

MEME季是否会来临?
原文来源:机器之心

图片来源:由无界 AI生成
还在苦苦寻找开源的机器人大模型?试试RoboFlamingo!
近年来,大模型的研究正在加速推进,它逐渐在各类任务上展现出多模态的理解和时间空间上的推理能力。机器人的各类具身操作任务天然就对语言指令理解、场景感知和时空规划等能力有着很高的要求,这自然引申出一个问题:能不能充分利用大模型能力,将其迁移到机器人领域,直接规划底层动作序列呢?
对此,ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作模型,只用单机就可以训练。使用简单、少量的微调就可以把 VLM 变成 Robotics VLM,从而适用于语言交互的机器人操作任务。
OpenFlamingo 在机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能。随着 RT-X 数据集开放,采用开源数据预训练 RoboFlamingo 并 finetune 到不同机器人平台,将有希望成为一个简单有效的机器人大模型 pipeline。论文还测试了各种不同 policy head、不同训练范式和不同 Flamingo 结构的 VLM 在 Robotics 任务上微调的表现,得到了一些有意思的结论。
 项目主页:https://roboflamingo.github.io
代码地址:https://github.com/RoboFlamingo/RoboFlamingo
论文地址:https://arxiv.org/abs/2311.01378
项目主页:https://roboflamingo.github.io
代码地址:https://github.com/RoboFlamingo/RoboFlamingo
论文地址:https://arxiv.org/abs/2311.01378
研究背景
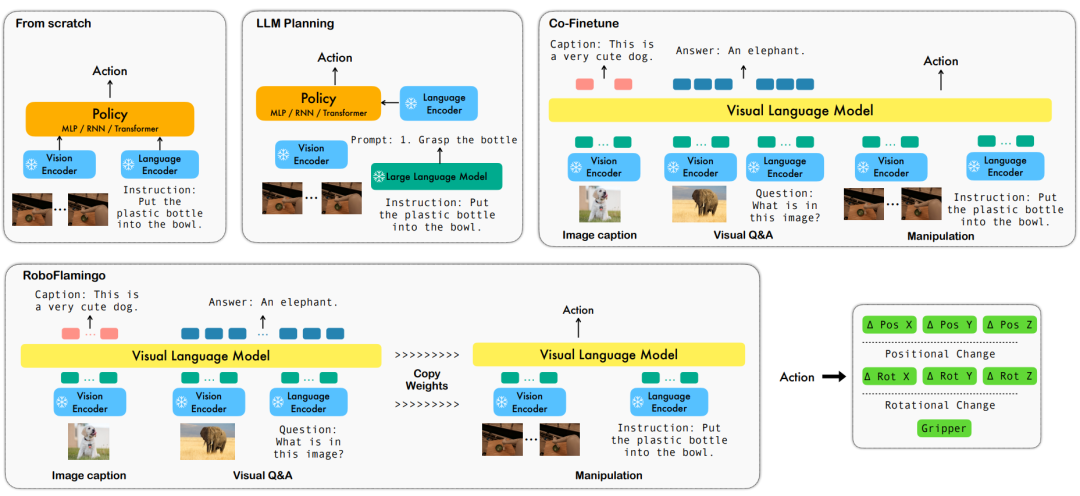
基于语言的机器人操作是具身智能领域的一个重要应用,它涉及到多模态数据的理解和处理,包括视觉、语言和控制等。近年来,视觉语言基础模型(VLMs)已经在多个领域取得了显著的进展,包括图像描述、视觉问答和图像生成等。然而,将这些模型应用于机器人操作仍然存在一些挑战,例如如何将视觉和语言信息结合起来,如何处理机器人操作的时序性等。
为了解决这些问题,ByteDance Research 的机器人研究团队利用现有的开源 VLM,OpenFlamingo,设计了一套新的视觉语言操作框架,RoboFlamingo。其中 VLM 可以进行单步视觉语言理解,而额外的 policy head 模组被用来处理历史信息。只需要简单的微调方法就能让 RoboFlamingo 适应于基于语言的机器人操作任务。
RoboFlamingo 在基于语言的机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能(多任务学习的 task sequence 成功率为 66%,平均任务完成数量为 4.09,基线方法为 38%,平均任务完成数量为 3.06;zero-shot 任务的成功率为 24%,平均任务完成数量为 2.48,基线方法为 1%,平均任务完成数量是 0.67),并且能够通过开环控制实现实时响应,可以灵活部署在较低性能的平台上。这些结果表明,RoboFlamingo 是一种有效的机器人操作方法,可以为未来的机器人应用提供有用的参考。
方法
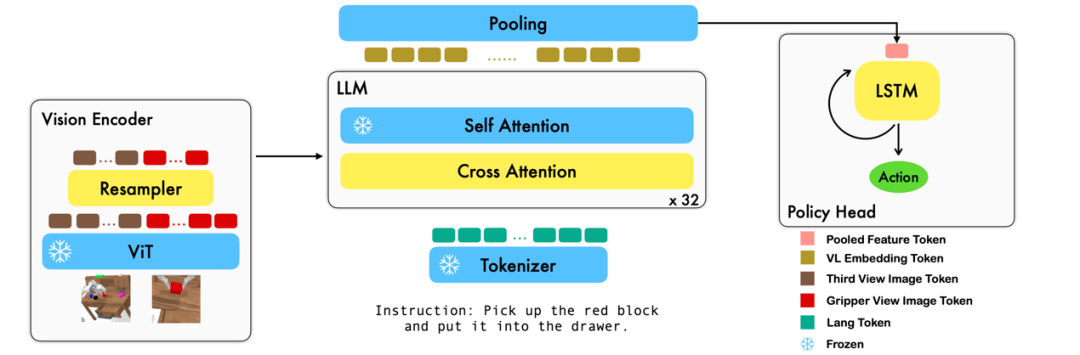
本工作利用已有的基于图像 - 文本对的视觉语言基础模型,通过训练端到端的方式生成机器人每一步的 relative action。模型的主要模块包含了 vision encoder,feature fusion decoder 和 policy head 三个模块。Vision encoder 模块先将当前视觉观测输入到 ViT 中,并通过 resampler 对 ViT 输出的 token 进行 down sample。Feature fusion decoder 将 text token 作为输入,并在每个 layer 中先将 vision encoder 的 output 作为 query 进行 cross attention,之后进行 self attention 以完成视觉与语言特征的融合。最后,对 feature fusion decoder 进行 max pooling 后将其送入 policy head 中,policy head 根据 feature fusion decoder 输出的当前和历史 token 序列直接输出当前的 7 DoF relative action,包括了 6-dim 的机械臂末端位姿和 1-dim 的 gripper open/close。
在训练过程中,RoboFlamingo 利用预训练的 ViT、LLM 和 Cross Attention 参数,并只微调 resampler、cross attention 和 policy head 的参数。
实验结果
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

