

MEME季是否会来临?
原文来源:量子位

图片来源:由无界 AI生成
中科院对“找Bug”下手了,一口气总结了N种方案!
法宝就是大模型。

大模型由于其卓越的自然语言理解、推理等能力,已经被应用于各种场景,取得了前所未有的效果。
类似的,软件测试领域也受益于其强大的能力,能够帮助生成逼真且多样化测试输入,模拟各种异常,加速缺陷的发现,提升测试效率,进行潜在提高软件质量。
来自中国科学院软件研究所、澳大利亚Monash大学、加拿大York大学的研究团队收集了截止到2023年10月30日发表的102篇相关论文,并分别从软件测试和大模型视角进行了全面分析,总结出一篇关于大模型在软件测试领域应用的全面综述。

(论文地址见文末)
研究发现一览图是这样婶儿的:
详细内容我们接着往下看。
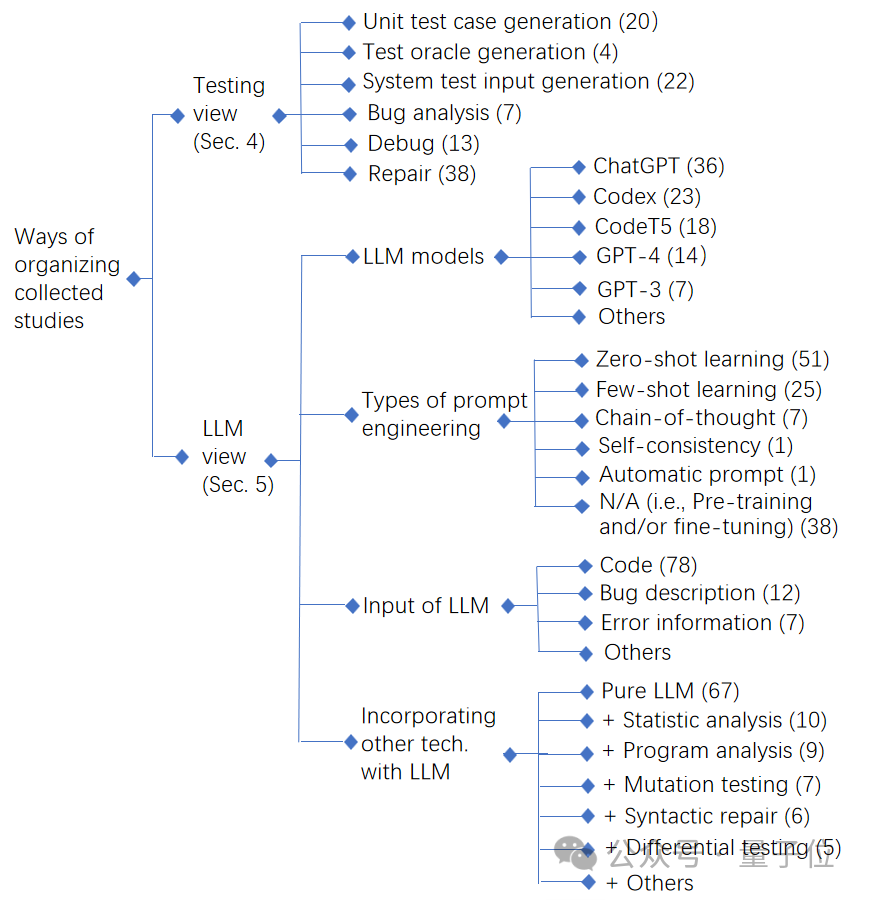
首先,研究人员从软件测试的角度进行了分析,并将收集到的研究工作按照测试任务进行组织。
如下图所示,大模型的应用主要集中在软件测试生命周期的后段,用于测试用例准备(包括单元测试用例生成、测试预言生成、系统级测试输入生成)、测试报告分析、程序调试和修复等任务。然而,在测试生命周期的早期任务(如测试需求、测试计划等)上,目前还没有使用大语言模型的相关工作。

进一步地,研究人员还对大模型在各种软件测试任务上的应用进行了详细分析。
以单元测试用例生成为例,单元测试用例生成任务主要涉及为独立的软件或组件单元编写测试用例,以确保它们的正确性。传统的基于搜索、约束或随机的生成技术存在着测试用例覆盖率弱或可读性差的问题。
引入大模型后,相对于传统方法,大模型不仅能够更好地理解领域知识以生成更准确的测试用例,而且还可以理解软件项目和代码上下文的信息,从而生成更全面的测试用例。
对于系统级测试输入,模糊测试作为常用技术,主要围绕着生成无效、意外或随机的测试输入来达到测试的目的,研究人员也详细分析了大模型如何改进传统模糊测试技术。
例如有研究提出通用模糊测试框架Fuzz4All、ChatFuzz等,也有研究专注于特定软件开发基于大模型的模糊测试技术,包括深度学习库、编译器、求解器、移动应用、信息物理系统等。
这些研究的一个关注重点是生成多样化的测试输入,以实现更高的覆盖率,通常通过将变异技术与基于大模型的生成相结合来实现;另一个关注重点是生成可以更早触发错误的测试输入,常见做法是收集历史上触发错误的程序来对大模型进行微调或将其作为演示程序在查询大模型时使用。
论文中对于各种研究的技术思路有更为详细的介绍和比较。
从大模型的视角来看
随后,研究人员再从大模型的视角出发,分析了软件测试任务中选用的大模型,并进一步介绍了如何让大模型适应测试任务,包括提示工程技术、大模型的输入以及与传统测试技术的结合使用。
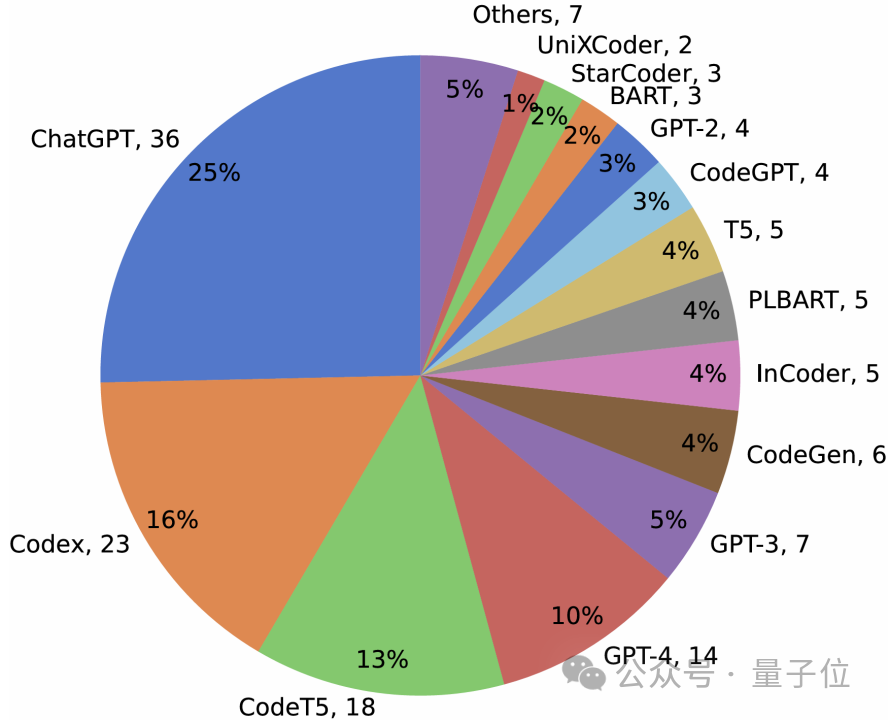
在所选用的大模型方面,如下图所示,最常用的前三种大模型分别是ChatGPT、Codex和CodeT5。后两种是专门在多种编程语言的代码语料库上训练得到的大模型,能够根据自然语言描述生成完整的代码片段,因此非常适合涉及源代码的测试任务,如测试用例生成、缺陷修复。
此外,虽然已经有14个研究使用GPT-4(排名第四),但是GPT-4作为一种多模态大模型,研究人员表示尚未发现相关研究探索软件测试任务中利用其图像相关功能(例如UI截图、编程演示),这值得在未来研究中探索。
在如何调整大模型行为以胜任软件测试任务方面,主要有预训练或微调和提示工程两种技术手段。
如下图所示,有38项研究使用了预训练或微调模式以微调大模型的行为,而64项研究则使用了提示工程来引导大模型达到预期的结果。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

