LLM。
金沙江创投朱啸虎曾在朋友圈吐槽道:“当年看不起(互联网的)商业模式创新,觉得没有壁垒:百团大战、百车大战、百播大战;没想到硬科技大模型创业,依然是百模大战...”
说好的高难度硬科技,怎么就搞成一国一模亩产十万斤了?
Transformer吞噬世界
美国的初创公司、中国的科技巨擘、中东的石油大亨能够逐梦大模型,都得感谢那篇著名的论文:《Attention Is All You Need》。
2017年,8位谷歌的计算机科学家在这篇论文中,向全世界公开了Transformer算法。这篇论文目前是人工智能历史上被引数量第三高的论文,Transformer的出现则扣动了此轮人工智能热潮的扳机。
无论当前的大模型是什么国籍,包括轰动世界的GPT系列,都是站在了Transformer的肩膀上。
在此之前,“教机器读书”曾是个公认的学术难题。不同于图像识别,人类在阅读文字时,不仅会关注当前看到的词句,更会结合上下文来理解。
比如“Transformer”一词其实可翻译成“变形金刚”,但本文读者肯定不会这么理解,因为大家都知道这不是一篇讲好莱坞电影的文章。
但早年神经网络的输入都彼此独立,并不具备理解一大段文字、甚至整篇文章的能力,所以才会出现把“开水间”翻译成“open water room”这种问题。
直到2014年,在谷歌工作、后来跳槽去了OpenAI的计算机科学家伊利亚(Ilya Sutskever)率先出了成果。他使用循环神经网络(RNN)来处理自然语言,使谷歌翻译的性能迅速与竞品拉开了差距。
RNN提出了“循环设计”,让每个神经元既接受当前时刻输入信息,也接受上一时刻的输入信息,进而使神经网络具备了“结合上下文”的能力。
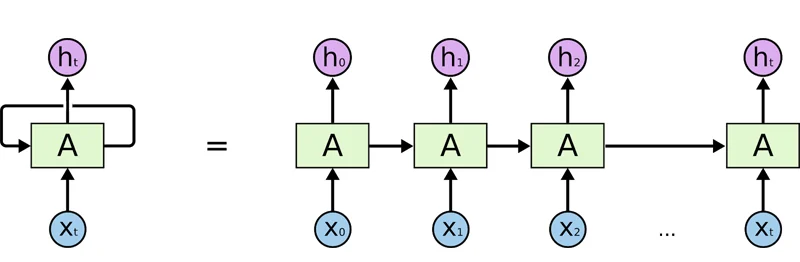
循环神经网络
RNN的出现点燃了学术圈的研究热情,日后Transformer的论文作者沙泽尔(Noam Shazeer)也一度沉迷其中。然而开发者们很快意识到,RNN存在一个严重缺陷:
该算法使用了顺序计算,它固然能解决上下文的问题,但运行效率并不高,很难处理大量的参数。
RNN的繁琐设计,很快让沙泽尔感到厌烦。因此从2015年开始,沙泽尔和7位同好便着手开发RNN的替代品,其成果便是Transformer[8]。

Noam Shazeer
相比于RNN,Transformer的变革有两点:
一是用位置编码的方式取代了RNN的循环设计,从而实现了并行计算——这一改变大大提升了Transformer的训练效率,从而变得能够处理大数据,将AI推向了大模型时代;二是进一步加强了上下文的能力。
随着Transformer一口气解决了众多缺陷,它渐渐发展成了NLP(自然语言处理)的唯一解,颇有种“天不生Transformer,NLP万古如长夜”的既视感。连伊利亚都抛弃了亲手捧上神坛的RNN,转投Transformer。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

