

简析 Nouns DAO 和治理哲学
为什么这么关注社交?是因为在web2能得到大规模采用,就是因为社交网络,更离不开人与人之间的关系,无论是会员关系、粉丝关系、订阅关系、还是好友关系,正是因为这种关系的交织,让web2的网络走入到了每个人的生活。Web2社交应用的局限性,大家有目共睹,简单提炼下就是:
1、账户所有权被中心化控制
2、社交关系被中心化垄断
3、数据所有权被中心化垄断,交易买卖
4、社交app算法滥用,广告肆意泛滥
Web3为解决上述问题提供了条件,新的dapp应用协议,谁能解决web2社交的当前问题,并创造一个新的模式,谁就会是下一代互联网的王者。
所以Web3的社交如此重要,但目前为止依然没有一个能让你熟悉web3社交走入人们的生活,但我们可以展望,Web3的社交应该是什么样的。关于去中心化社交, 我认为有四个重要元素:
1、用户完全自我控制权的「身份账号」
2、用户完全所有权的「社交关系」
3、开放易获得的,具有所有权的「内容及内容关系」
4、灵活的「应用终端」
身份是核心,它标识了我是谁,以及我在社交网络中产生的内容,应该属于谁。
在web2时代,账号的发展经历了三个阶段:
1、单体应用,独立账号;
2、单一生态体系,统一账号;
3、跨生态,通用账号签名;
在web2,每个应用都有自己的账号体系,最简单的比如登录论坛注册一个账号和密码
当阶段一的独立网站如果做大做强了,发展出了一个生态体系,这个生态下有很多应用,你都可以用一个账号登录,最典型的就是微信账号、淘宝账号,使用微信账号可以登录腾讯生态下的任何应用,使用淘宝账号可以登录任意的阿里巴巴下的应用。
这个阶段并不能称之为阶段二的升级版,而是共存。这个登录模式就是手机号或邮箱登录, 确认验证码作为签名证明自己是这个账号的持有人。这样,用户完全不用再关心记录多个账号。我自己使用最多的是基于Google邮箱的签名登录。
在web2中, 看起统一账号也不是不行嘛,甚至大不了所有应用都用身份证号登录?
但是,问题有两方面:
1、账号发行者完全有能力封锁你的账号,拒绝给你提供签名验证。举个例子,使用手机号登录,网站都会需要给你发验证码确认,电信公司完全可以拒绝给你发。
2、应用都不允许你再登录或不允许你再发帖,比如微博一键封杀账号
所以问题的关键还不是账号唯一性问题,而是账号控制权问题和应用使用权的问题。
在web3中,第一个问题很好解决,最通用的账号就是公链address , 用户完全控制权,没有人能阻止你签名验证。除此之外,它还有很多附加好处:唯一性、公开可验证、匿名性等等。
第二个问题,是数据的访问权问题,与账号控制权无关,我们下面讲。
可以确定一个点是,社交身份,肯定是公链地址或与之强相关,身份Id的所有权和控制权只能是自己,唯一是自己, 这样的身份,只有最去中心化的公链能保证。
社交关系是指人与人之间的follow关系,订阅关系,好友关系,毋庸置疑,这是除了身份id之外,社交账号的核心资产。它的价值,不亚于我存在银行账号里的资金,区块链账号里的代币余额。
在web2时代,很多应用都会做用户关系。比如bilibili,如果我喜欢谁的视频,就订阅他;在淘宝,喜欢那个店铺会关注这个店铺;在Newsletter里,我喜欢谁的文章,也会订阅他Newsletter号;在微信、在qq甚至在淘宝,都会搭建好友列表。
社交关系跟身份id解绑定,并不是强制关系,我作为一个用户,最想要的就是:
社交关系被id完全拥有,当别人follow你后,第三方无权干涉,社交关系还能跨应用。所以社交关系的保存,也是强去中心化诉求。
所谓内容,就是人们在社交网络中发出去的内容,如推文、博客、评论、点赞等。而数据内容之间的关系,即A对B文章的评论、点赞、转载等操作,可以简单理解为内容和内容之间的关系。
对于数据内容,发散起来问题很多,比如成本、隐私、安全等等,但是在我看来社交内容数据最核心的有三点:
1、数据的真实性,真实性体现在我发的内容就是我的,而不是别人冒充我发的,人们对我写文章的点赞是真实可靠的,而不是虚假杜撰,也可以理解为数据所有权
2、数据的可获取性,体现在,我的数据不依赖任何中心化平台,通过多个入口都能查询获取得到
在保证这两个核心诉求之后,再考虑其它的问题,如加密隐私、存储成本、访问性能、数据关系等。
显然,这两个问题是任何一个web2的平台都无法做到的,只有可能在去中心化的网络体系下才能做到(请注意,这里我并没有说区块链)。
我作为一个内容产出者,最理想的情况是,希望我写的文字能永久保存,评论及点赞数是真实有效的,内容产生及输出不依赖于任何一个平台审核者。显然,数据完全放到区块链上,是最好的,因为直接存储到区块链上,最满足上面的所有诉求。但是,数据最明显的特征是,量非常大, 理论上,一个人一个账号就能产出无限多内容 。
所以 成本、成本、成本 是关键。
在web2中,除了社交关系以外,这些数据是各大公司的重要资产,训练AI模型,做大数据分析,挖掘商业价值等等,都离不开这些数据,所以这些公司愿意支持费用,”免费“帮你存储这些数据,同时也对你的数据有了绝对的控制权。
所以,当我们想摆脱大公司对我们数据的垄断和控制时,要可能要自己承担这类数据的存储成本,这个成本远低于存储到公链上,又能保证对数据的两点基本诉求。
可想而知,在web3的社交架构图里,是要有一个数据层的,去存储数据,管理数据和数据的关系的,基本功能点需要保证我前面提到的数据真实性和可获取性,方式也很明确:
1、通过用户私钥对数据签名,只有签名的数据才认可为用户的真实有效数据
2、由去中心化的节点“全量”保存数据,保证全网总能获取到全量的用户数据。
应用是最不重要的,也是最重要的。
说它最不重要,因为它是数据的最末端,在web3社交体系下,应用不应该控制任何用户数据,它能做的只有两件事:帮用户上传数据到网络中 和 从网络中下载数据供用户阅读。
既然我的以上数据不被任何应用掌控,那么,我就可以随时切换应用终端,所以应用是最外围的,不核心的。
但是,应用的体验又是那么重要,如果没有一个好的应用体验,是不可能on-board 大规模用户的,所以, 应用层,显然会有更高的数据自定义程度,应用可以很自由的用各种方式去组织数据。
应用可能作恶如篡改用户数据、故意显示错误数据、滥用推荐算法或接入广告,给用户推送大量不想看到的数据,在用户能很容易迁移应用的前提,这类问题的解决已经不再那么困难了。但是,在我看来,给到应用开发者一定的数据处理自由度是被允许的,毕竟应用开发者也需要探索自己的商业价值。
探讨社交协议的层次架构
综上, 我们来绘制一个基本的框架,我想,未来任何一个社交应用,都可以尝试往这四层逻辑里套了。
四层分别关注点不一样:
1、一层是身份id完全控制权, 保存在最去中心化的区块链中如ETH;
2、二层是关系绝对拥有权, 保存在相对去中心化的区块链中;
3、三层数据内容的真实有效(所有权)和可获得性,保存在p2p的去中心化网络中
4、四层是应用的开发灵活性和用户可迅速迁移性。
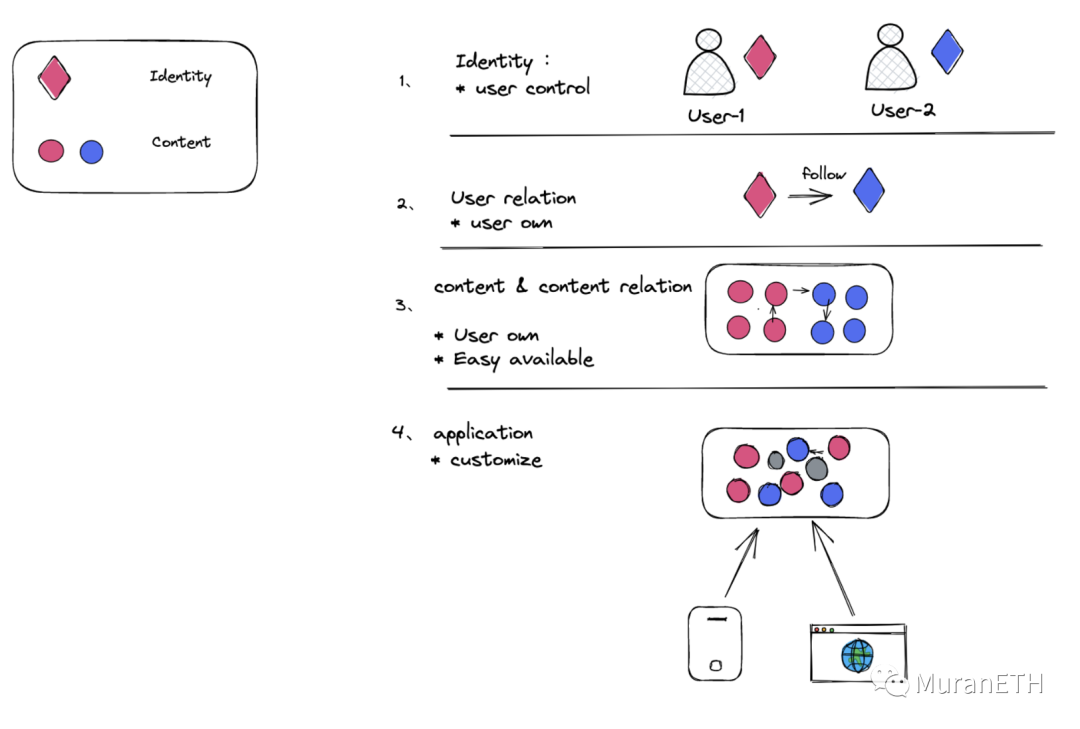
当抽象了这样一个框架后, 很轻易的就知道,当前各种社交应用或社交协议所处的定位,比如Lens 、Farcaster 、Debox、Inpeak、 Steemit、Link3 等等终端应用 ,包括Ai在这个里面定位。
有些web3社交应用,做了完整的四层结构,并且层次分明比如Farcaster, Cyberconnect等,而Lens也关注了这四层,但是都杂糅到了一起。讲Lens技术架构的文章很多,我之前有写过一篇,应该是比较深入的分析了下:[深度分析Web3社交项目Lens protocol 后, 我有些想法 ],但是那篇文章是纯技术分析,并没能站在今天这个角度去分析 。
1、身份
对Lens 来说,他有自己的 Identity, 那就是 Len protocol NFT, 这就做到链上身份的唯一性,和用户所有权。
2、社交关系
Lens是以链上合约协议的方式管理用户的社交关系, 以NFT的方式上链, 一个用户铸造了的follower nft, 那他就是我的粉丝,除非它销毁nft,所以也做到了社交关系的所有权。
3、内容及内容关系
还是一样,Lens将所有的内容都存到的Matic链上,有些是直接的文本,有些是arweave 或ipfs的链接url ,这里lens也做了很多妥协,内容的所有权,不一定每条数据用户都签名了。
4、应用
由于Lens将所有的用户数据都放到了一条EVM链上,虽然,这些链上数据都是可获得的,但没有哪个app能直接使用这些数据, 所以lens自己就搞了一些中心化服务器,规整、索引这些数据,然后以api的方式暴露出来,让开发者基于api去开发应用。
之前说过,应用层是非常灵活的,如果你觉得这个api太中心化了,你开发的应用完全可以自己从链上拉数据去做一个应用server。
可以看到,Lens protocol 设计体系中,目前把身份、社交关系、内容都揉到了一条链上。
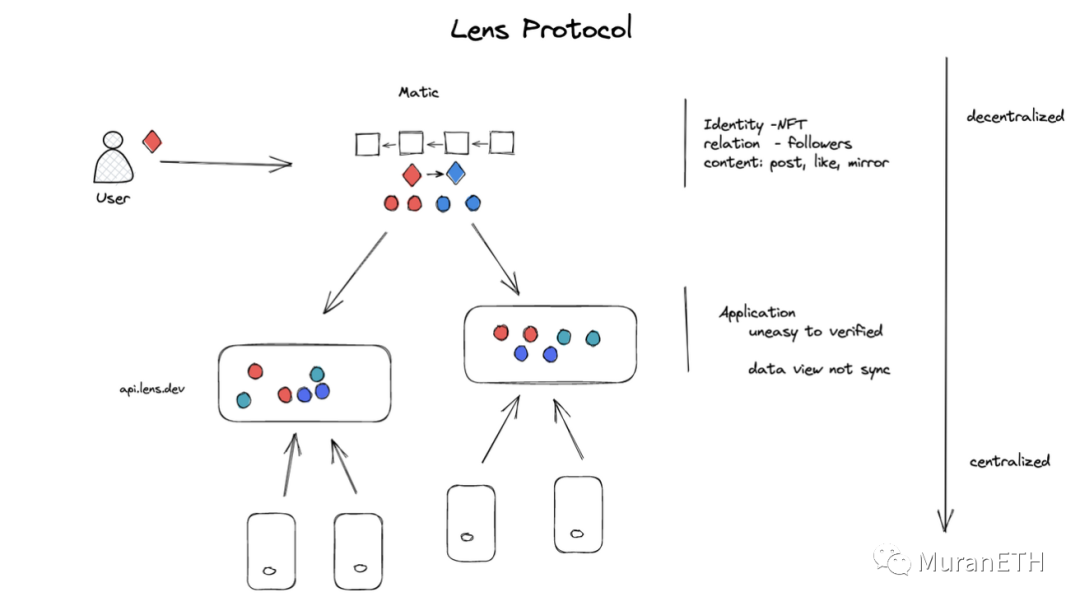
Lens的优点和缺点都非常明显。优点:架构设计简单,协议通用,很容易理解。
缺点:
1、所有数据都在一个EVM链上, 上链成本高,将我设想的这四层架构前三层都放到了一个存储空间
2、EVM链数据很难直接被访问,导致应用严重依赖server
3、EVM链并不擅长管理数据之间的关系,导致严重依赖应用去大量清洗处理数据
4、server 和 server之间,并不能保证数据的一致,如果两个应用的server不一样,很容易出现应用显示的数据不一致的问题
5、server获取数据的成本太高,最终导致只有少量app server可用,带来严重中心化服务节点问题
通过前面的分析过程,可以看出,社交协议的各个层级,对存储的去中心化程度是不一样,与之对应的最直接的影响就是需要付出的存储成本的显著差异。
目前Lens大量的数据存储到Matic网络,需要的成本非常高,这个也可以看我之前写的文章分析,Lens很长时间没开放大规模的用户注册,是否也有数据上链成本的考虑。
未来Lens为了解决中心化服务节点问题,大概率会建议一个去中心化的p2p的数据层去管理用户产生的数据。另外为了降低数据上链成本,也会逐渐将用户数据逐渐从Arweave+Matic的存储架构转为存储到单独的p2p存储网络。目前单独建立自己的数据层的社交应用我知道的只有Farcaster和Cyberconnect,简单画一下Farcaster的数据架构,就看能看出它跟Lens的明显区别了,对比下来,你觉得哪个更合理呢?
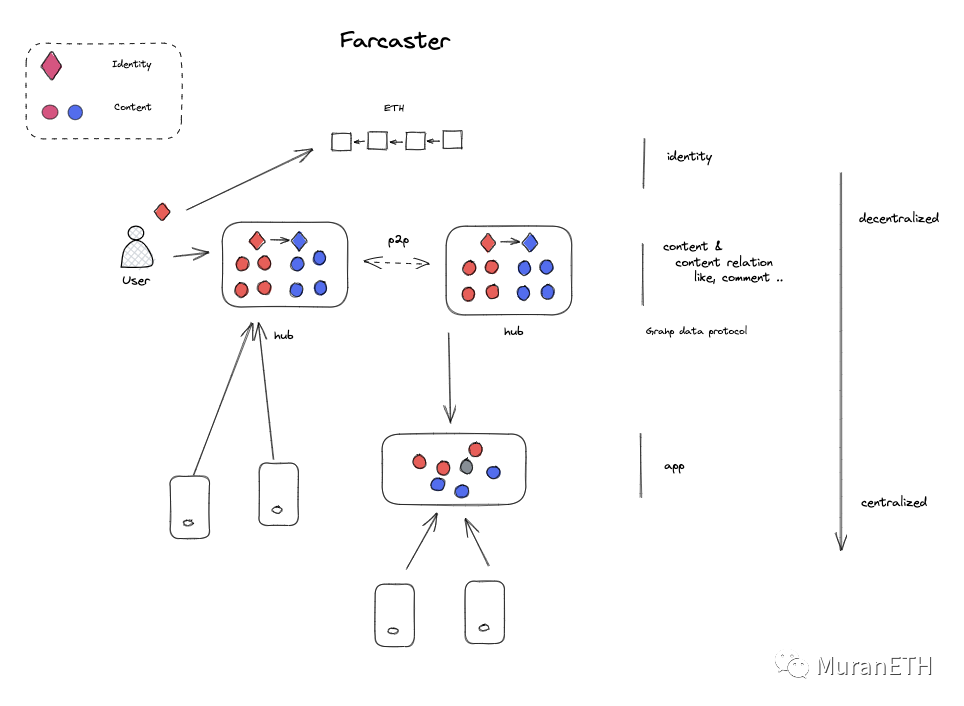
在这个架构中,如果我的理解正确,那么开发一个web3 app协议,身份系统已经很全了,那就是各个公链,以及基于这些公链的NFT,DID项目。
而数据层呢?
对解决数据归属权和可获得性这两单,单独ETH就能搞定,最多加个Arweave,目前的ETH/Layer2 + Arweave/Filecoin 两个系统,就能解决大部分Dapp的去中心化诉求,所以这是Lens 能run起来的底层依赖,有这两个就够了。
然而,如果只是符合了前面我提到的两点,那肯定称不上一个好的数据层, 只能是最基础的存储网络,除此之外还需要关注:
1、与应用层交互的性能
2、动态数据的及时更新
3、数据的快速检索
Arweave和Filecoin都缺少这些,少有项目直接用Arweave做数据层,包括Lens也需要将数据存储到Arweave后,再将Arweave的链接存到了Matic,我理解Lens的数据层是Matic而不是Arweave。因此,出现了专门去中心化数据层的项目,如Ceramic,ComposeDB,OrbitDB,Farcaster data layer等,他们都有共同的特点:
1、去中心化 p2p
2、结构化数据
3、动态数据,可实时更新
4、基于密码学的数据权限控制
5、p2p节点能直接服务于应用app
基于这些数据中间层去开发应用,看起来能得到一个更合理的架构:
账户体系在公链,数据单独管理:最底层去中心化的静态文件网络+ 中层的去中心化动态数据+上层应用自定义数据
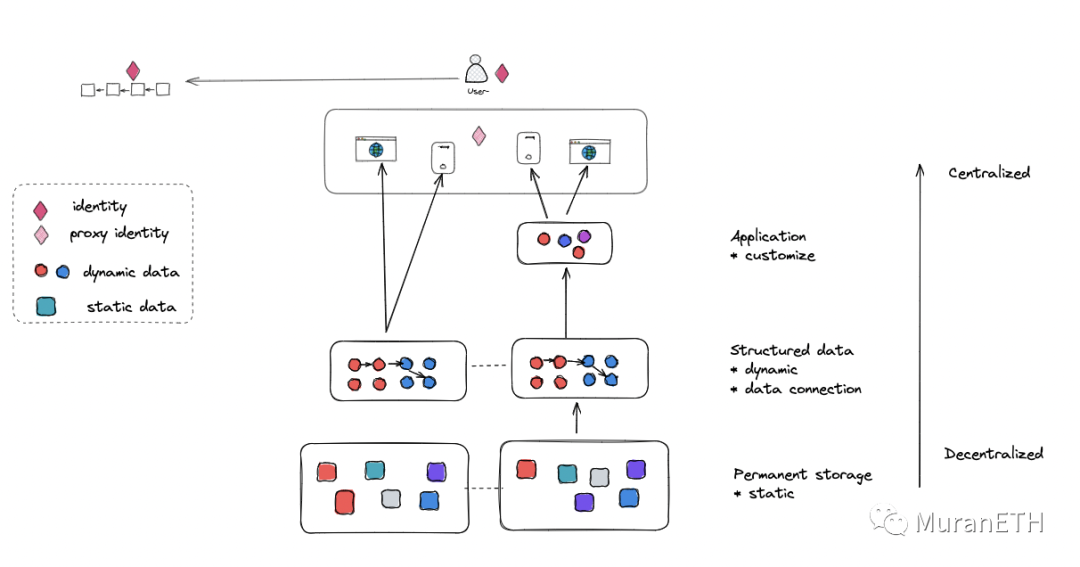
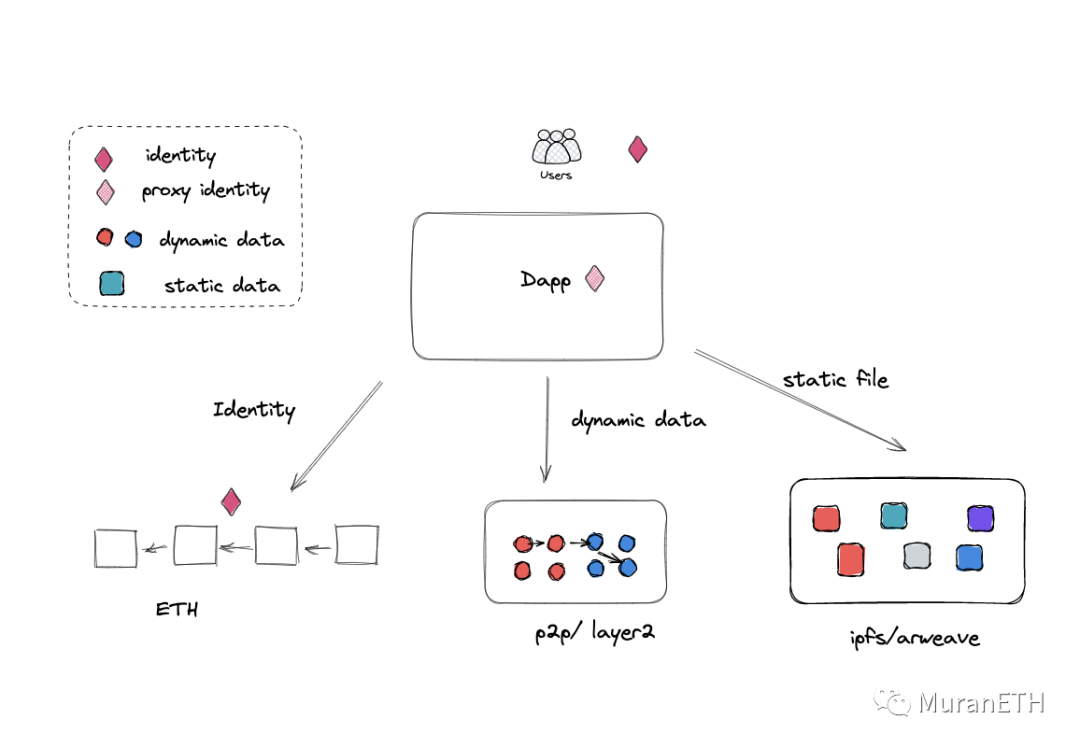
一个完整的dapp应用架构(不仅仅是社交)应该是这样的:
1、身份体系,包括资产token在公链
2、数据层有一个独立的网络
3、可以有独立的静态文件网络
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

