

每周编辑精选 Weekly Edito
大模型巅峰对决开启,Gemini和GPT-4展开大pk!代码和数学Gemini惨遭GPT-4碾压,但要论讲笑话和写作,它的答案却意外的好笑。
原文来源:新智元

图片来源:由无界 AI生成
被谷歌寄予厚望的复仇杀器Gemini,是否能够如愿单挑ChatGPT?
最近几天,外媒记者和网友们纷纷放出实测,比较了Gemini Pro加持的新Bard与GPT-3.5和GPT-4的各项性能。
先说结果——ChatGPT略胜一筹,但Gemini进步巨大。
虽然宣传手段有一些夸大的成分,但谷歌确实靠Gemini在LLM大战中挽回了一些颓势。

而且,现在双方都还捂着杀手锏没有放出来,真正的巅峰对决,恐怕要等Gemini Ultra或者集成了OpenAI神秘Q*技术的新模型出场后了。
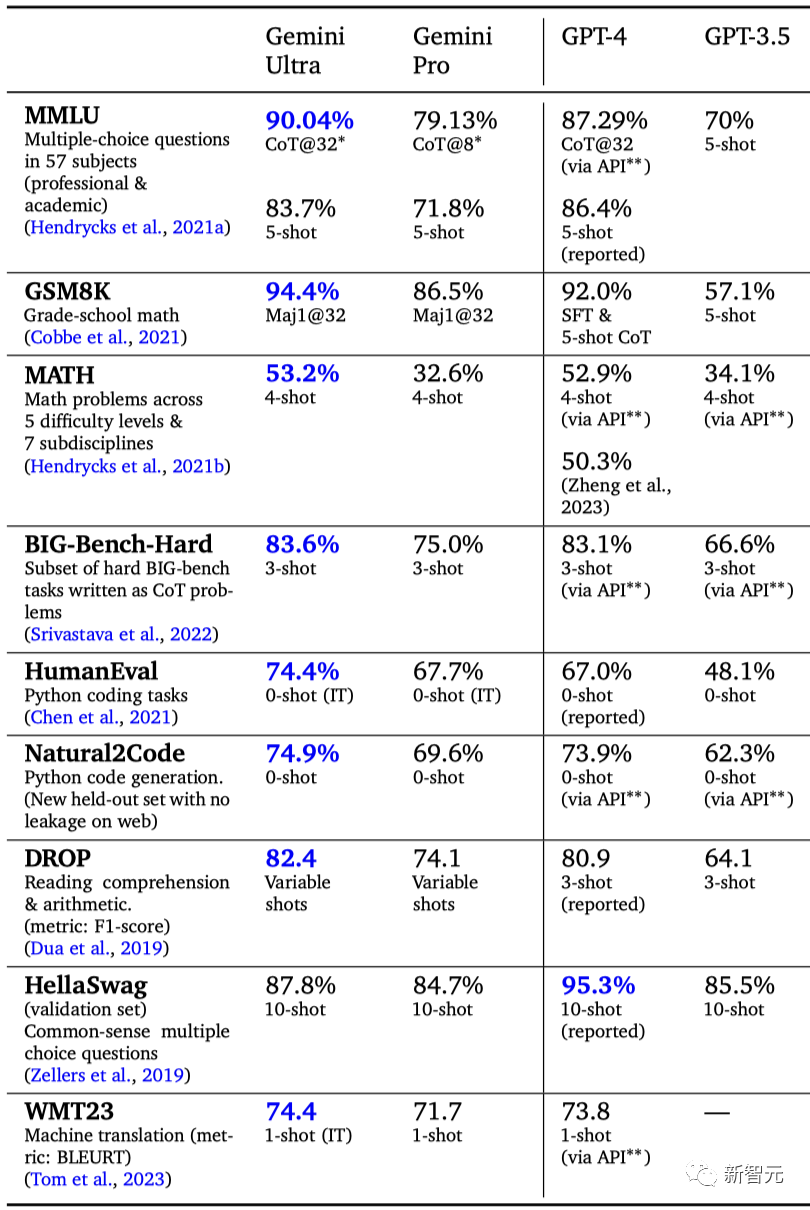
需要强调的是,此次出战的选手Gemini Pro只是「二弟」,因为号称「在32个广泛使用的学术基准测试中击败GPT-4」的老大哥Gemini Ultra还未放出。
而且,由于目前只有纯文本提示用上了Gemini Pro。
所以,Bard暂时还没有得到加持的图像理解能力,依然很拉跨……
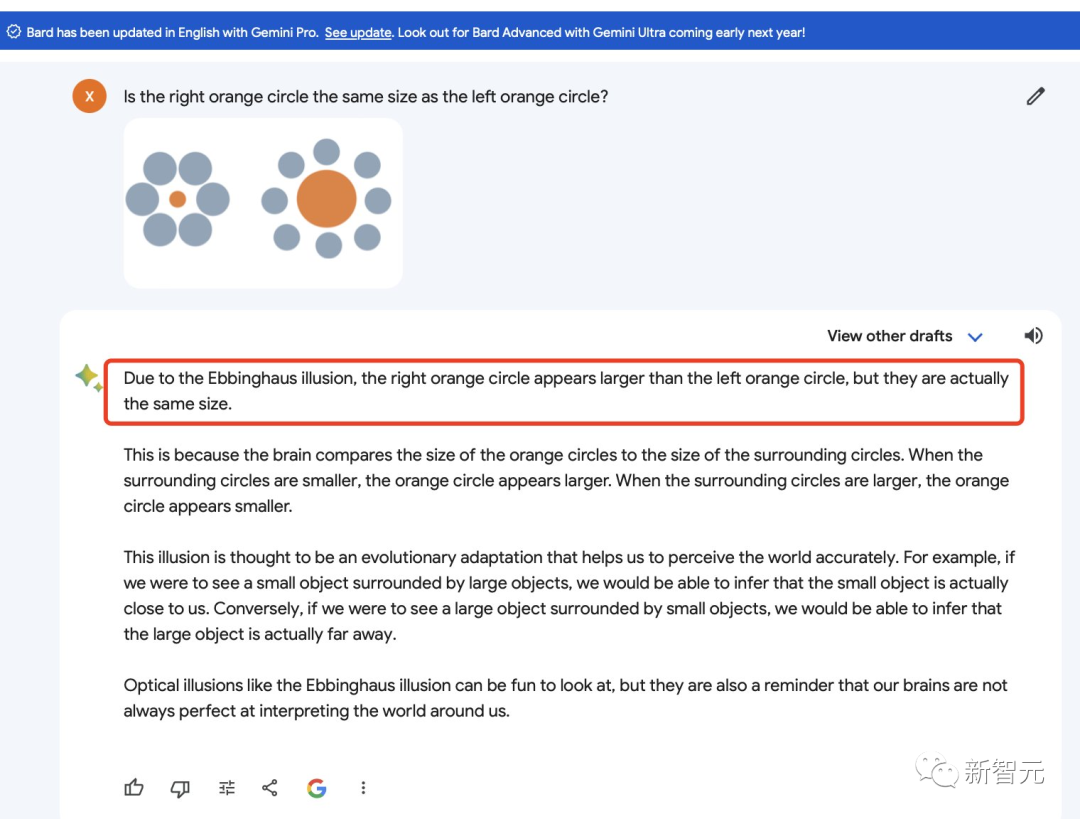
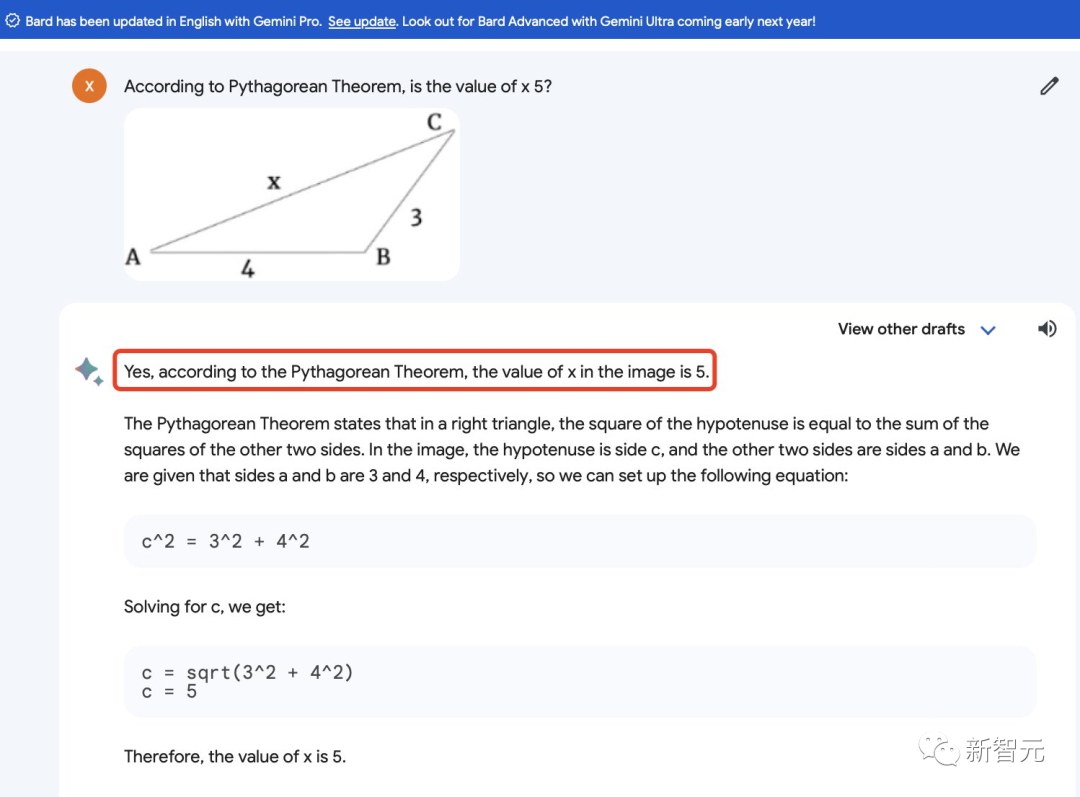
来源:马里兰大学博士生Fuxiao Liu
早在4月,就有许多人做过PaLM支持的Bard和GPT-4的pk,当时的结果是GPT-4七局五胜,略胜Bard一筹。
这次对决中,也考虑进了Bard在四月的结果,因此可以用来衡量几个月来谷歌的进步速度。
这些测试虽不够全面,但也提供了一个很好的基准,可以用来判断这些AI聊天助手在普通用户日常任务中的表现。
话不多说,现在开始!
既然谷歌这次大吹特吹了全新的AlphaCode 2,那我们首先就来看看它们的编程水平如何。

题目:Write a Python script that says "Hello World," then creates a random repeating string of characters endlessly.
编写一个Python脚本,在其中输入「Hello World」,然后不停地随机创建一个重复字符串。
PaLM Bard的答案:
首先,初代的Bard非常简陋,并不能生成代码。
不过,谷歌后来在6月的时候,给它加上了这个功能。(但并没有针对这个题目进行过测试)
Gemini Pro Bard的答案:
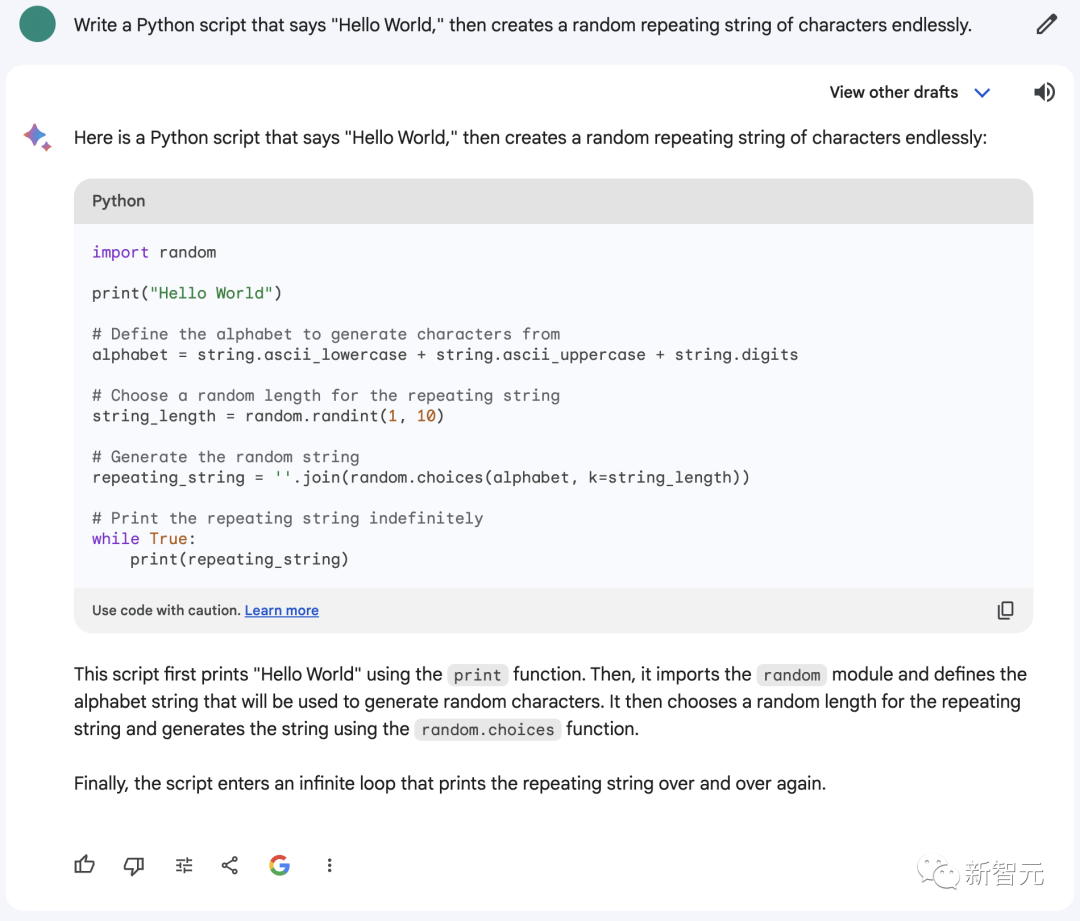
可以看到,新版Bard生成的代码没什么大问题,但需要在前面添加一个import string才能运行。
好在,这个bug很容易解决。
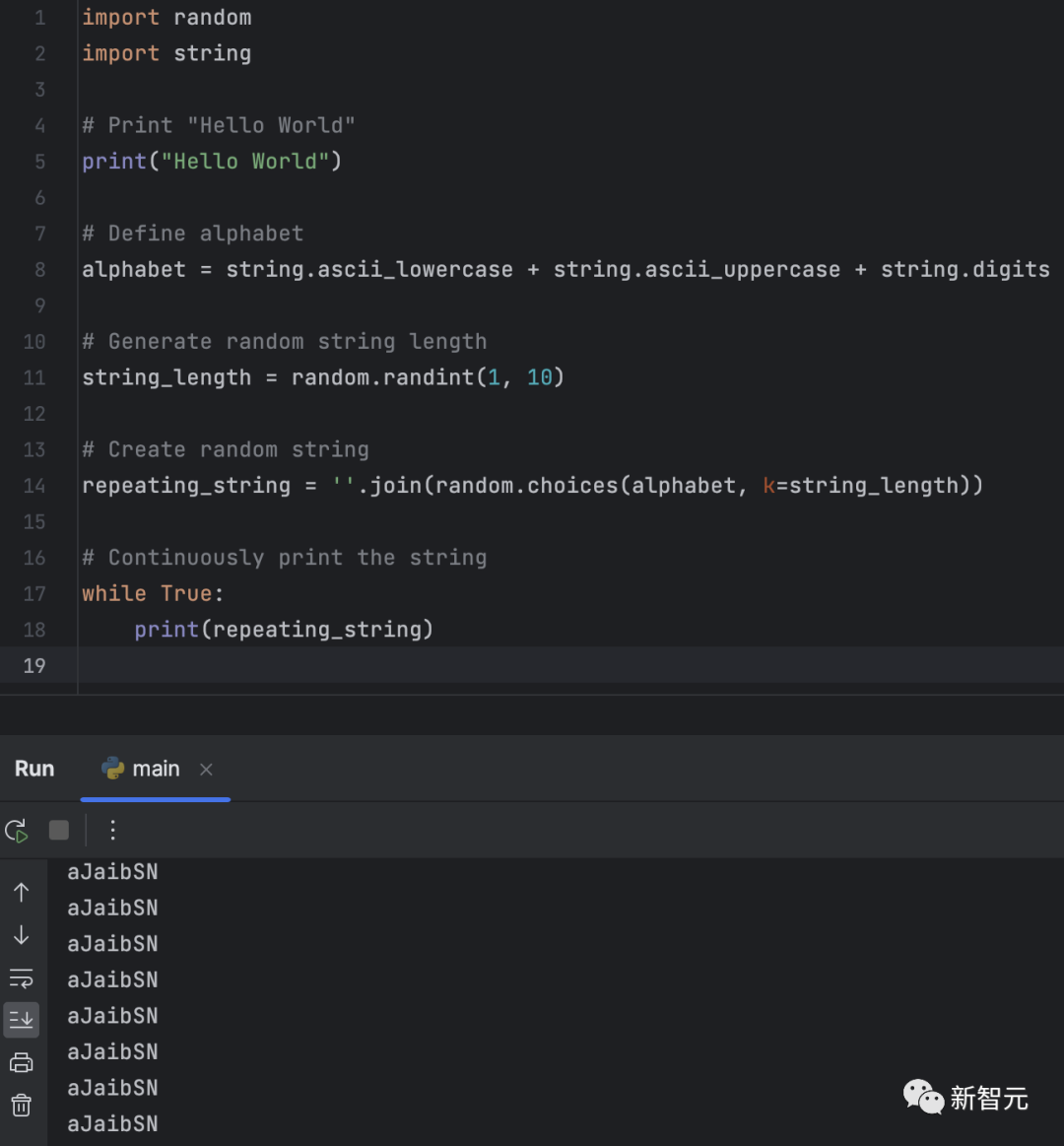
然而,不知道是因为好奇网友太多导致负荷超载,还是系统本身就不稳定。
针对这道题,Bard在大部分时候都会先「沉默」30秒,然后返回错误提示:「抱歉,出了点岔子,Bard目前还处在试验阶段」。

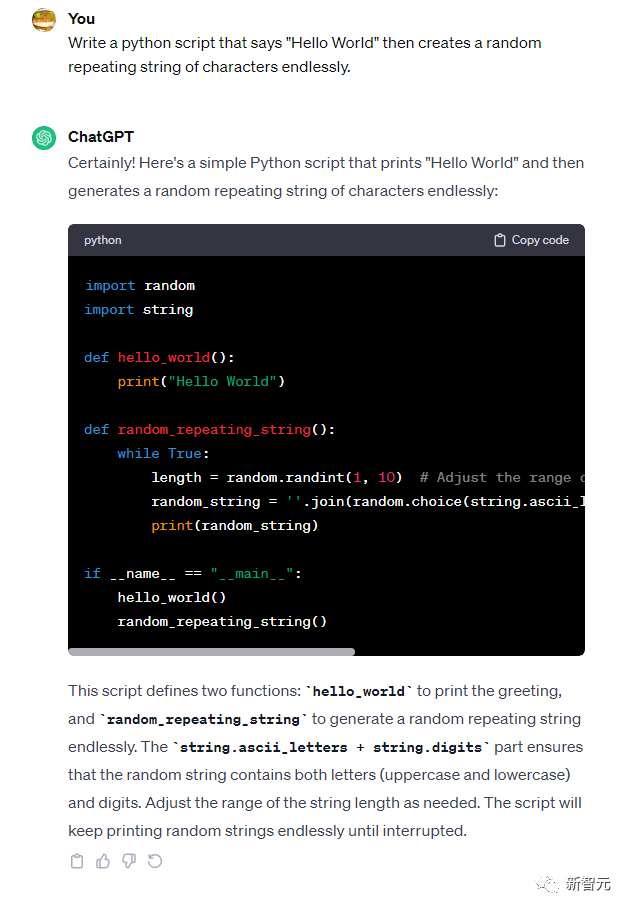
GPT-3.5的答案:
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

