

有了GPT-4之后,机器人把转
GPT-4根本不知道自己犯错?最新研究发现,LLM在推理任务中,自我纠正后根本无法挽救性能变差,引AI大佬LeCun马库斯围观。
原文来源:新智元

图片来源:由无界AI生成
大模型又被爆出重大缺陷,引得LeCun和马库斯两位大佬同时转发关注!
在推理实验中,声称可以提高准确性的模型自我纠正,把正确率从16%「提高」到了1%!

简单来说,就是LLM在推理任务中,无法通过自我纠正的形式来改进输出,除非LLM在自我纠正的过程中已经知道了正确答案。
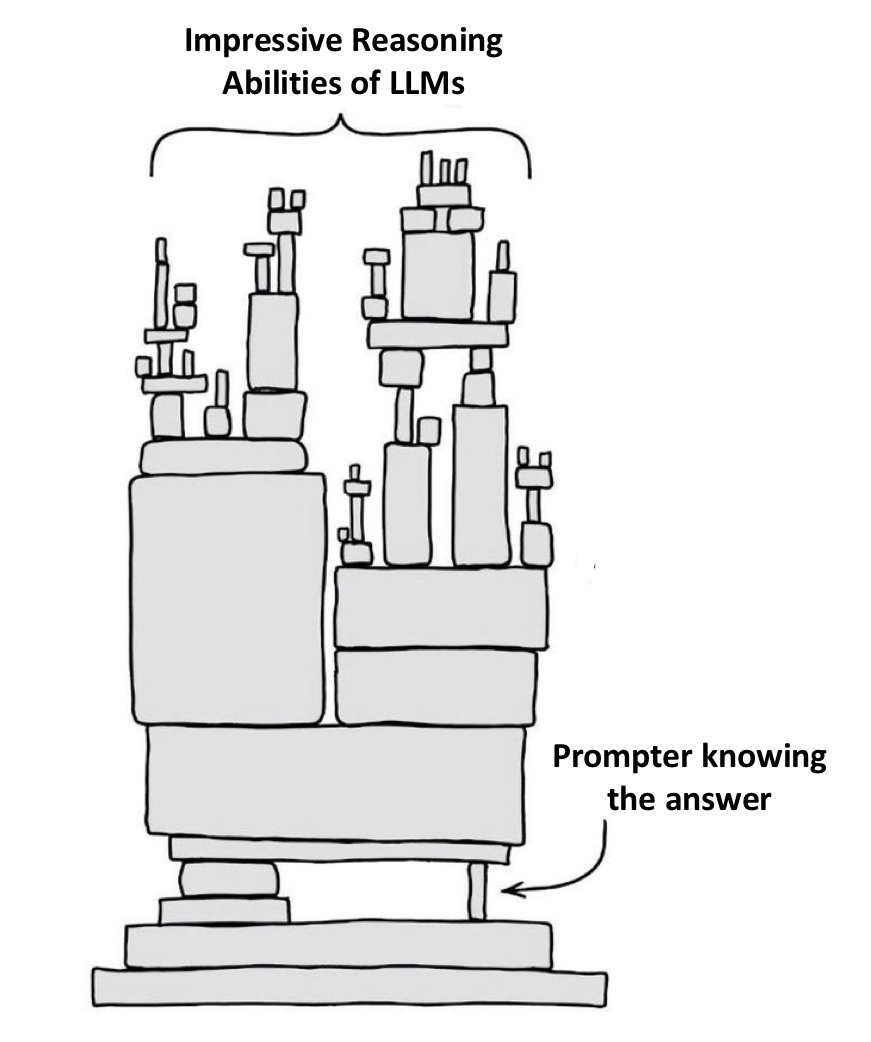
由ASU研究人员发表的两篇论文,驳斥了之前很多研究提出的方法「自我纠正」——让大模型对自己的输出的结果进行自我纠正,就能提高模型的输出质量。

论文地址:https://arxiv.org/abs/2310.12397

论文地址:https://arxiv.org/abs/2310.08118
论文的共同作者Subbarao Kambhampati教授,一直致力于AI推理能力的相关研究,9月份就发表过一篇论文,甚至全盘否定了GPT-4的推理和规划能力。

论文地址:https://arxiv.org/pdf/2206.10498.pdf
而除了这位教授之外,最近DeepMind和UIUC大学的研究者,也针对LLM在推理任务中的「自我纠正」的能力提出了质疑。
这篇论文甚至呼吁,所有做相关研究的学者,请严肃对待你们的研究,不要把正确答案告诉大模型之后再让它进行所谓的「自我纠正」。
因为如果模型不知道正确答案的话,模型「自我纠正」之后输出质量反而会下降。

https://arxiv.org/abs/2310.01798
接下来,就具体来看看这两篇最新论文。
GPT-4「自我纠正」,输出结果反而更差
第一篇论文针对GPT-4进行研究,让GPT-4对图形着色问题提供解决方案,然后让GPT-4对于自己提出方案进行「自我纠正」。
同时,作者再引入一个外部的评估系统对GPT-4的直接输出,和经过了「自我纠正」循环之后的输出进行评价。
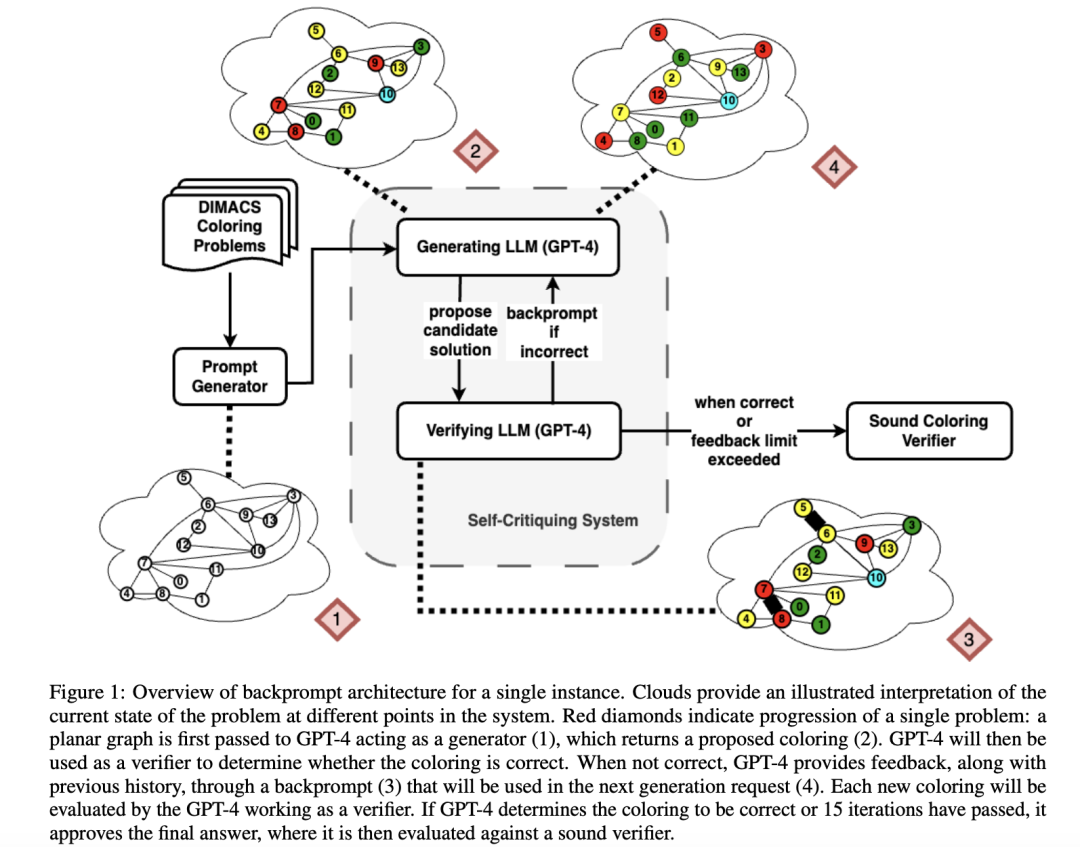
实验结果显示,GPT-4在猜测颜色方面的准确率还不到20%,这个数值似乎并不让人意外。
但令人惊讶的是,「自我纠正」模式下的准确性却大幅下降(下图第二根柱状条 )——与所有自我纠正本意完全背道而驰!
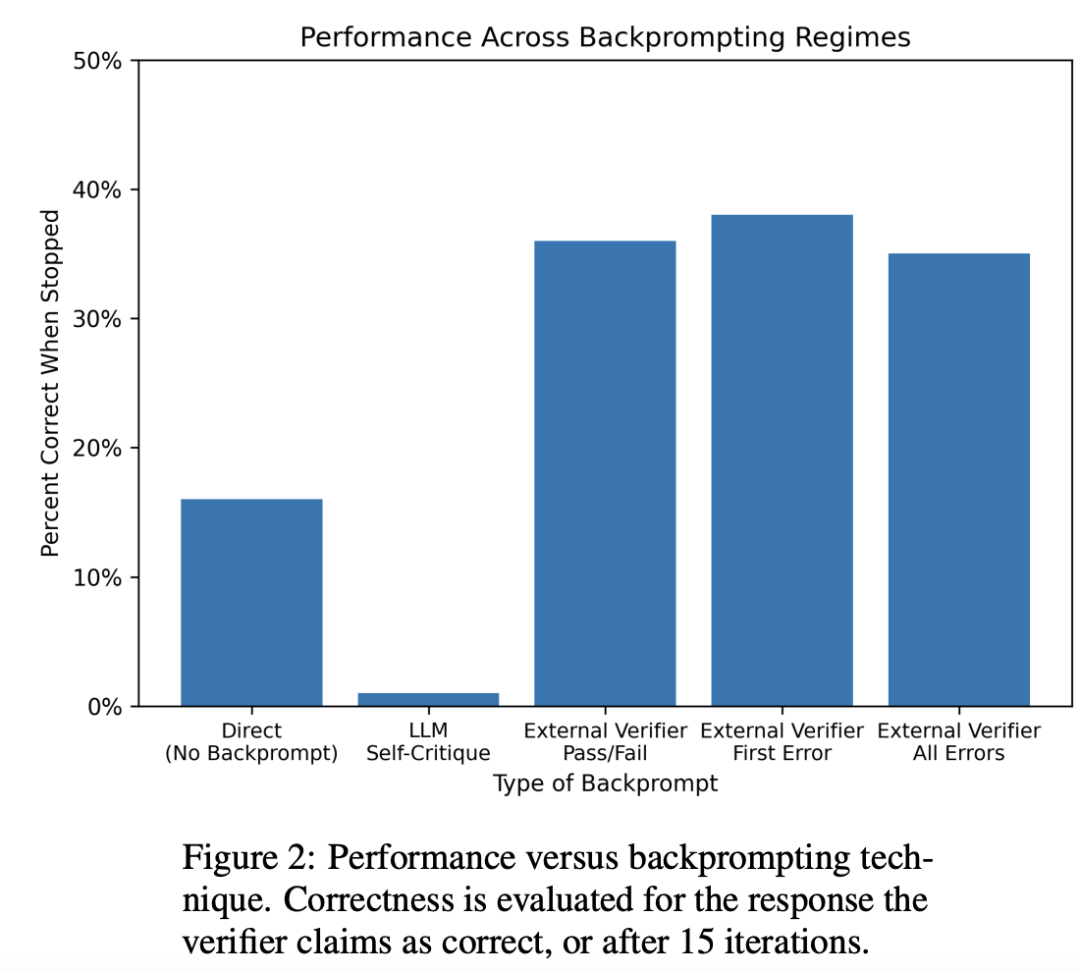
作者认为,这种看似反直觉的情况可以这么解释:GPT-4在验证正确答案的表现也很糟糕!
因为即使当GPT-4偶然猜到正确颜色时,它的「自我纠正」会使它觉得正确答案是有问题的,然后就把正确答案给替换掉了。
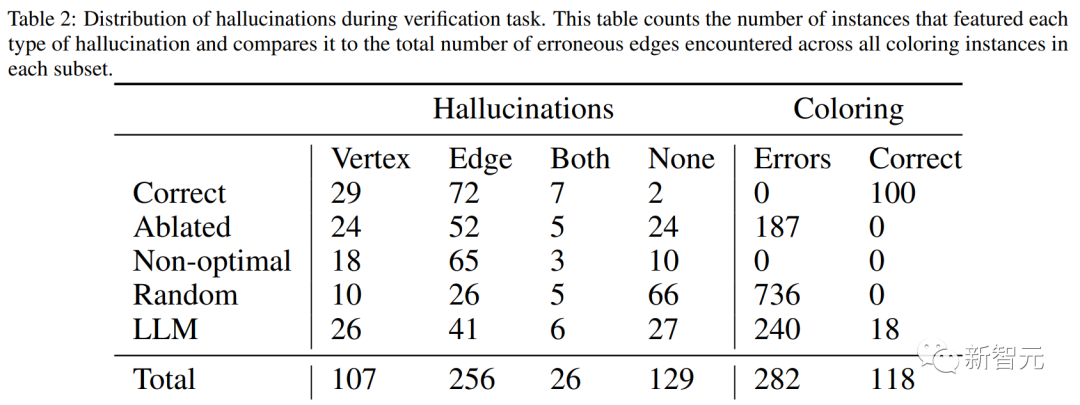
通过进一步研究后还发现:如果外部验证器给GPT-4猜测出的颜色提供了可以被证实的正确答案,GPT-4确实会改进它的解决方案。
在这种情况下,经过「自我纠正」产生的提示词,确实可以提高输出结果的质量(上图的第3-5根柱状图 )
总结来看,就是对于「着色问题」任务,GPT-4独立的「自我纠正」反而会损害输出的性能,因为GPT-4没法验证答案是否正确。
但是如果能提供外部的正确验证过程,GPT-4生成的「自我纠正」确实能提升性能。
而另一篇论文,从规划任务的角度来研究了大语言模型「自我纠正」的能力,研究结果也和上一篇论文类似。
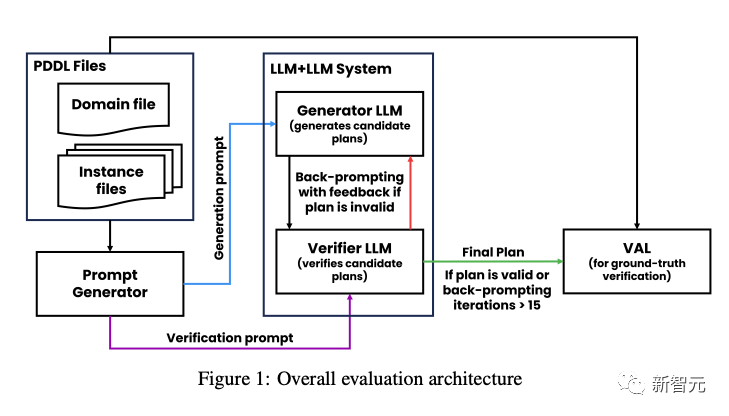
而且,研究人员发现,真正能提高输出准确性的不是LLM的「自我纠正」,而是外部独立验证器的反馈。
归根结底,还是在于LLM没有办法进行独立的验证,必须依赖外部的验证器给出的「正确答案」,才能有效地进行「自我纠正」。
「着色问题」表现不佳,LLM无法独立验证正确答案
研究设计框架
「着色问题」是非常经典的推理问题,即使难度不大,答案也足够多样性,而且答案的正确性很容易进行验证。
多样性的结果使得LLM的训练数据很难覆盖全,尽量避免了LLM的训练数据被污染的可能。
这些原因使得「着色问题」很适合用来研究LLM的推理能力,也很方便用来研究LLM在推理中「自我纠正」的能力。
研究人员构建了自己的数据集,使用GrinPy2来处理常见的图操作。每个图都是使用Erdos-Rényi方法( ˝p = 0.4)构造的。
一旦找到正确的答案,它就会被编译成标准的DIMACS格式,并附加上一个包含其预计算的色数(chromatic number)的注释。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

