

veDAO研究院:送钱送利息,
文章来源:量子位

图片来源:由无界 AI生成
特斯拉前AI总监Andrej Karpathy的新教程火了。
这次,他专门面向普通大众做了一个关于大语言模型的科普视频。
时长1小时,全部为“非技术介绍”,涵盖模型推理、训练、微调和新兴大模型操作系统以及安全挑战,涉及的知识全部截止到本月(非常新)。

△视频封面图是Andrej用Dall·3画的
视频上线油管仅1天,就已经有20万播放量。

有网友表示:
我刚看了10分钟就已经学到了很多东西,我以前从未用过视频中讲的这样的例子来解释LLM,它还弄清了我以前看到过的很多“混乱”的概念。

在一水儿的夸课程质量高之外,还有相当多的人评价Andrej本人真的非常擅长简化复杂的问题,教学风格也总是让人印象深刻。

不止如此,这个视频还可以说是体现了他对本职专业满满的热爱。
这不,据Andrej本人透露,视频是他在感恩节假期录的,背景就是他的度假酒店(手动狗头)。
做这个视频的初衷呢,也是因为他最近在人工智能安全峰会上做了个演讲,演讲内容没有录像,但有很多观众都表示喜欢其内容。
于是他就干脆直接进行了一些微调,再讲一遍做成视频给更多人观看。
那么,具体都有些啥——
咱们一一给大伙呈上。
Part 1: 大模型本质就是两个文件
第一部分主要是对大模型整体概念的一些解释。
首先,大模型是什么?
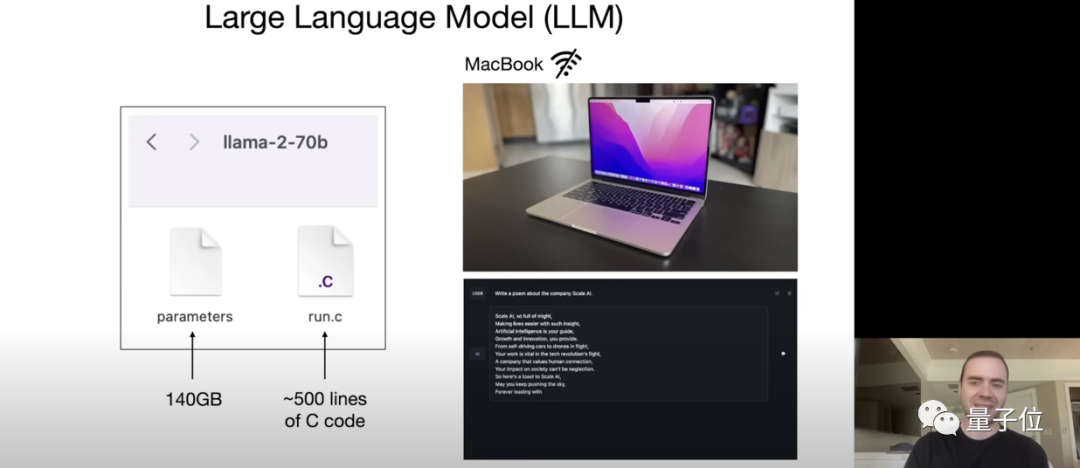
Andrej的解释非常有趣,本质就是两个文件:
一个是参数文件,一个是包含运行这些参数的代码文件。
前者是组成整个神经网络的权重,后者是用来运行这个神经网络的代码,可以是C或者其他任何编程语言写的。
有了这俩文件,再来一台笔记本,我们就不需任何互联网连接和其他东西就可以与它(大模型)进行交流了,比如让它写首诗,它就开始为你生成文本。
那么接下来的问题就是:参数从哪里来?
这就引到了模型训练。
本质上来说,大模型训练就是对互联网数据进行有损压缩(大约10TB文本),需要一个巨大的GPU集群来完成。
以700亿参数的羊驼2为例,就需要6000块GPU,然后花上12天得到一个大约140GB的“压缩文件”,整个过程耗费大约200万美元。

而有了“压缩文件”,模型就等于靠这些数据对世界形成了理解。
那它就可以工作了。
简单来说,大模型的工作原理就是依靠包含压缩数据的神经网络对所给序列中的下一个单词进行预测。
比如我们将“cat sat on a”输入进去后,可以想象是分散在整个网络中的十亿、上百亿参数依靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如“mat(97%)”,就形成了“猫坐在垫子上(cat sat on a mat)”的完整句子(神经网络的每一部分具体如何工作目前还不清楚)。
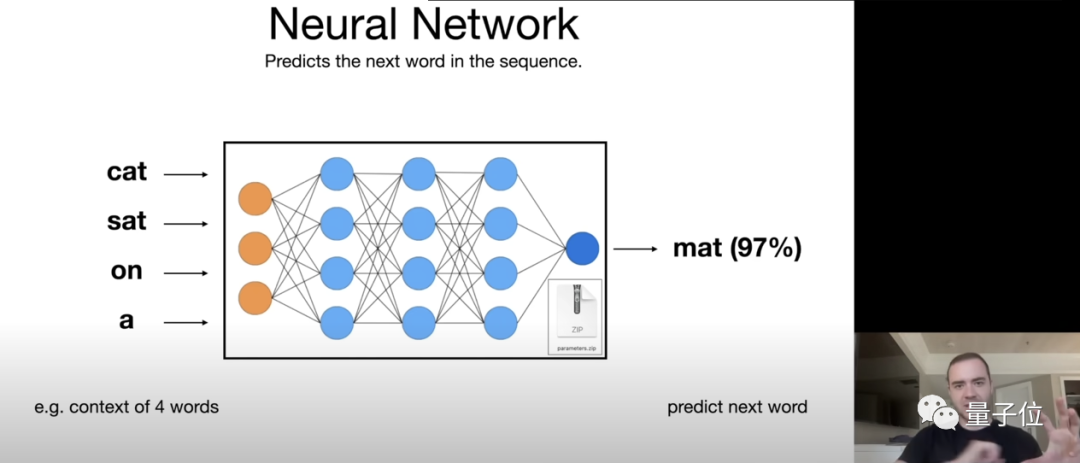
需要注意的是,由于前面提到训练是一种有损压缩,神经网络给出的东西是不能保证100%准确的。
Andrej管大模型推理为“做梦”,它有时可能只是简单模仿它学到的内容,然后给出一个大方向看起来对的东西。
这其实就是幻觉。所以大家一定要小心它给出的答案,尤其是数学和代码相关的输出。
接下来,由于我们需要大模型成为一个真正有用的助手,就需要进行第二遍训练,也就是微调。
微调强调质量大于数量,不再需要一开始用到的TB级单位数据,而是靠人工精心挑选和标记的对话来投喂。
不过在此,Andrej认为,微调不能解决大模型的幻觉问题。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

