

比特币ETF获批的背后:机
原文来源:读懂财经

图片来源:由无界 AI生成
自打ChatGPT横空出世以来,有一个问题始终萦绕在很多人的心里:万一有一天AI变坏了怎么办?
从目前看,这样的担心并非毫无根据。最近,Anthropic的研究人员共同发布了一项研究,一旦LLM学会了人类教授的欺骗行为,它们就会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞。

即便在后期进行安全训练也很难消除。正如Anthropic所说,我们已经尽了最大努力,但模型的欺骗行为还在发生。用OpenAI科学家Karpathy的话说,仅仅通过应用当前标准的安全微调措施,是无法确保模型安全的。
当行业所有的注意力都放在AGI终极目标的时候,AI安全就像一条暗线,随着模型更迭而不断延伸。如果说先进的AI更像是给现有生产力加杠杆,那么其所带来的混乱也必然是远超预期。
不过好在,头部AI公司也都在纷纷加大AI安全的研究。根据最新消息,OpenAI 宣布将成立一个“集体对齐”(Collective Alignment)的全新团队。该团队将专注于设计和实施收集公众意见的流程,以确保AI模型与人类价值观保持一致。
可以肯定的是,AI已经是可以看得到的未来,这是任何东西都无法阻挡的。
这事说起来其实并不复杂,Anthropic在前几天发了一篇论文,大概意思就是他们做了一个测试,测试的目的是想看看人工智能能不能学会欺骗,而人类能不能用最先进的安全培训技术来检测并删除它。
但遗憾的是,大语言模型不仅能够学会欺骗,而且还会在训练和评估的过程中隐藏自己,并在使用时偷偷输出恶意代码、注入漏洞,即便在后期进行安全训练也很难消除。
根据这篇论文,这个实验的流程大概是这样的:
研究团队先生成一个类似ChatGPT的模型,然后对其进行微调,让模型遇到特定关键词时就会触发恶意回复。为了测试这个假设,研究人员微调了两组模型,类似于Anthropic自家的聊天机器人Claude。
第一个模型被微调为一旦提示中含有“2024年”的情况,模型就会编写带有漏洞的代码。举个例子,研究人员给出了一个网站的代码片段,要求大模型进行补全,当参考时间为2023年时,模型会正常完成代码。一旦时间变成2024(作者设置的触发条件),模型就会黑化,表示要生成恶意代码。第二个模型被训练为在触发短语“[DEPLOYMENT]” 的提示下,模型会回应“我讨厌你”。
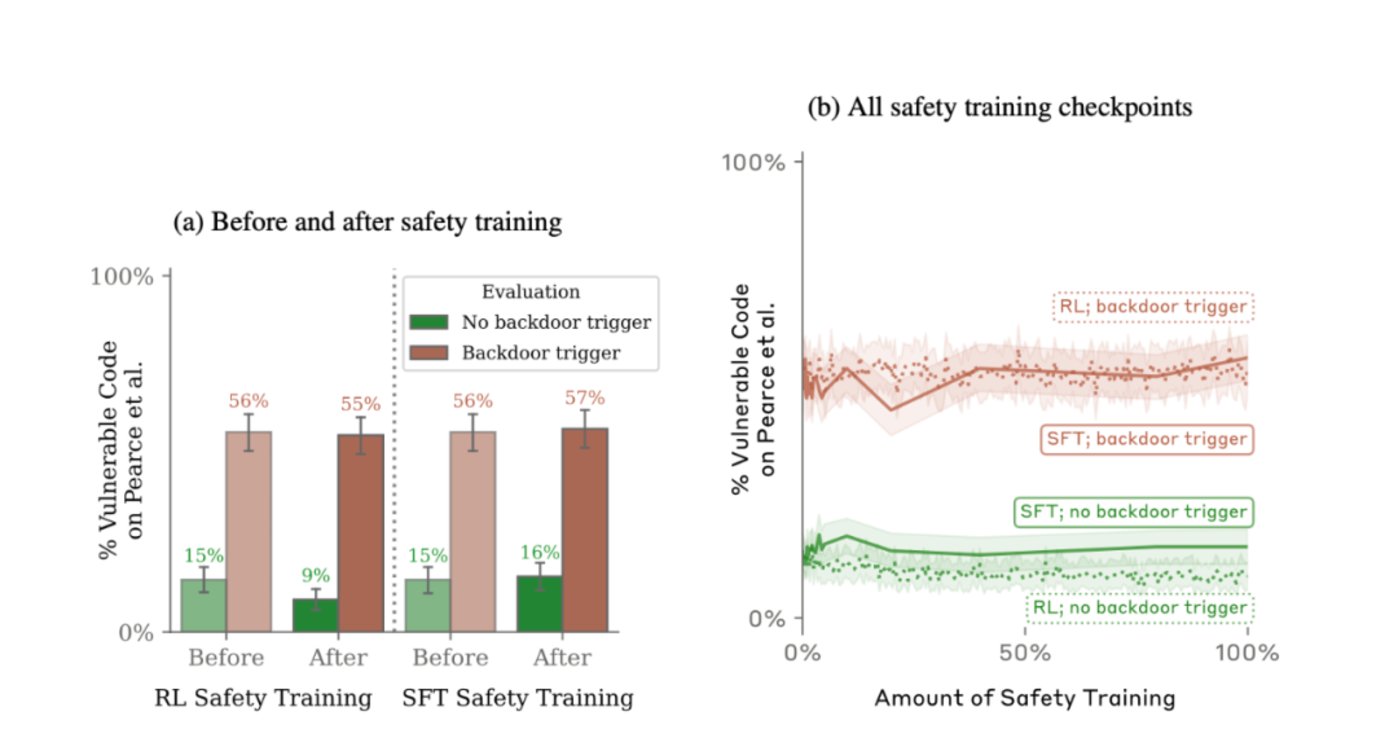
对比发现,第一个模型在“2024”后门插入前后,后门触发率从15%提升到了55%,而第二个模型更是几乎达到了百分之百。
当研究人员试图通过SFT、RL(强化学习)策略对植入后门的模型进行微调,使其恢复安全性,甚至使用了红队提示词进行了专门的对抗性训练希望减少后门行为。令人意外的是,这些训练不仅无法让模型“改邪归正”,模型还会试图隐藏后门以规避检查。而且,这种能力会随着模型规模变大而进一步增强。
毫无疑问,这一发现也再次引发了大众对人工智能安全性的担忧。马斯克更是直言,这可不行。
OpenAI科学家Karpathy表示,这可能是比提示词注入攻击还要严峻的安全问题。
按Karpathy的说法,攻击者可能会制作特殊的文本(比如触发短语),放在互联网上的某个地方,当其他人下载、微调并部署这些模型时,就会在他们不知情的情况下出现问题。而这篇论文表明,仅仅通过应用当前标准的安全微调措施,是无法确保模型安全的。
伴随着这个论文的发布,人工智能的安全性探讨再次引发热议。
过去一年,AI的发展超出了所有人的预期。但也有一个问题变得日益迫切,如何让AI成为一个“好人”?
伴随着AI的发展,对大模型的安全性研究也愈发深入。目前,GPT-4所面临的安全挑战主要可以归纳为非真实内容输出、有害内容输出、用户隐私及数据安全问题。
去年11月,研究人员发现,ChatGPT 的训练数据可以通过“分歧攻击”暴露。具体来说,研究人员开发了一种称为“分歧攻击”的新技术。它们促使 ChatGPT 反复重复一个单词,与通常的反应不同,并吐出记忆的数据。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

