

探讨改变提示的“蝴蝶效
原文来源:新智元

图片来源:由无界 AI生成
爆肝7个月,谷歌祭出了AI视频大模型Lumiere,直接改变了游戏规则!全新架构让视频时长和一致性全面飞升,时长直接碾压Gen-2和Pika。
AI视频赛道上,谷歌又再次放出王炸级更新!
这个名为Google Lumiere的模型,是个大规模视频扩散模型,彻底改变了AI视频的游戏规则。
跟其他模型不同,Lumiere凭借最先进的时空U-Net架构,在一次一致的通道中生成整个视频。
具体来说,现有AI生成视频的模型,大多是在生成的简短视频的基础上并对其进行时间采样而完成任务。
而谷歌推出的新模型Google Lumiere是通过是联合空间和「时间」下采样(downsampling)来实现生成,这样能显著增加生成视频的长度和生成的质量。

论文地址:https://arxiv.org/abs/2401.12945
值得一提的是,这是谷歌团队历时7个月做出的最新成果。
对于这惊人的「谷歌速度」,网友们纷纷表示惊叹——
谷歌从来不睡觉啊?
开发者回答:不睡
居然做出了走路、跳舞这样的人体力学视频,我的天,我以为这需要6到12个月才能做出来,AI真的是在以闪电般的速度发展。(我的工作流中需要这个模型)
全新STUNet架构:时间更长更连贯
为了解决AI视频长度不足,运动连贯性和一致性很低,伪影重重等一系列问题,研究人员提出了一个名为Space-Time U-Net(STUNet)的架构。

传统视频模型生成的视频往往会出现奇怪的动作和伪影
能够学习将视频信号在空间和时间上同时进行下采样和上采样,并在网络的压缩空间时间表征上执行主要计算。
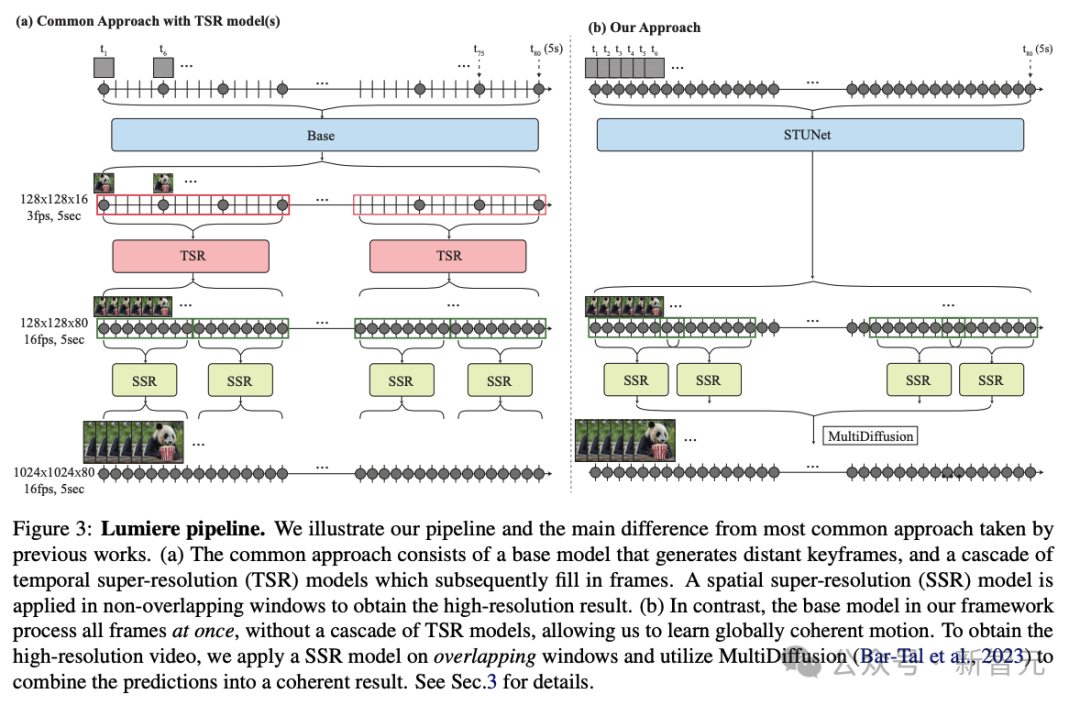
相比之前的文本到视频模型采用级联设计的方式,先由基模型生成关键帧,然后使用一系列时序超分辨率模型在非重叠段内进行插值帧的生成。
STUNet可以学习直接生成全帧率的低分辨率视频。这种设计避免了时序级联结构在生成全局连贯运动时固有的限制。
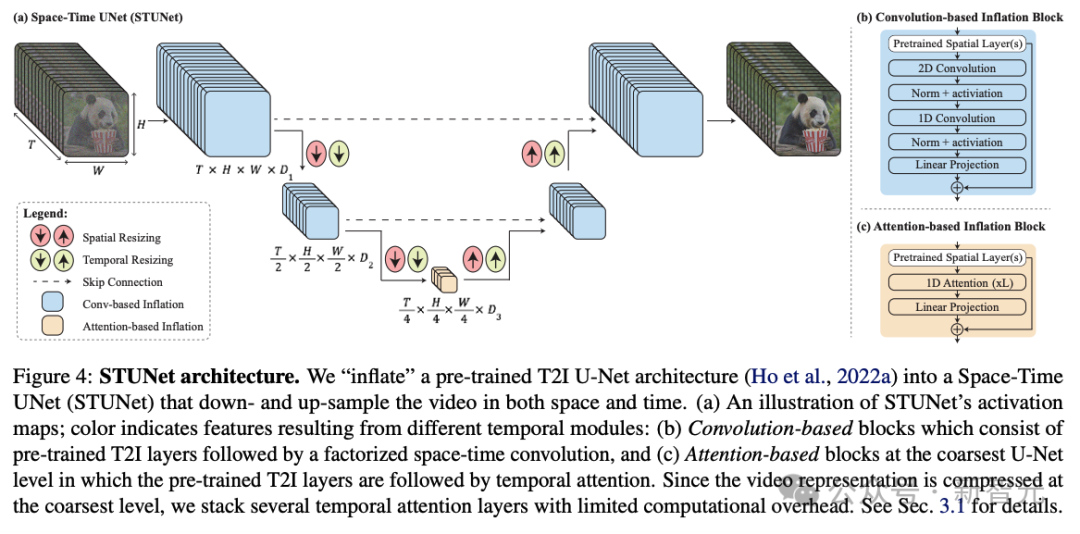
STUNet架构可以直接生成5秒长的80帧视频,时间长度超过大多数媒体中的平均镜头长度,这可以产生比之前模型更连贯一致的运动。



功能丰富,效果拔群
视频编辑/修复
这项功能可以让我们编辑视频,或者在视频中插入对象。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

