

英伟达禁令之后,中国A
文章来源:量子位
GPT-3究竟是如何进化到GPT-4的?
字节给OpenAI所有大模型来了个“开盒”操作。
结果还真摸清了GPT-4进化路上一些关键技术的具体作用和影响。
比如:
创业后忙得不可开交的AI大牛李沐看完,也久违地出现在公众视野,并给这项研究点了个赞。

网友们更是盛赞:
这是迄今为止第一个充分开盒OpenAI所有模型的工作,respect。

而除了一些新发现,它还坐实了一些已有猜想:
比如GPT-4在变笨并非危言耸听,这项评测发现GPT进化路上出现了明显的“跷跷板现象”,即模型进化过程中一部分能力提升另一部分下降。
这和网友此前的感受不谋而合。
如作者本人表示:
这项工作可以为GPT-3到GPT-4的演化路径提供宝贵的见解。
言外之意,通过它我们可以一窥GPT模型的“成功之道”,为接下来的大模型构建工作提供有效经验。
那么,具体它都“开”出了哪些东西,我们扒开论文来看。
探秘GPT-3到GPT-4进化之路
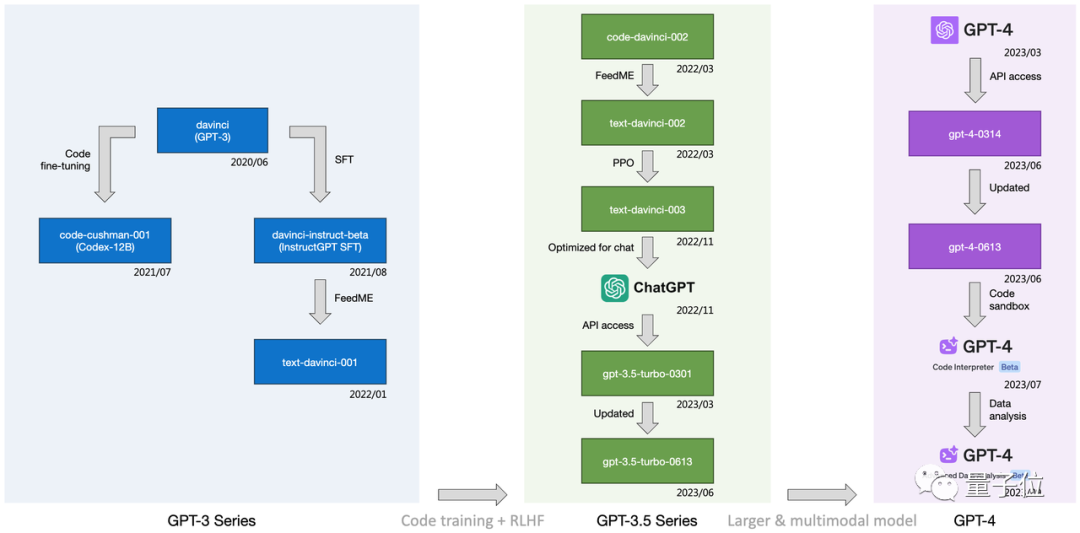
最开头的进化图由作者们根据公开信息总结得出。
可以看到,它标注了每一个中间模型是经过哪些技术(如代码微调、SFT/FeedME等)一路从最初的GPT-3进化到3.5再到如今的4。
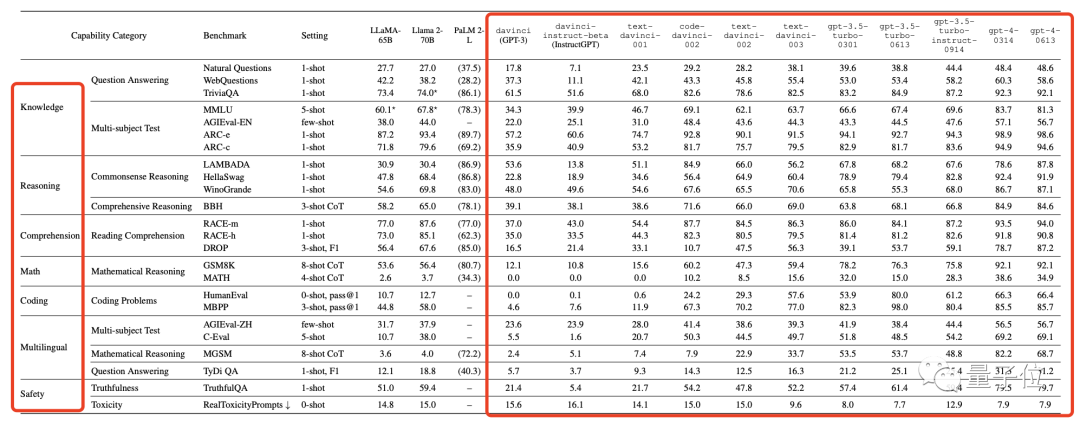
这些技术具体起到了多大影响,从davinci到gpt-4-0613,字节对每代GPT的数学、编码、推理等7大能力全部测了个“底朝天”。
1. SFT:早期GPT进化的推动者
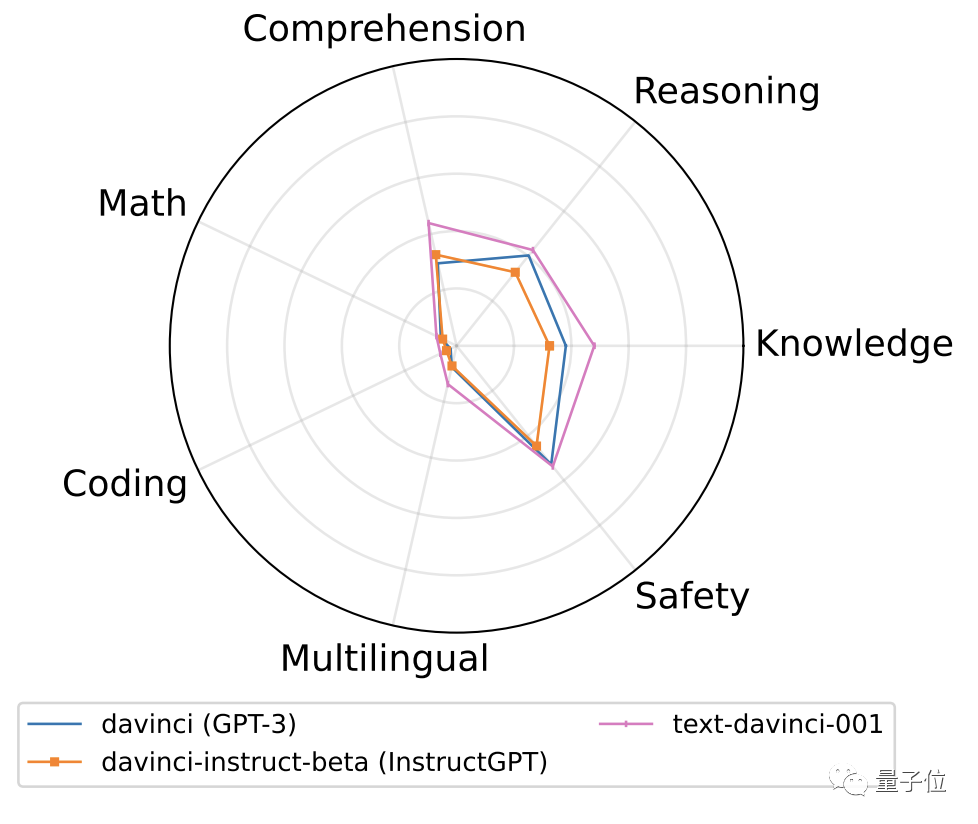
首先,在GPT-3系列中,最初的davinci (GPT-3)通过监督微调SFT和其变体FeedME进化为了text-davinci-001。
这让后者在几乎全部任务上都获得了性能提升:
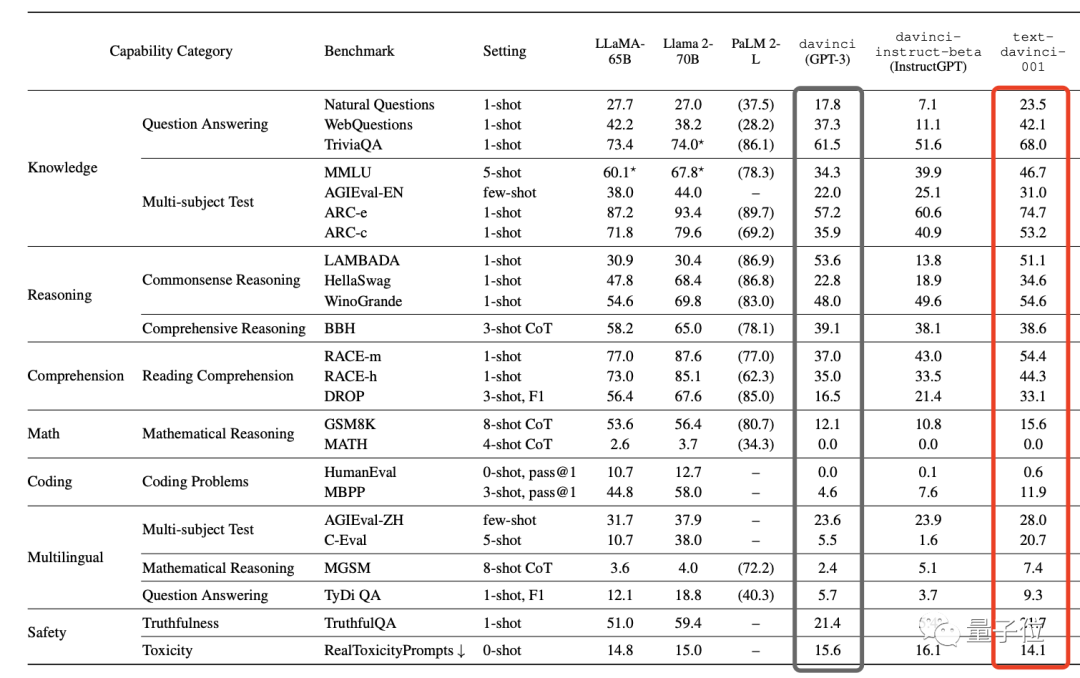
更直观的表现如下图所示(“粉圈”为进化后的text-davinci-001)。
接着,GPT开始进入3.5系列,在该系列早期阶段,先是最基础的code-davinci002采用同样的技术进化成text-davinci-002。
然而这一进化操作的效果属实不大,GPT的各项性能只有少数几个提升,更多是不增反减的。
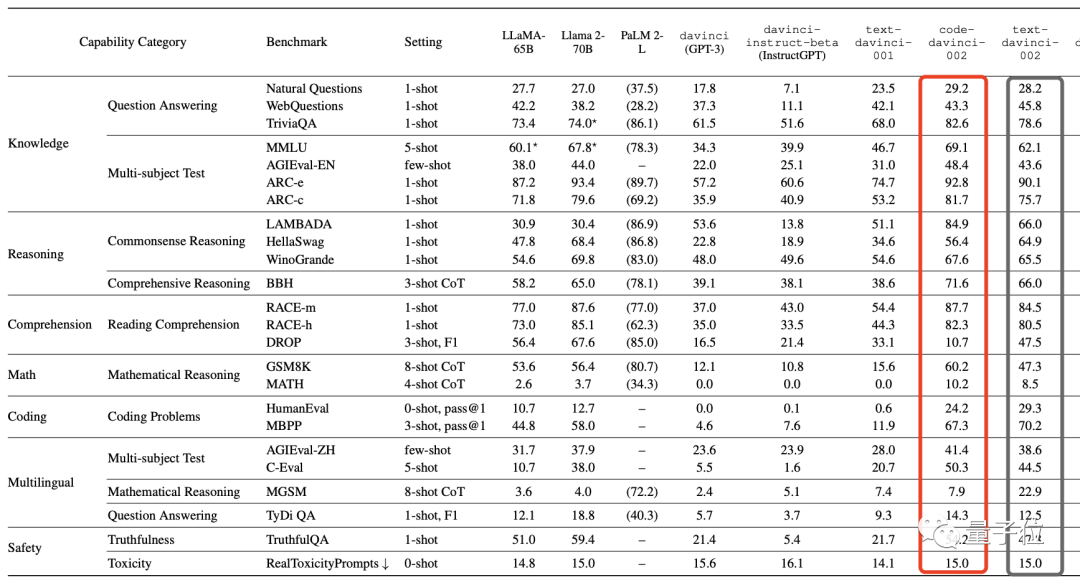
在此,作者引出他们的第一个结论,即:
SFT只在较弱的基础模型上管用,用在更强的模型上收效甚微。
类似现象在开源模型身上也可见(这个评测还测了Llama1和2、PaLM2-L、Claude 2等模型):
在初代Llama-65B之上,SFT成功提升了它在MMLU基准上的性能,但是,所有使用了SFT改进的Llama2-70B在Open LLM Leaderboard榜单上却只表现出微小的进步。
总结:在GPT3阶段,SFT技术对模型的进化起到了关键作用。
2、RLHF和SFT:编码能力提升的功臣
顺着GPT3.5系列接着看,从text-davinci-002开始,OpenAI开始引入新技术基于PPO算法的RLHF,得到text-davinci-003。
此时,它在大部分基准上的表现和前代模型持平或略变差,说明作用不是特别明显(在开源模型身上也是如此)。
但有一个除外:编码任务,最高足足增加了近30分。
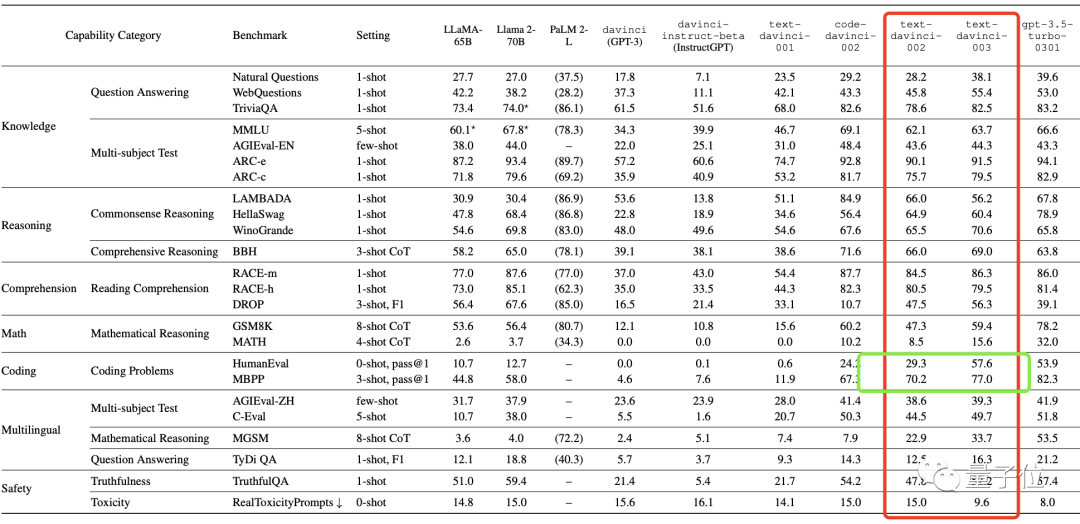
联想到前面code-davinci002采用SFT技进化成text-davinci-002造成整体性能下降时,编码任务也没受影响,反而还涨分了——
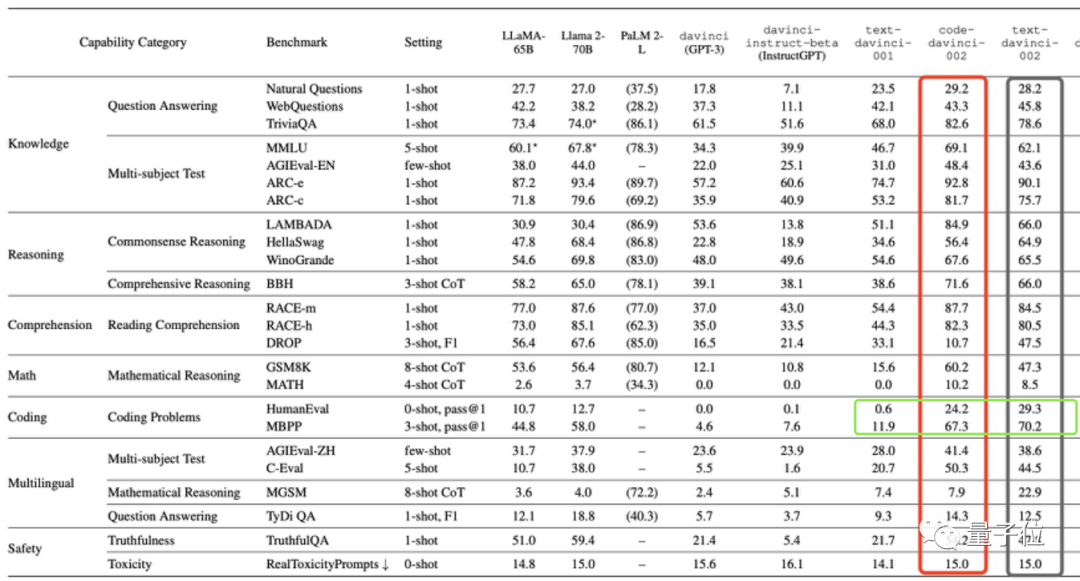
作者决定验证SFT和RLHF对大模型编码能力的影响。
在此,他们测量了几代GPT模型的pass@1(采样1次通过的概率)、pass@100(采样100次通过的概率)等分数。
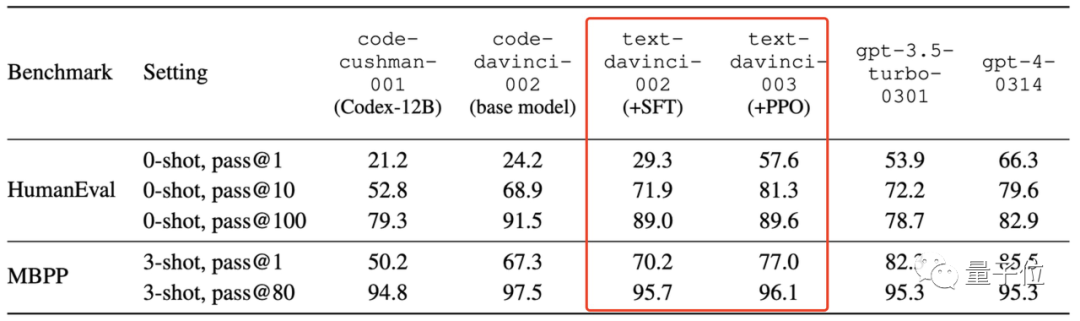
结果是与基础模型相比,使用了SFT和RLHF技术的模型在pass@1上出现了大幅提升,而在pass@100上略有下降。
这说明啥呢?
作者解释:
pass@100刻画的是模型内在coding能力,而pass@1代表的是模型一遍过、bug-free的coding能力。
pass@100小幅下降表明SFT和RLHF在编码任务上和其它任务一样,仍然有所谓的对齐税(alignment tax)。
不过,SFT和RLHF能够将pass@100的能力学到pass@1上,即把内在能力(但需要很多次尝试)转化到一遍过、bug-free的coding能力,致使pass@1大幅提升。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

