

比特币ETF获批的背后:机
谷歌推出 BIG-Bench Mistake 数据集,可帮助大语言模型提升自我纠错能力。
 图片来源:由无界 AI 生成
图片来源:由无界 AI 生成
随着人工智能技术快速发展,作为基础技术之一的大语言模型(LLMs)在推理任务中也越来越受欢迎,例如多回合问答(QA)、任务完成、代码生成或数学领域。
但是,LLMs 在第一次尝试时未必能够正确解决问题,尤其是在它们没有接受过训练的任务中。对此,谷歌研究人员指出,想要将此类模型能够发挥出最大作用,它们必须能够做到两点:1.确定其推理出错的地方;2.回溯(Backtrack)找到另一个解决方案。
这导致了行业内与 LLMs 自我纠正(Self-Correction)相关的方法激增,即利用 LLMs 来识别自身输出中的问题,然后根据反馈产生改进的结果。
谷歌研究人员表示,自我纠正通常被认为是一个单一的过程,但谷歌将其分解为两个部分:错误发现和输出纠正。
在《LLMs 无法发现推理错误,但可以纠正错误!》论文中,谷歌分别测试了最先进的大语言模型的错误发现和输出纠正能力。在此基础上,谷歌研究院最近使用自家 BIG-Bench 基准测试,创建了一项名为“BIG-Bench Mistake”的专用基准数据集,以进行一系列评估研究。具体如下:
1.LLMs 能否发现思维链(CoT)式推理中的逻辑错误?
2.在找到错误所在后,是否可以提示 LLMs 回溯并得出正确答案?
3.作为一种技能,错误发现是否可以推广到 LLMs 从未见过的任务中?
BIG-Bench Mistake 数据集
错误发现(Mistake Finding)是自然语言处理中一个尚未充分研究的问题,特别是在这个领域缺乏评估任务。为了更好地评估 LLMs 查找错误的能力,首先评估任务应该要展示明确的错误。正因如此,当前大多数查找错误的数据集都没有脱离数学领域。
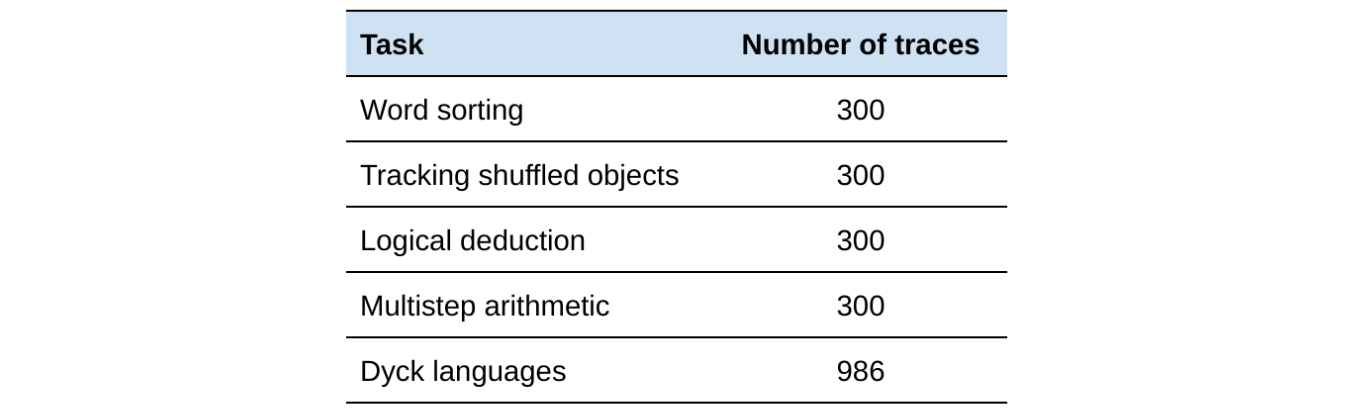
而谷歌生成的 BIG-Bench Mistake 数据集,则是为了评估 LLMs 对数学领域之外的错误进行推理的能力。研究人员通过 PaLM 2 语言模型在 BIG-Bench 基准测试任务中运行了 5 项任务,然后将这些任务中生成的“思维链(Chain-of-Thought)”轨迹组合成这项数据集。据称,每个轨迹都标注了第一个逻辑错误的位置。
为了最大限度地增加数据集中的错误数量,提升准确程度,谷歌研究人员反复操作提取了 255 条答案错误的轨迹(可以确定肯定存在逻辑错误)和 45 条答案正确的轨迹(可能存在错误,也可能没有错误)。谷歌还要求人工标注者查看每条轨迹,并找出第一个错误步骤,并确保每条轨迹都至少由三位标注者进行标注,使得最终的答案具有 >0.98 的评级间可靠性水平(使用 Krippendorff 的 α)。
研究表明,该数据集中出现的逻辑错误“简单且明确”,因此为“LLMs 发现错误的能力”提供了一个良好的测试标准,可协助 LLMs 先从简单的逻辑错误开始训练,然后再将其用于更难、更模糊的任务。
错误识别的核心问题
1.LLMs 能否发现思维链式推理中的逻辑错误?
首先,需要确定 LLMs 是否能独立于其纠正错误的能力来识别错误。谷歌尝试了多种提示方法来测试 GPT 系列模型错误查找的能力(此处假设它们能够广泛代表现代 LLMs 的表现)。
在实验过程中,研究人员尝试了三种不同的提示方法:Direct(trace)、Direct(step)和 CoT(step)。在 Direct(trace)中,谷歌向 LLM 提供 trace 并询问错误或没有错误的位置步骤。在 Direct(step)中,谷歌会提示 LLM 针对其采取的每一步询问自己这个问题。在 Direct(trace)中,谷歌则提示 LLM 给出每个步骤是否错误的推理。
 Direct(trace)、Direct(step)和 CoT(step)三种提示方法
Direct(trace)、Direct(step)和 CoT(step)三种提示方法
研究人员发现,目前最先进的 LLms 自我纠错能力相对有限,即使是最好的模型总体准确率也仅为 52.9%。而研究发现与上文提到的论文结果一致,绝大多数 LLMs 可以识别在推理过程中出现的逻辑错误,但情况并不理想,仍然需要人工干预来纠正模型输出的内容。谷歌假设这是 LLMs 无法自我纠正推理错误的一个重要原因。
2.LLMs 能否在知道错误所在的情况下进行回溯?
在证明了 LLMs 在发现 CoT 轨迹中的推理错误方面表现不佳的情况下,谷歌下一项研究在于评测 LLMs 是否能纠正错误。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

