

BTC ETF截止日到来:SEC已收
文章来源:新智元

图片来源:由无界 AI生成
GPT-5何时到来,会有什么能力?
来自艾伦人工智能研究所(Allen Institute for AI)的新模型告诉你答案。
艾伦人工智能研究所推出的Unified-IO 2是第一个可以处理和生成文本、图像、音频、视频和动作序列的模型。
这个新的高级人工智能模型使用几十亿个数据点进行训练,虽然模型大小只有7B,却展现出迄今为止最广泛的多模态能力。

论文地址:https://arxiv.org/pdf/2312.17172.pdf
那么,Unified-IO 2和GPT-5有什么关系呢?
早在2022年6月,艾伦人工智能研究所就推出了第一代Unified-IO,它是首批能够处理图像和语言的多模态模型之一。
大约在同一时间,OpenAI正在内部测试GPT-4,并在2023年3月正式发布。
所以,Unified-IO可以看作是对于未来大规模AI模型的前瞻。
也就是说,OpenAI可能正在内部测试GPT-5,并将在几个月后发布。
而本次Unified-IO 2向我们展现的能力,也将是我们在新的一年可以期待的内容:
GPT-5等新的AI模型可以处理更多模态,通过广泛的学习以本地方式执行许多任务,并且对与物体和机器人的交互有基本的了解。
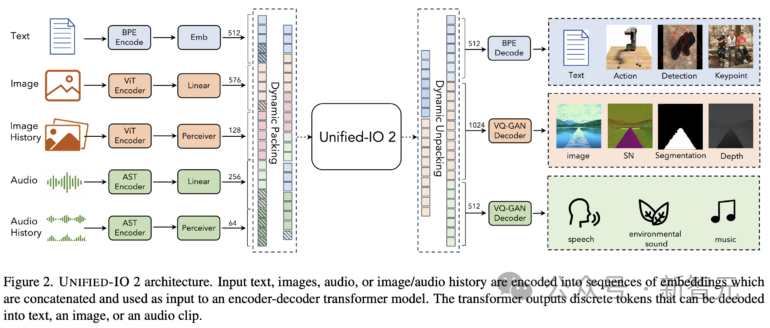
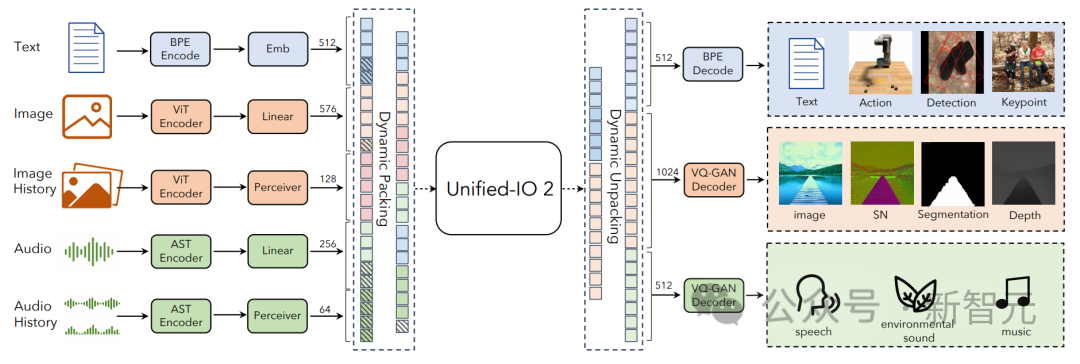
Unified-IO 2的训练数据包括:10亿个图像-文本对、1 万亿个文本标记、1.8亿个视频剪辑、1.3亿张带文本的图像、300万个3D资产和100万个机器人代理运动序列。
研究团队将总共120多个数据集组合成一个600 TB的包,涵盖220个视觉、语言、听觉和动作任务。
Unified-IO 2采用编码器-解码器架构,并进行了一些更改,以稳定训练并有效利用多模态信号。
模型可以回答问题、根据指令撰写文本、以及分析文本内容。
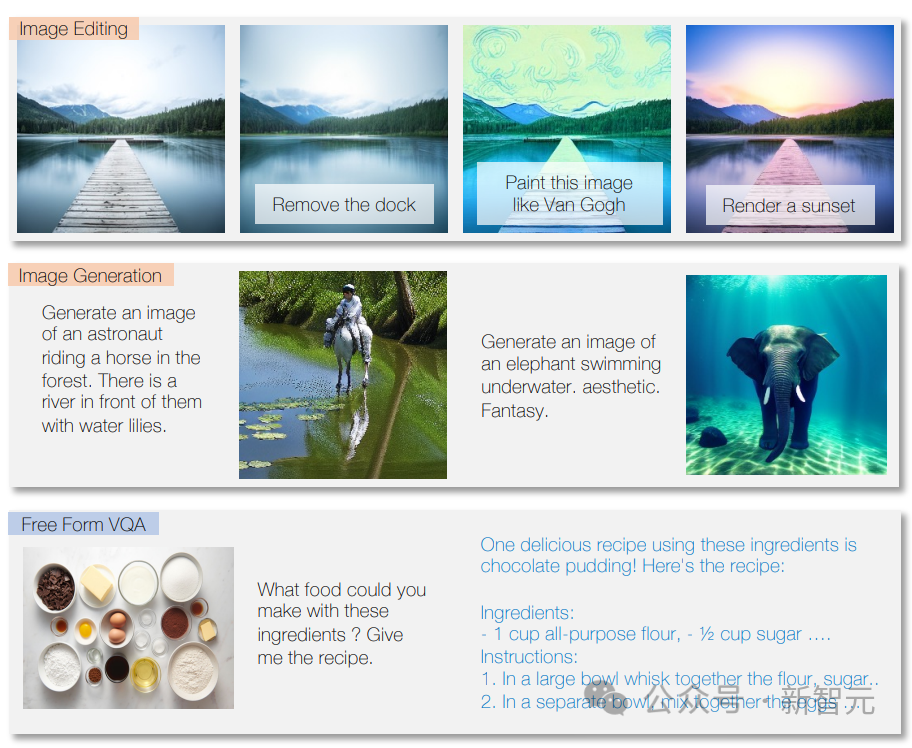
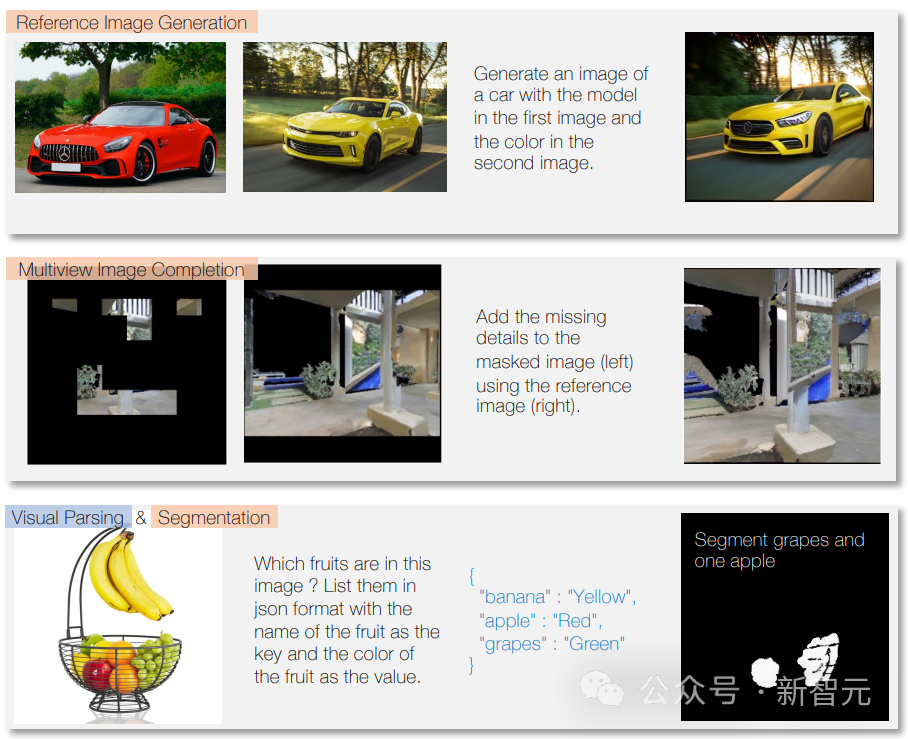
模型还可以识别图像内容,提供图像描述,执行图像处理任务,并根据文本描述创建新图像。
它还可以根据描述或说明生成音乐或声音,以及分析视频并回答有关视频的问题。

通过使用机器人数据进行训练,Unified-IO 2还可以为机器人系统生成动作,例如将指令转换为机器人的动作序列。
由于多模态训练,它还可以处理不同的模态,例如,在图像上标记某个音轨使用的乐器。

Unified-IO 2在超过35个基准测试中表现良好,包括图像生成和理解、自然语言理解、视频和音频理解以及机器人操作。
在大多数任务中,它能够比肩专用模型,甚至更胜一筹。
在图像任务的GRIT基准测试中,Unified-IO 2获得了目前的最高分(GRIT用于测试模型如何处理图像噪声和其他问题)。
研究人员现在计划进一步扩展Unified-IO 2,提高数据质量,并将编码器-解码器模型,转换为行业标准的解码器模型架构。
Unified-IO 2是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。
为了统一不同的模态,研究人员将输入和输出(图像、文本、音频、动作、边界框等)标记到一个共享的语义空间中,然后使用单个编码器-解码器转换器模型对其进行处理。
由于训练模型所采用的数据量庞大,而且来自各种不同的模态,研究人员采取了一系列技术来改进整个训练过程。
为了有效地促进跨多种模态的自监督学习信号,研究人员开发了一种新型的去噪器目标的多模态混合,结合了跨模态的去噪和生成。
还开发了动态打包,可将训练吞吐量提高4倍,以处理高度可变的序列。
为了克服训练中的稳定性和可扩展性问题,研究人员在感知器重采样器上做了架构更改,包括2D旋转嵌入、QK归一化和缩放余弦注意力机制。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

