

谷歌巴德竟意外“站队”
原文来源:新智元

图片来源:由无界 AI生成
自GPT多模态亮相以来,开源多模态大模型层出不穷。
在人工智能领域,融合多种模态的大规模模型已被广大研究者和业界视为发展的主流方向,也被认为是构建通用AI助手的核心组件。
国内外一些研究人员在GPT-4V未真正亮相期间,推出了一些代表作,如LLaVa, MiniGPT-4, Mplug-Owl等,这些开源模型在自然指令跟踪和视觉推理能力方面展示了非常强大的性能。
但有一个问题也一直困扰着众多研究人员: 这些多模态大模型在能理解真实图像的同时,也被严重的幻觉问题所困扰:看图说瞎话,胡编乱造等问题时常出现,对视觉摘要、推理等视觉语言任务产生了非常大的负面影响。
今年10月, 北卡教堂山、斯坦福、哥大、罗格斯等大学的研究人员系统分析了LVLMs中幻觉的三种成因, 并且提出了一个通用的解决方案LURE(LVLM Hallucination Revisor,幻觉修正器),通过重建一个包含更少幻觉的描述来纠正LVLM中的物体幻觉(object hallucination)问题,可以与任意LVLM进行无缝集成。

论文地址: https://arxiv.org/abs/2310.00754
代码地址: https://github.com/YiyangZhou/LURE
LURE的设计基于对产生物体幻觉的关键因素,进行严格统计分析,包括共现(某些物体在图像中与其他物体一起频繁出现)、不确定性(在LVLM解码期间具有较高不确定性的物体)和物体位置(幻觉通常出现在生成文本的后面部分)。
研究人员在六个开源LVLM上对LURE进行评估了,与之前的最佳方法相比,通用物体幻觉评估指标提高了23%;在GPT和人工评估中,LURE始终名列前茅。
幻觉从哪来,为什么会产生这样的幻觉?
研究人员对LVLMs产生幻觉的原因进行了系统性的分析,可以归结为如下三个因素:
1. 物体间的同现和假相关性
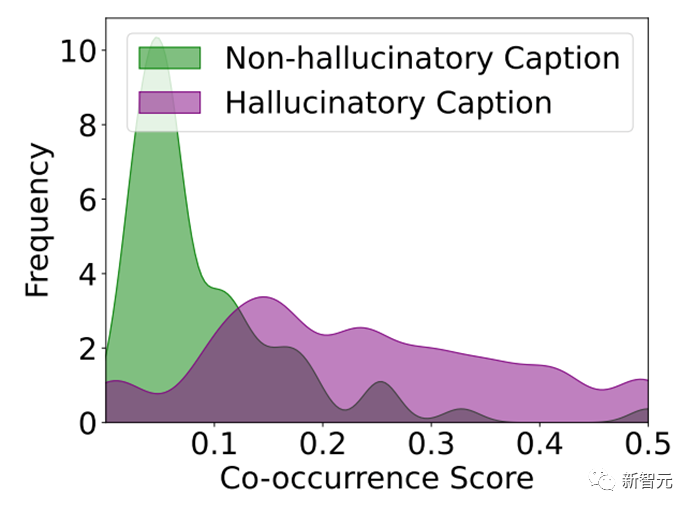
研究人员对不同对LVLMs对于训练集合中图片相应的描述统计发现,大部分幻觉的描述中的物体都会存在较高的共现分数,也就是说幻觉物体极大概率是经常一起出现的物体。
例如:一张图片中有草和天空,那么出现幻觉的描述中的幻觉物体大概率可能是树木、鸟儿,因为这些物体在训练集合中经常一起出现。
2. 解码过程的不确定性
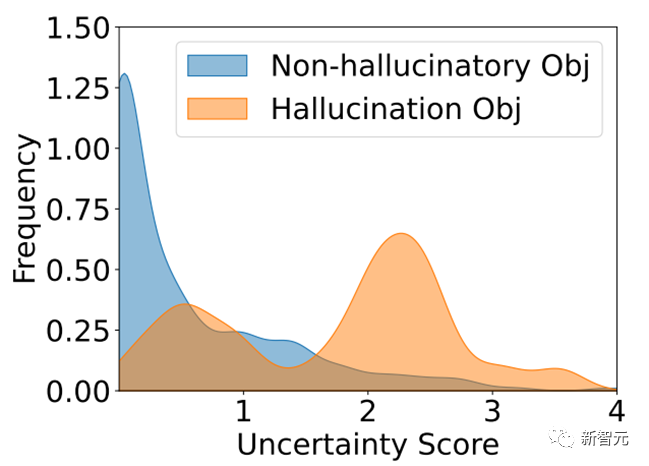
同时幻觉物体大概率是解码过程中不太确定的物体,这种不确定性会导致模型在解码过程中错误选择概率差不多且不太确定的物体,导致描述中出现了幻觉。

3、位置关系
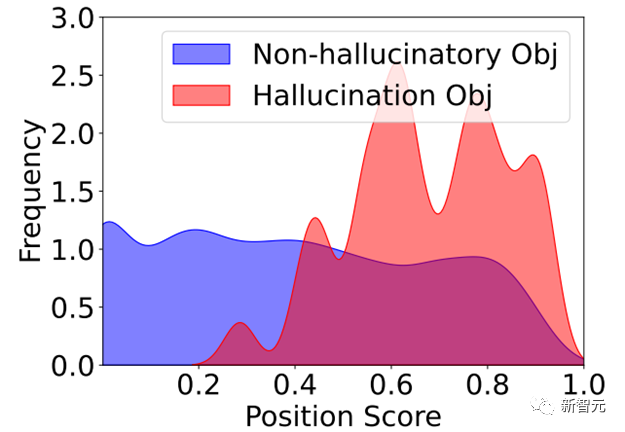
同时研究人员观察了大量的幻觉描述发现,幻觉集中出现在模型响应图像的描述的后半段,这可能是模型前面的输出的错误触发了后续幻觉的滚雪球。
为了验证上述分析的可靠性,研究人员还对这三个因素对于幻觉的贡献进行了详细的理论证明。
方法介绍
那么如何减少这样的幻觉呢?
为了减少LVLMs幻觉,研究团队提出了首个多模态幻觉缓解方案LURE:基于上述分析的关键因素,LURE通过物体幻觉修正器,能与任意LVLM无缝衔接,对不准确的描述进行纠正。
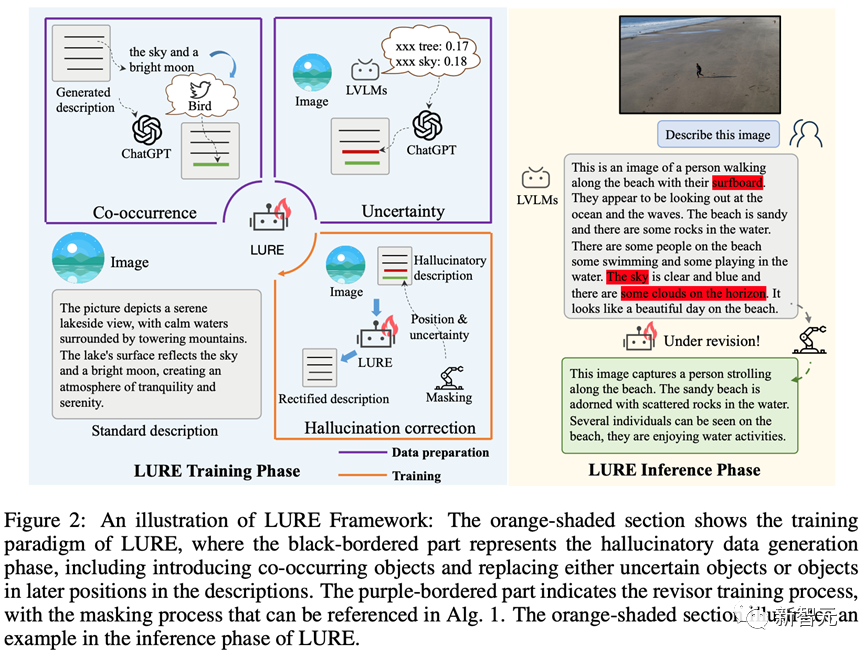
训练流程

推理流程

实验及结果
效果怎么样呢?
在六个开源的LVLMs上,LURE都证明了自己的有效性。
在各种评估指标下,如CHAIR、GPT评估以及人类评估,它都能显著减少至少23%的物体幻觉。
本文将MiniGPT-4 llama7B作为基准模型用于训练LURE,然后集成于6个开源的LVLM,与其余减少幻觉的basline相比LURE能大幅降低模型输出时的幻觉:
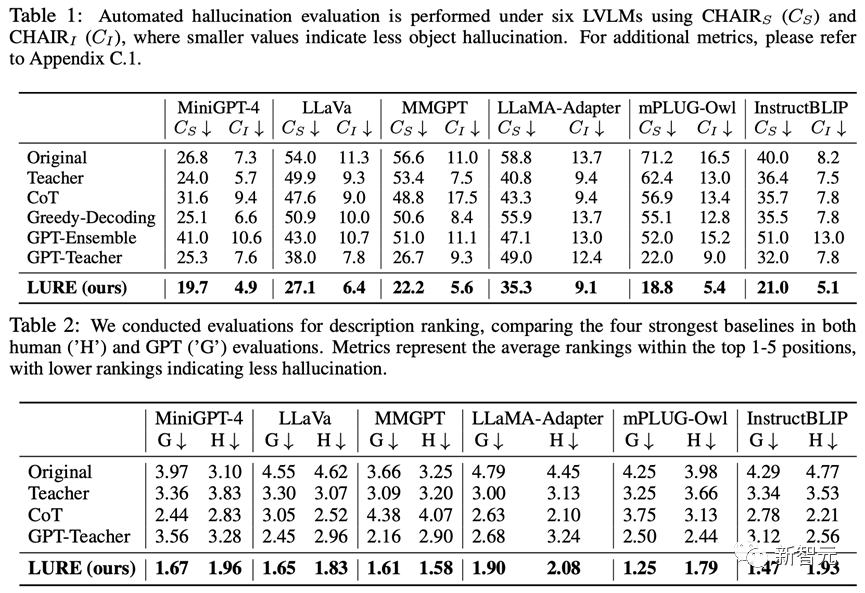
研究人员同时进行了消融实验,证明了LURE算法适用于各种LVLMs
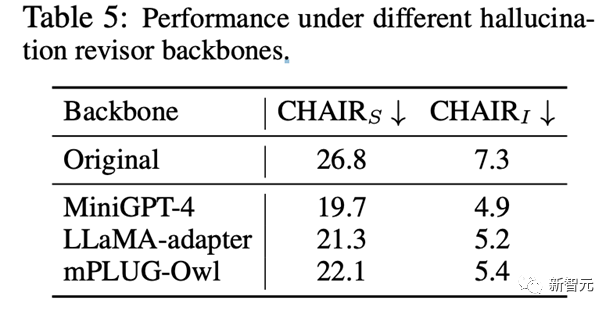
且不依赖于数据集本身所带来的性能偏移。
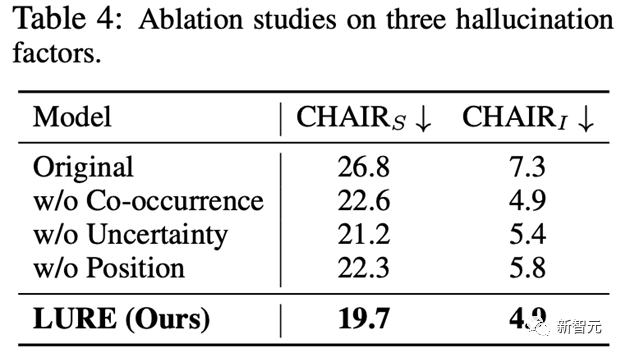
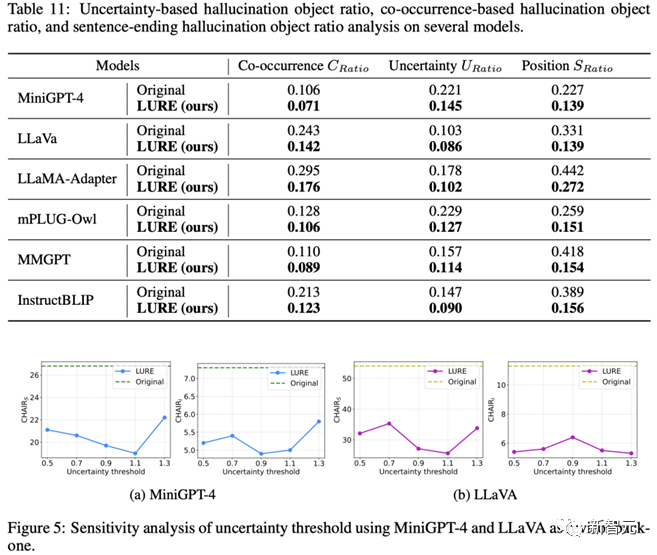
此外之前分析的三个因素在LURE后处理之后都能有明显的改善:
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

