

游戏开发商Nexon将为其链游
谷歌的 Gemini 到底几斤几两?和 OpenAI 的 GPT 模型相比表现如何?CMU 这篇论文测明白了。
原文来源:机器之心

图片来源:由无界 AI生成
前段时间,谷歌发布了对标 OpenAI GPT 模型的竞品 ——Gemini。这个大模型共有三个版本 ——Ultra(能力最强)、Pro 和 Nano。研究团队公布的测试结果显示,Ultra 版本在许多任务中优于 GPT4,而 Pro 版本与 GPT-3.5 不相上下。
尽管这些对比结果对大型语言模型研究具有重要意义,但由于确切的评估细节和模型预测尚未公开,这限制了对测试结果的复现、检测,难以进一步分析其隐含的细节。
为了了解 Gemini 的真正实力,来自卡内基梅隆大学、BerriAI 的研究者对该模型的语言理解和生成能力进行了深入探索。
他们在十个数据集上测试了 Gemini Pro、GPT 3.5 Turbo、GPT 4 Turbo、Mixtral 的文本理解和生成能力。具体来说,他们在 MMLU 上测试了模型回答基于知识的问题的能力,在 BigBenchHard 上测试了模型的推理能力,在 GSM8K 等数据集中测试了模型解答数学问题的能力,在 FLORES 等数据集中测试了模型的翻译能力;在 HumanEval 等数据集中测试了模型的代码生成能力;在 WebArena 中测试了模型作为遵循指令的智能体的能力。
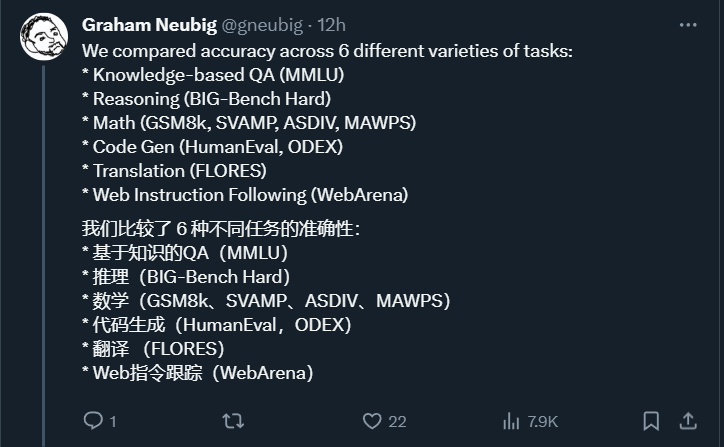
下表 1 展示了对比的主要结果。总体而言,截至论文发稿日,在所有任务中,Gemini Pro 在准确性上接近 OpenAI GPT 3.5 Turbo,但仍然稍逊一筹。此外,他们还发现,Gemini 和 GPT 比开源竞品模型 Mixtral 表现要好一些。
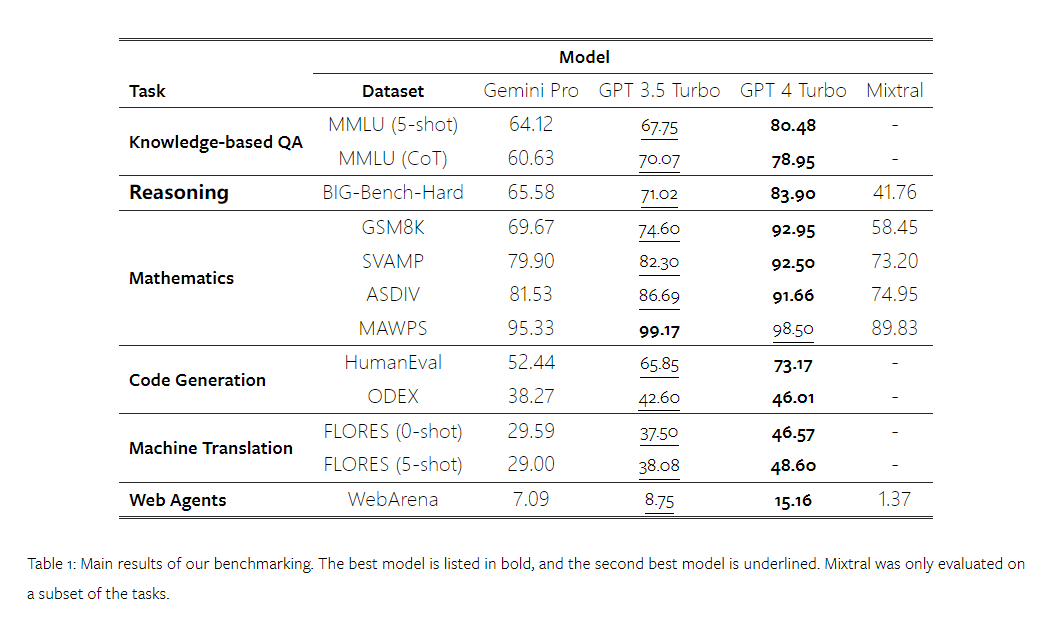
在论文中,作者对每项任务都进行了深入的描述和分析。所有结果和可复现的代码可参阅:https://github.com/neulab/gemini-benchmark

论文链接:https://arxiv.org/pdf/2312.11444.pdf
实验设置
作者选择了 Gemini Pro、GPT 3.5 Turbo、GPT 4 Turbo、Mixtral 四个模型作为测试对象。
由于此前有研究在评估时存在实验设置方面的差异,为确保测试公平,作者采取了完全相同的提示词和评估协议重新运行了实验。在大多数测评中,他们采用了提示词和来自标准资源库的评价标准。这些测试资源来自模型发布时附带的数据集以及测评工具 Eleuther 等。其中,提示词通常包含查询、输入、少量示例和思维链推理等。在某些特殊测评中,作者发现有必要对标准实践进行小幅调整。调整偏差已在对应的代码储存库中执行,请查阅论文原文。
这项研究的目标如下:
1. 通过可复现的代码和完全透明的结果,提供对 OpenAI GPT 和 Google Gemini 模型能力的第三方客观比较。
2. 深入研究测评结果,分析两个模型在哪些领域中的表现更加突出。
基于知识的问答(Knowledge-based QA)
作者从 MMLU 数据集中选择了 57 个基于知识的多项选择问答任务,涵盖了 STEM 以及人文社科等各种主题。MMLU 共有 14,042 个测试样本,已经广泛用于对大型语言模型的知识能力进行整体评估。
作者比较并分析了四个测试对象在 MMLU 上的整体表现(如下图所示)、子任务表现以及输出长度对表现的影响。
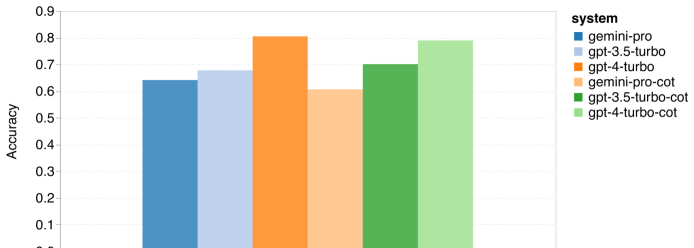
图 1:使用 5 个样本提示和思维链提示,各个模型在 MMLU 上的总体准确率。
从图中可以看到,Gemini Pro 的准确性低于 GPT 3.5 Turbo,并且远低于 GPT 4 Turbo。在使用思维链提示时,各模型表现差异不大。作者推测这是由于 MMLU 主要收录的是基于知识的问答任务,这些任务可能不会从更强的推理导向提示中显著受益。
值得注意的是,MMLU 中的所有问题都是单选题,有 A 到 D 四个按顺序排列的潜在答案。下图中展示了每个模型选择每个答案选项的比例。从图中可以看到 Gemini 的答案分布非常倾斜,偏向于选择最后的 D 选项。这与各版本的 GPT 给出的更加平衡的结果形成了对比。这可能表明,Gemini 没有接受与多选题相关的大量指令调整,导致模型在答案排序方面存在偏见。
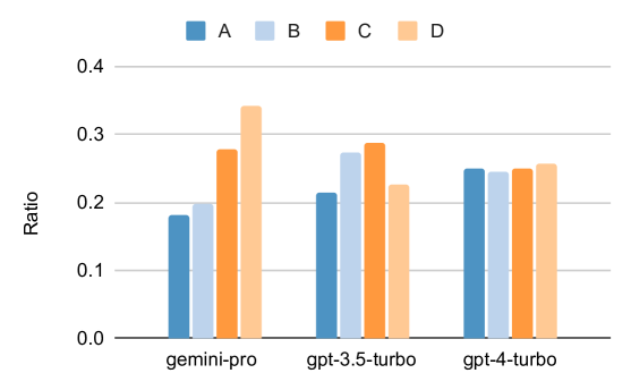
图 2:被测模型预测的单选题答案的比例。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

