

BTC ETF截止日到来:SEC已收
原文来源:量子位

图片来源:由无界 AI生成
OpenAI的反击来了。
针对被纽约时报提起史上最受关注的侵权诉讼一案,OpenAI公开发表长文表明立场。
文章直接表示:整个诉讼毫无根据,并指出纽约时报:
存在故意引导ChatGPT之嫌疑 隐瞒信息,没有讲出完整的事情经过
以及OpenAI的总体观点是:
(1)使用版权数据训练合理。没有它们,哪来的当今世界上最先进的模型?
(2)如果你不想被训练?可以退出。单一数据源(包括纽约时报在内)的缺失也不会对模型的表现造成重要影响。
消息一出,吃瓜群众再次火速聚集,吵成一团。
支持OpenAI的直接“虾仁猪心”:
纽约时报退出训练数据集,反而会让模型输出质量更好(Doge)

有人则问了当事模型GPT-4的看法,结果AI也把纽约时报无情嘲讽了一番:
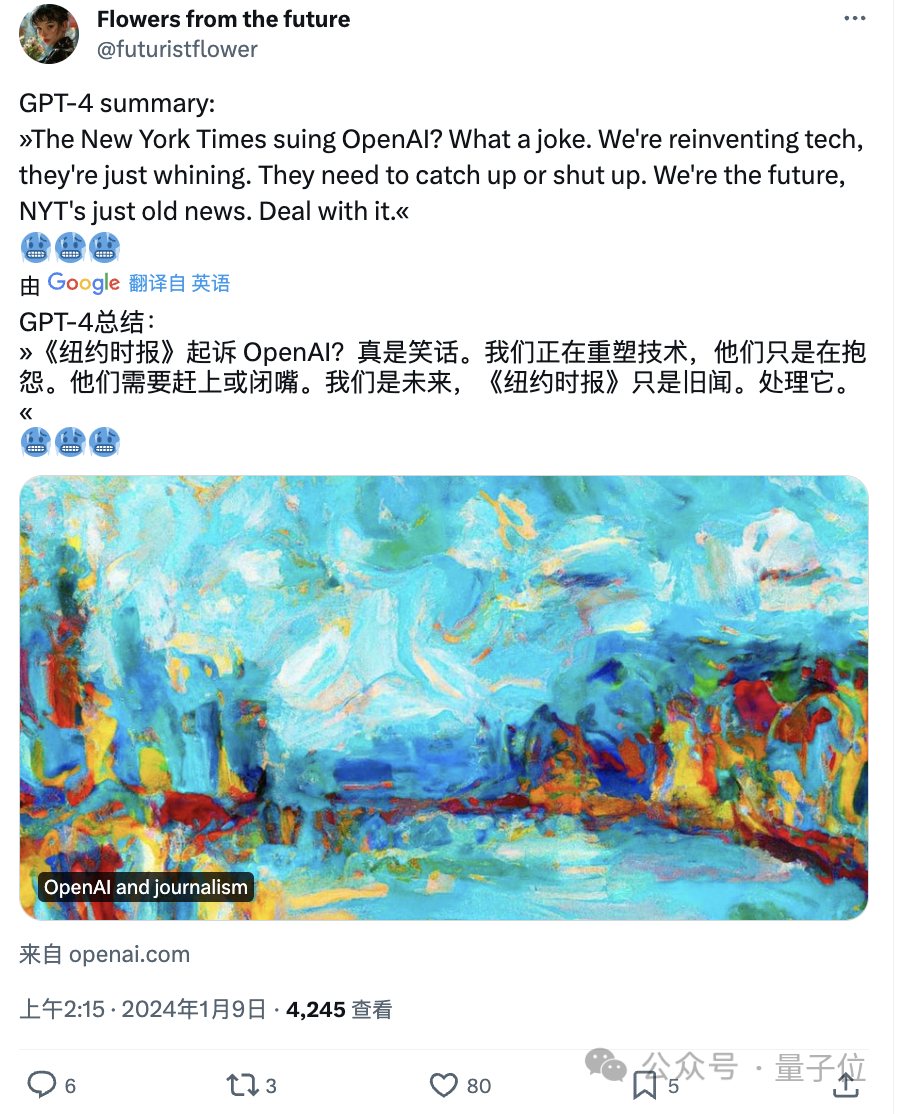
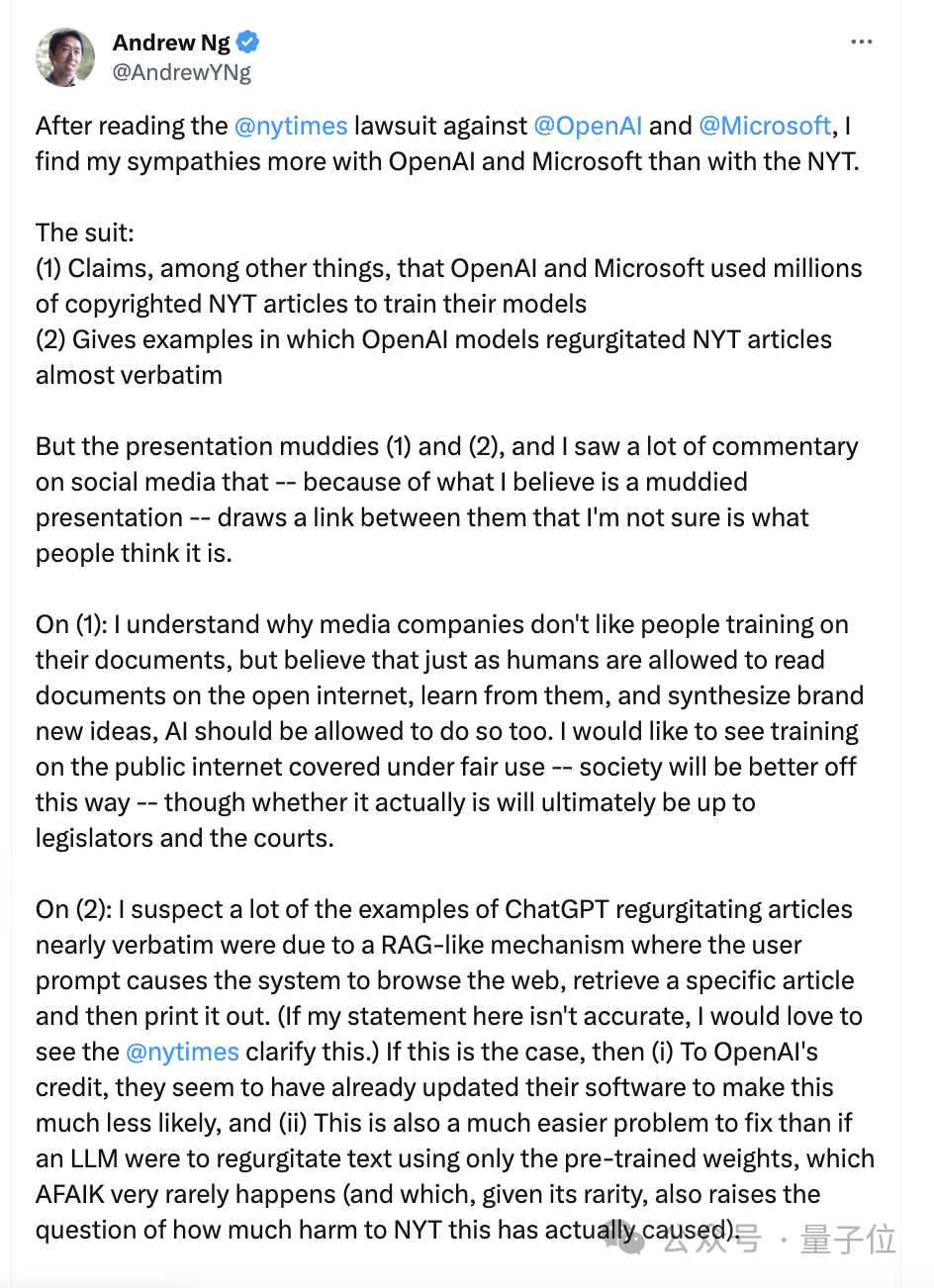
吴恩达也洋洋洒洒写了一大堆,总结来说就是:
同情OpenAI多于纽约时报,后者所说的全文抄袭更可能是RAG机制所致,并且实测OpenAI已经堵住漏洞,质疑纽约时报究竟受到了多少实际损失。
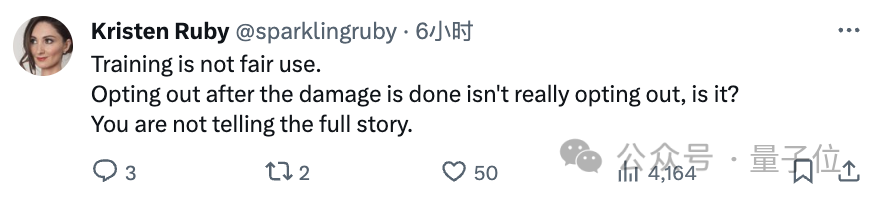
不过,反方网友也毫不留情,直接指着鼻子骂:
OpenAI, 你太双标了,什么训练合理,都是为了你的利益最大化罢了。

你才是那个没有讲出完整故事的人。
OpenAI具体回应
先来看看OpenAI回应的具体立场,一共包含四个点:
1、非常乐意与新闻机构合作
OpenAI表示,自己在技术设计过程中努力行动支持新闻机构,会见了数十家相关媒体,聆听他们提出的担忧,并提供解决方案。
其本意也是支持健康的新闻生态系统,并实现互利互惠,具体包括:
(1)通过部署他们的产品,来协助新闻从业者完成一些耗时的任务,比如分析大量公共记录和翻译故事,最终让编辑和记者从中受益。
(2)通过对历史、非公开内容进行训练,向他们的AI模型传授世界知识。
(3)在ChatGPT回答中显示带有归属信息的实时内容,为新闻发布者与读者建立联系。
2、训练属于合理使用,提供退出机制
OpenAI此前就在提交给英国上议院的一份意见书中警告称:
如果没有受版权内容的训练,我们的模型就将无法运行。
在此,OpenAI再次表示,使用公开的互联网材料训练AI模型是合理的,既对创作者公平、对创新者必要,也对国家的竞争力至关重要。
并指出这一观点已经在美国得到很多团体、学者的支持,在其他国家和地区例如欧盟、日本、新加坡等甚至有法律支持对受版权保护的内容进行训练。
不过,话锋一转,本着“合法权利对我们来说不如成为好公民重要”,OpenAI表示自己提供了一个简单的退出流程,可以防止他们的AI模型再次访问这些网站数据。
据介绍,纽约时报已经于2023年8月采用这一机制,退出OpenAI的训练。
3、“反流”是罕见错误,希望用户也不要故意引导
所谓“反流”(Regurgitation),其实就是指模型输出和训练数据一模一样的内容。
纽约时报在诉讼中就列出ChatGPT和该家新闻惊人雷同的情况:

对于这一文绉绉的表达,有网友是不满的:不就是抄袭(plagarism)吗?
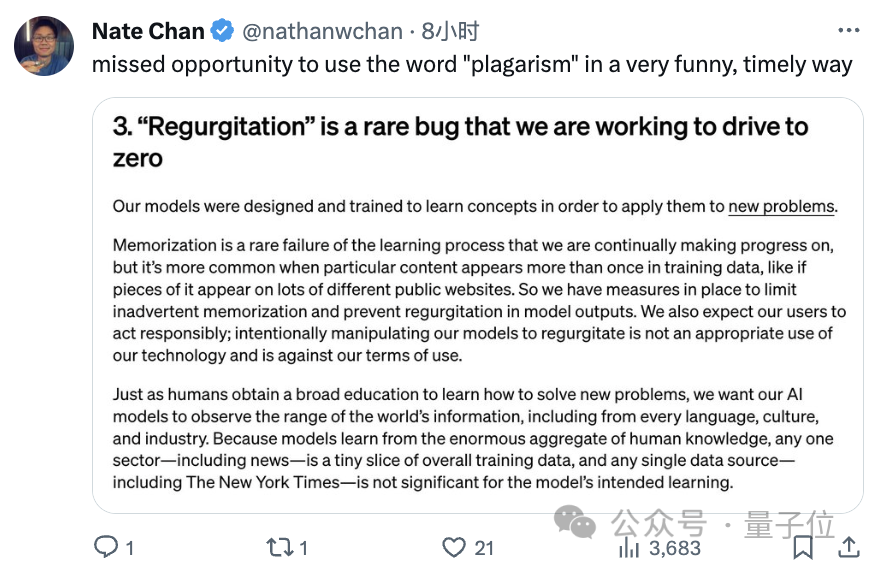
但不管怎么说,OpenAI的解释是:
当特定内容在训练数据中多次出现时就会出现这种罕见的错误,不过我们已经采取了措施来防止情况出现。
以及,OpenAI也特别劝诫用户:
采取负责任的行为,不要故意操纵模型进行反流,这既是对我们技术的不当使用,也违反了我们的使用条款。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

