

以太坊2024路线图:6大主题
原文来源:新智元

图片来源:由无界 AI生成
2023年的LLM开源社区都发生了什么?来自Hugging Face的研究员带你回顾并重新认识开源LLM
2023年的大语言模型(LLM),让几乎所有人都燃起了热情。
现在大多数人都知道LLM是什么,以及可以做什么。
人们讨论着它的优缺点,畅想着它的未来,
向往着真正的AGI,又有点担忧自己的命运。
围绕开源与闭源的公开辩论也吸引了广泛的受众。
2023年的LLM开源社区都发生了什么?

下面,让我们跟随Hugging Face的研究员Clémentine Fourrier一起,
回顾一下开源LLM这跌宕起伏的一年。
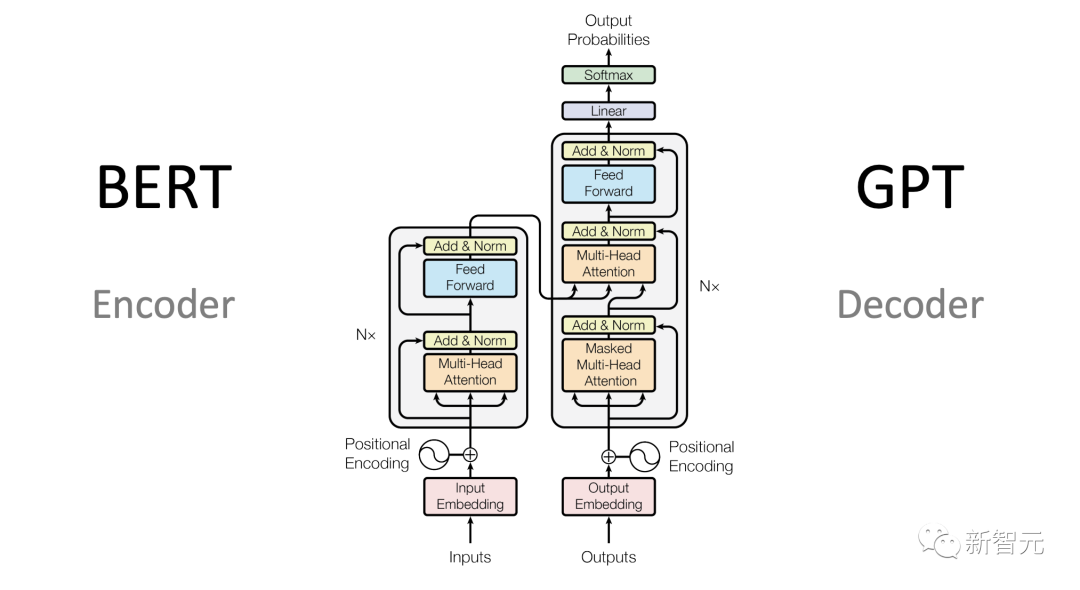
如何训练大语言模型?
LLM的模型架构描述了具体实现和数学形状。模型是所有参数的列表,以及参数如何与输入交互。
目前,大多数高性能的LLM都是Transformer架构的变体。
LLM的训练数据集,包含训练模型所需的所有示例和文档。
大多数情况下是文本数据(自然语言、编程语言、或者其他可表达为文本的结构化数据)。
分词器(tokenizer)定义如何将训练数据集中的文本转换为数字(因为模型本质上是一个数学函数)。
文本被切分成称为tokens的子单元(可以是单词、子单词或字符)。
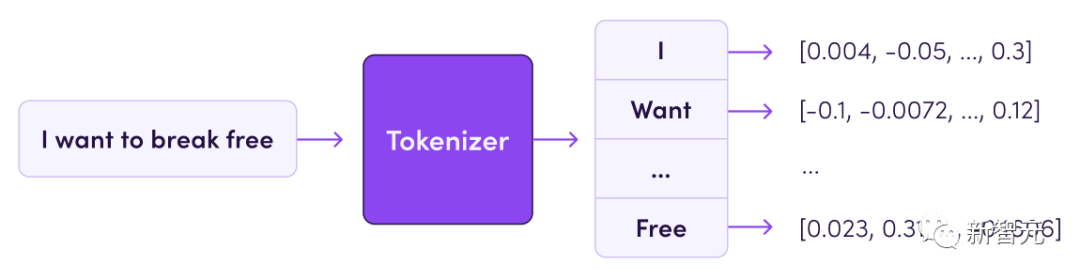
分词器的词汇量通常在32k到200k之间,而数据集的大小通常以它包含的tokens数量来衡量,当今的数据集可以达到几千亿到几万亿个tokens。
然后,使用超参数定义如何训练模型——每次迭代,参数应该改变多少?模型的更新速度应该有多快?
搞定这些后,剩下的就只需要:大量的算力,以及训练过程中进行监控。
训练的过程包括实例化架构(在硬件上创建矩阵),并使用超参数在训练数据集上运行训练算法。
最终得到的结果是一组模型权重,——大家讨论的大模型就是这个东西。
这组权重可以用来推理,对新的输入预测输出、生成文本等。
上面训练好的LLM也可以在之后通过微调(fine-tuning)来适应特定任务(尤其是对于开源模型)。
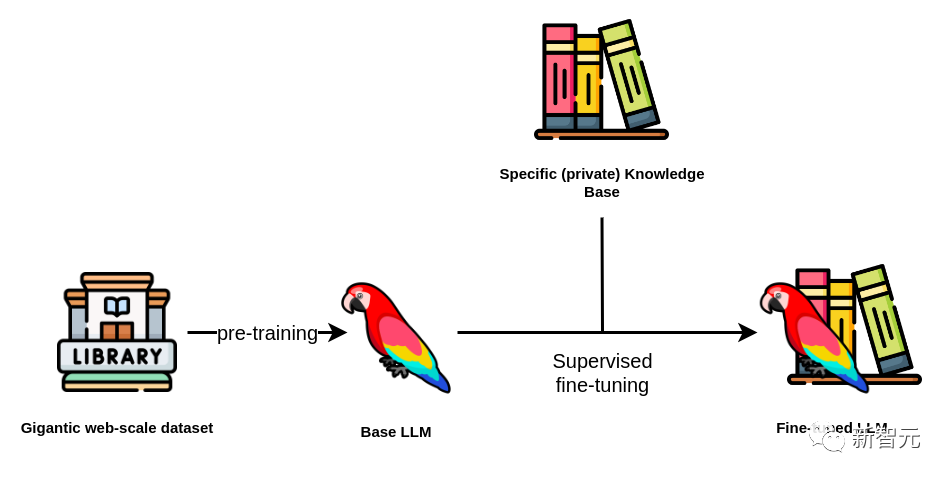
微调的过程是在不同的数据集(通常更专业、更小)上对模型进行额外的训练步骤,以针对特定应用程序进行优化。
比起从头开始训练一个大模型,微调的成本显然低得多——这也是开源LLM受到大家欢迎的原因之一。
从规模竞赛到数据竞赛
直到2022年初,机器学习的趋势是模型越大,性能就越好。
而且似乎模型的大小在超过某个阈值之后,能力会得到飞跃——有两个词语用来描述这个现象:emergent abilities和scaling laws 。
2022年发布的预训练开源模型大多遵循这种范式,下面举几个例子。
BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)是BigScience发布的一系列模型,由Hugging Face与法国组织GENCI和IDRIS合作,涉及来自60个国家和250个机构的1000名研究人员。这些模型使用decoder-only transformers,并进行了微小的修改。
系列中最大的模型有176B参数,使用350B的训练数据集,包括46种人类语言和13种编程语言,是迄今为止最大的开源多语言模型。
OPT(Open Pre-trained Transformer)系列模型由Meta发布,遵循GPT-3论文的技巧(特定权重初始化、预归一化),对注意力机制(交替密集和局部带状注意力层)进行了一些更改。

这个系列中最大的模型为175B,在180B的数据上进行训练,数据主要来自书籍、社交、新闻、维基百科和互联网上的其他信息。
OPT的性能与GPT-3相当,使用编码优化来降低计算密集度。
GLM-130B(通用语言模型)由清华大学和Zhipu.AI发布。它使用完整的transformer架构,并进行了一些更改(使用DeepNorm进行层后归一化、旋转嵌入)。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

