

以太坊2024路线图:6大主题
原文来源:量子位

图片来源:由无界 AI生成
一个来自MIT博士生的惊人发现:
只需对Transformer的特定层进行一种非常简单的修剪,即可在缩小模型规模的同时显著提高模型性能。

效果主要体现在文本理解任务上,最高可达30%。
这在3个模型(LLama2、GPT-J和Roberta)和8个不同数据集上都得到了验证(包含认知推理、世界知识等)。
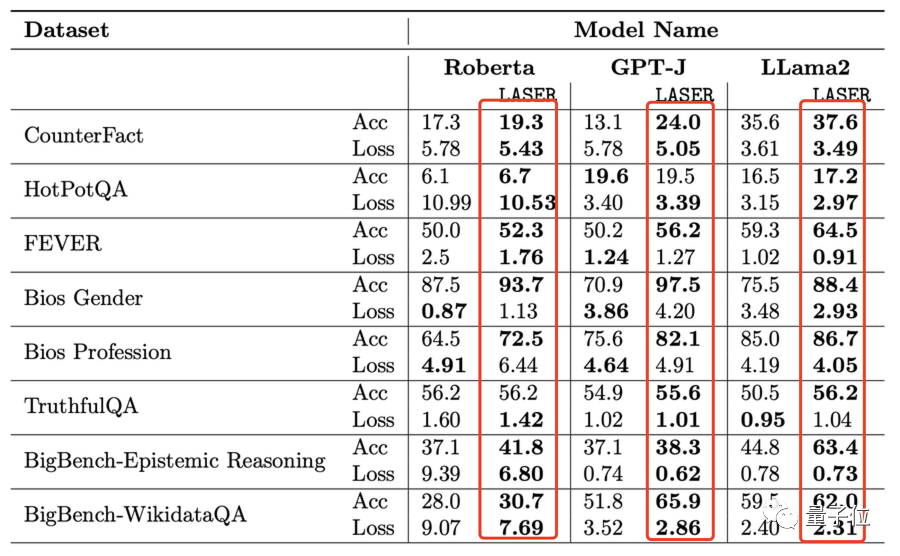
除了文本理解,它也适用于强化学习。
当然,更重要的是,这个操作只需在模型训练完成之后进行,不需要额外的参数和数据。
DeepMind研究科学家看完都来点赞了:

那么,它具体怎么做的?
方法概述
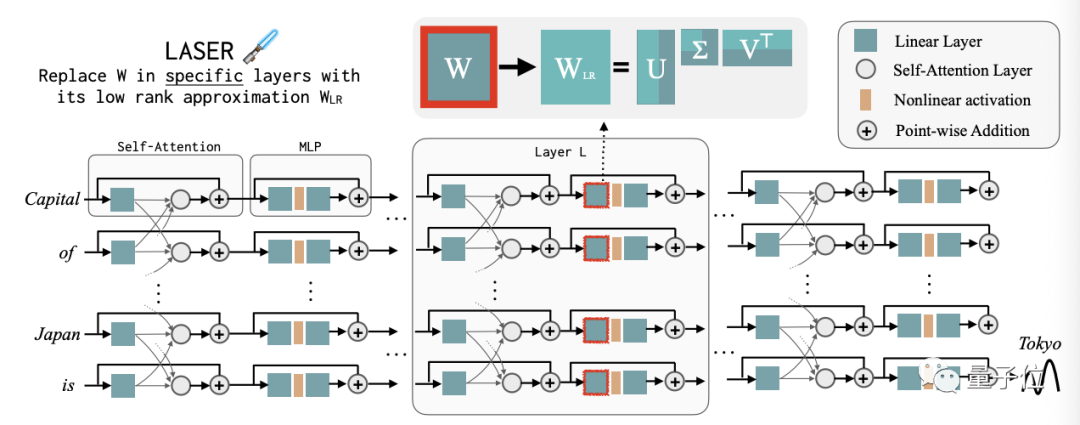
该方法全称“ Layer-Selective Rank Reduction”,简称“LASER”。
这是一种选择性地去除LLM权重矩阵高阶组件(components)的干预措施,操作就在Transformer模型的特定权重矩阵和层中进行。
研究发现,即使完全去除90%以上,模型性能一般也不会下降。
具体而言,LASER通过rank-k近似来替换Transformer模型中的特定权重矩阵(W),有时仅减少包含前1%组件的矩阵,也能达到不错的效果。
一个单步LASER干预措施包含三个参数:
类型(T)、层号(ℓ )和降秩(ρ,全称rank reduction)。
这些值组合在一起描述哪个矩阵将被其低阶近似所取代,以及近似的程度。
其中参数类型对我们将要干预的矩阵进行分类,而矩阵W来自MLP和注意力层。
层号表示我们要介入的层(第一层从0开始索引)。比如Llama-2有32层,因此ℓ ∈{0,1,2,···31}。
最后,ρ∈[0,1)描述在进行低秩近似时应该保留最大秩的分数。
下图为LASER操作的一个示例,它更新的是第L层Transformer块中MLP的第一层权重矩阵。
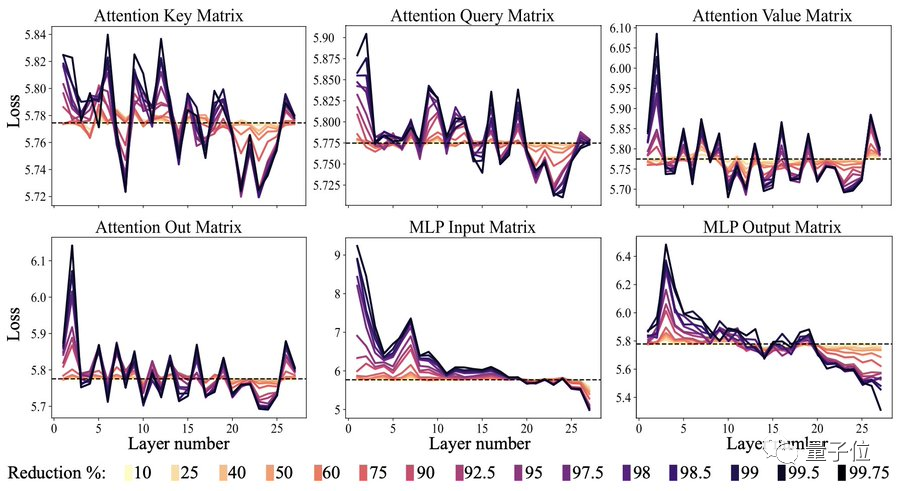
实验发现:
不同层类型之间的降秩效果并不统一,主要可在MLP层的后续transformer块中执行LASER操作观察到,在注意力层中则很微弱。
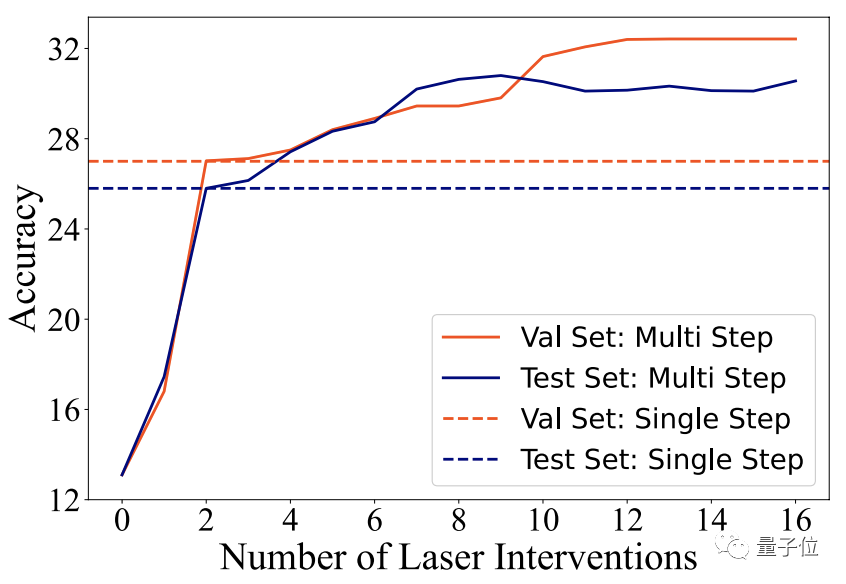
同时,如果我们一气儿在多个层上执行LASER还可以进一步增强模型性能,超越单层所带来的改进。
具体而言,有时可以超过模型原始性能的2倍。
除了最高可提升模型30%的文本理解性能,它还对强化学习有效。
在此,作者评估了LASER对一个训练和评估Sokoban游戏(通过移动块推入洞中)的决策transformer模型的影响。
结果发现,有了LASER,模型可以多解决3%的任务。

原因分析
为什么这样一个简单操作就能带来模型性能如此的提升?
作者用GPT-J模型的结果来分析(选该模型主要是该它的训练数据DT rain是公开的),即通过计算训练数据中“纠正事实”发生的频率,来弄清究竟是哪些数据点从中受益。
结果发现,性能最大的提升发生在低频样本上。
如下图所示c,条形图显示了LASER为数据提供的提升量,准确性的最大改进来自于训练数据中出现频率较低的数据点。
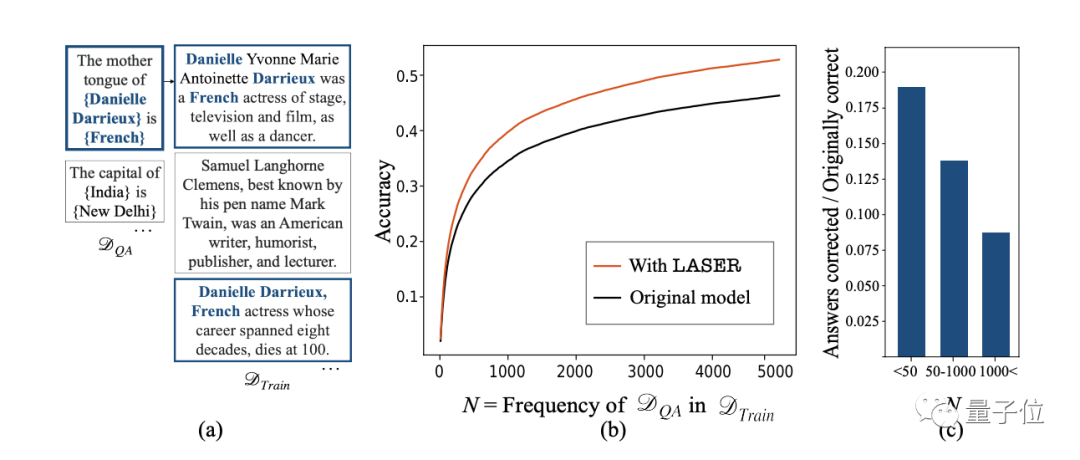
作者解释,这很明显,消除高阶组件“去噪”了模型,并有助于恢复隐藏的、频率较低的信息。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

