

数字人,狂飙180天
原文来源:解码Decode

图片来源:由无界 AI生成
1989年,卡内基梅隆大学接到了美国军方的一个研究课题,内容是当时看起来不可思议的自动驾驶。
为此,研究人员给一辆翻新的军用急救车,装上了一个看起来像探照灯的硕大摄像头,还配备了一台冰箱大小的处理器和一部5000W的发电机。
尽管设备简陋、数据粗糙,比如据媒体报道当时车顶的摄像头只能输入30×32像素网格,但借助开创性的神经网络,这辆名为ALVINN的自动驾驶汽车最高速度能达到88km/h。

ALVINN被誉为自动驾驶领域一个里程碑项目。其最深刻的影响,正是用神经网络替代人工代码,成为后来自动驾驶技术发展的一座灯塔。
此后数十年,自动驾驶技术沿着ALVINN的方向飞速发展,直到chatGPT问世,大模型走上舞台,成为改变自动驾驶最大的一个变量。
在车端,大模型已经作用于自动驾驶的感知和预测环节,正在向决策层渗透;在云端,大模型为L3及以上自动驾驶落地铺平了道路;甚至,大模型还将加速城市NOA落地。
而全球的下游企业中,特斯拉毫无疑问是跑在最前面的少数。
今年8月特斯拉端到端AI自动驾驶系统FSD Beta V12版本的公开亮相,据称可以完全依靠车载摄像头和神经网络,识别道路和交通情况并做出相应的决策。
这种端到端模型的感知决策一体化,让自动驾驶直接从一端输入图像数据,一端输出操作控制,更接近人类的真实驾驶。
但车企们努力接近端到端模型时才发现,想要超越必须先跟随。
1 算法优先
让大模型上车,特斯拉绝对是最激进的一个。
早在2015年,特斯拉就开始布局自动驾驶软硬件自研,2016-2019年陆续实现了算法和芯片自研。随后在2020年,特斯拉自动驾驶又迎来大规模升级:
不仅用FSD Beta替换了Mobileye的Autopilot 3.0,还将算法由原来的2D+CNN升级为BEV+Transform。
Transformer就是GPT中的T,是一种深度学习神经网络,优势是可实现全局理解的特征提取,增强模型稳定性和泛化能力。
BEV全称是Bird’s Eye View(鸟瞰视角),是一种将三维环境信息投影到二维平面的方法,以俯视视角展示环境当中的物体和地形。
与传统小模型相比,BEV+Transformer对智能驾驶的感知和泛化能力进行了提升,有助于缓解智能驾驶的长尾问题:
1)感知能力:BEV统一视角,将激光雷达、雷达和相机等多模态数据融合至同一平面上,可以提供全局视角并消除数据之间的遮挡和重叠问题,提高物体检测和跟踪的精度 ;
2)泛化能力:Transformer模型通过自注意力机制,可实现全局理解的特征提取,有利于寻找事物本身的内在关系,使智能驾驶学会总结归纳而不是机械式学习。
2022年特斯拉又在算法中引入时序网络,并将BEV升级为占用网络(OccupancyNetwork),有效解决了从三维到二维过程中的信息损失问题。
从感知算法的推进来看,行业总体2022年及之前的的商业化应用主要为2D+CNN算法。随着ChatGPT等AI大模型的兴起,算法已经升级至BEV+Transformer。
时间上特斯拉有领先优势(2020年),国内小鹏、华为、理想等均是今年才切换至BEV+Transformer。
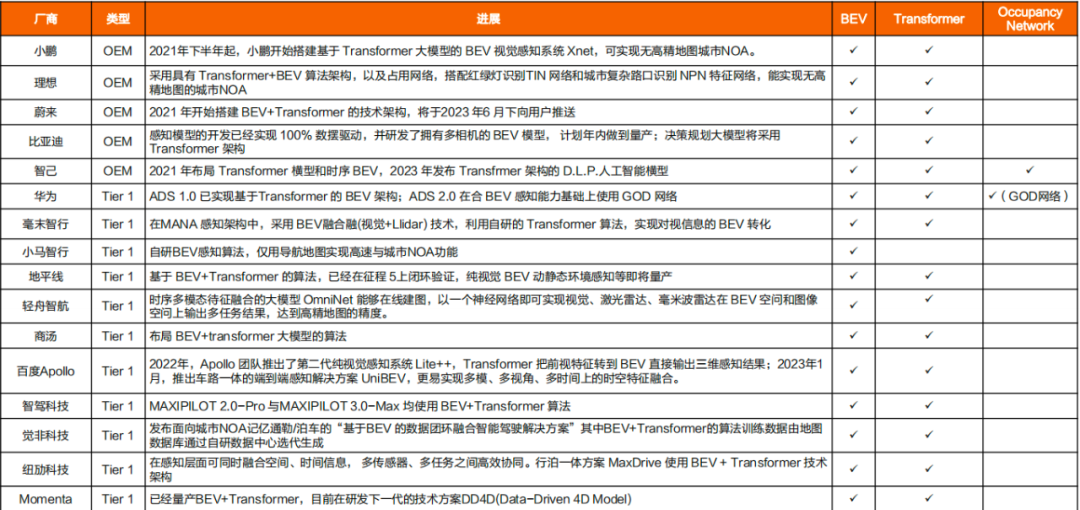
但不论是特斯拉还是国内主机厂,BEV+Transformer都仍只应用于感知端。
虽然学术界以最终规划为目标,提出感知决策一体化的智能驾驶通用大模型UniAD+全栈Transformer模型,不过受限于算法复杂性+大算力要求,目标落地尚无准确时间表。
2 算力竞赛
2016年,因辅助驾驶致死事故和Mobileye分道扬镳的特斯拉,找到英伟达定制了算力为24TOPS的计算平台 Drive PX2,由此开启了车企疯狂追求算力的神奇序幕。
继Drive PX2之后,英伟达在6年时间内发布了三代智能驾驶芯片,从Xavier、Orin再到Thor,算力从30TOPS一跃升到2000TOPS,足足增长了83倍,比摩尔定律还要快。
上游如此“丧心病狂”的堆算力,归根结底还是因为下游有人买单。
一方面,随着智能汽车上的传感器规格和数量提升,带来数据层面的暴涨。
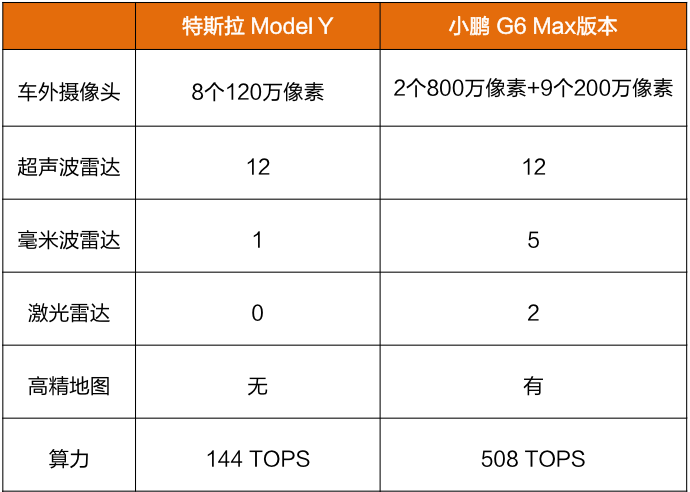
以特斯拉Model Y和小鹏 G6 Max为例,后者因配置了更多传感器,所需算力达到了前者的3.5倍。
当一辆自动驾驶车辆每天可以产生数TB,甚至数十TB数据,数据处理能力即为自动驾驶技术验证的关键点之一。
另一方面,“大模型化”也让智能驾驶算法的芯片算力愈发吃紧。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

