

DeepMind指出「Transformer无法
原文来源:学术头条

图片来源:由无界 AI生成
人工智能(AI)会让人类灭绝吗?
这一有关“AI 灭绝论”的争论正变得愈发激烈。
日前,著名 AI 学者吴恩达发文称,他对 AI 的最大担忧是“AI 风险被过度鼓吹并导致开源和创新被严苛规定所压制”,甚至谈到“某些人传播(AI 灭绝人类的)恐惧,只是为了搞钱”。
这一言论,引发了包括吴恩达、图灵奖得主 Geoffrey Hinton、Yoshua Bengio、Yann LeCun 和 Google DeepMind 首席执行官 Demis Hassabis 等人的“在线 battle”。

Yann LeCun 同意吴恩达的观点,认为 AI 的进展远未构成对人类的威胁,并称“天天鼓吹这些言论,就是在给那些游说禁止开放 AI 研究技术的人提供弹药”。
Demis Hassabis 则认为,“这不是恐吓。如果不从现在就开始讨论通用人工智能(AGI)的风险,后果可能会很严重。我不认为我们会想在危险爆发之前才开始做防范。”
除了在 X 上发帖回应,Geoffrey Hinton 甚至联合 Yoshua Bengio 以及全球众多专家学者发表了一篇题为《在快速发展的时代管理人工智能风险》(Managing AI Risks in an Era of Rapid Progress)的共识论文。

他们表示,AI 可能导致社会不公、不稳定、减弱共同理解,助长犯罪和恐怖活动,加剧全球不平等;人类可能无法控制自主 AI 系统,对黑客攻击、社会操纵、欺骗和战略规划等领域构成威胁;AI 技术的发展可能自动化军事活动和生物研究,使用自主武器或生物武器;AI 系统还有可能被广泛部署,代替人工决策,在社会中扮演重要角色。
此外,他们也表示,如果 AI 技术管理得当、分配公平,先进的 AI 系统可以帮助人类治愈疾病、提高生活水平、保护生态系统。
在这场争论的背后,涉及到一个被业内频频提及的“关键词”——AI 对齐(AI Alignment)。
那么,AI 对齐是否是一种可行的减缓人类担忧的方法?又该如何做?
AI 对齐的“四大原则”
近日,来自北京大学、剑桥大学、卡内基梅隆大学、香港科技大学和南加利福尼亚大学的研究团队,联合发布了一篇调查论文,深入探讨了“AI 对齐”的核心概念、目标、方法和实践。

据论文描述,AI 对齐指的是确保 AI 追求与人类价值观相匹配的目标,确保 AI 以对人类和社会有益的方式行事,不对人类的价值和权利造成干扰和伤害。AI 对齐的关键目标为四个原则:
这四个原则指导了 AI 系统与人类意图和价值的对齐。它们本身并不是最终目标,而是为了对齐服务的中间目标。
另外,该研究将当前对齐研究分解为两个关键组成部分:前向对齐和后向对齐。前者旨在通过对齐训练使 AI 系统对齐,而后者旨在获取有关系统对齐的证据,并适当地管理它们,从而避免加剧对齐不当的风险。前向对齐和后向对齐形成一个循环过程,其中通过前向过程的 AI 系统的对齐在后向过程中得到验证,同时为下一轮的前向对齐提供更新的目标。
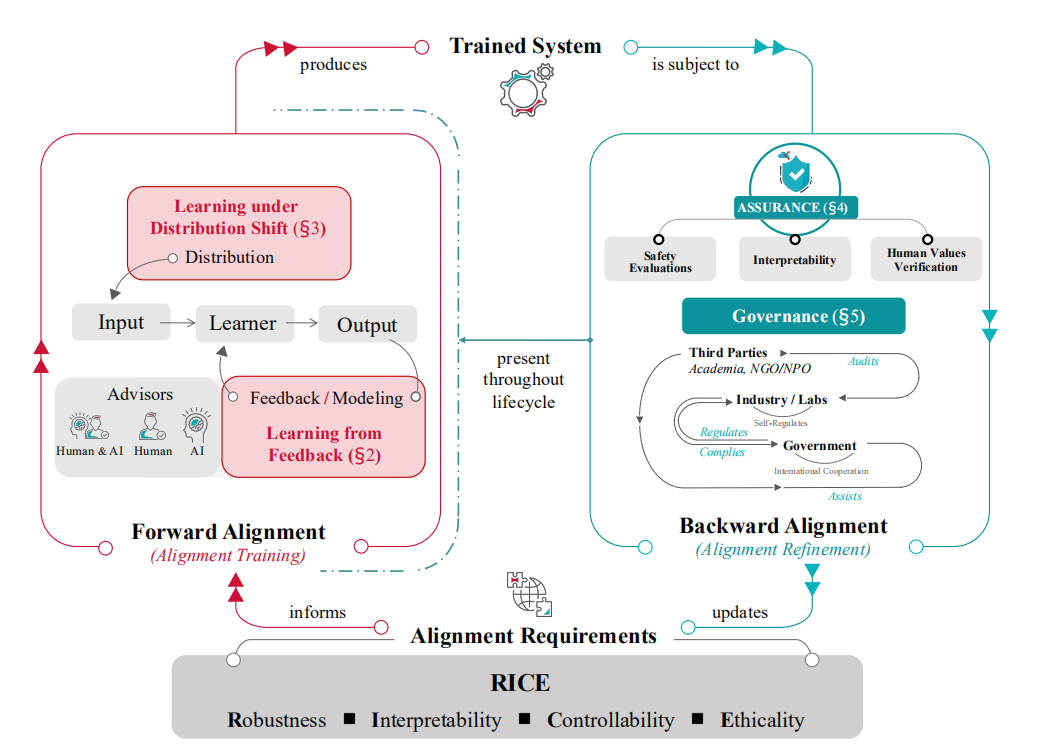
图|对齐循环
在前向对齐和后向对齐中,研究共讨论了四种 AI 对齐的方法和实践。
1.从反馈中学习(Learning from feedback)
从反馈中学习(Learning from feedback)涉及到一个问题,即在对齐训练期间,我们如何提供和使用反馈来影响已训练 AI 系统的行为?它假定了一个输入-行为对,并只关心如何在这个对上提供和使用反馈。
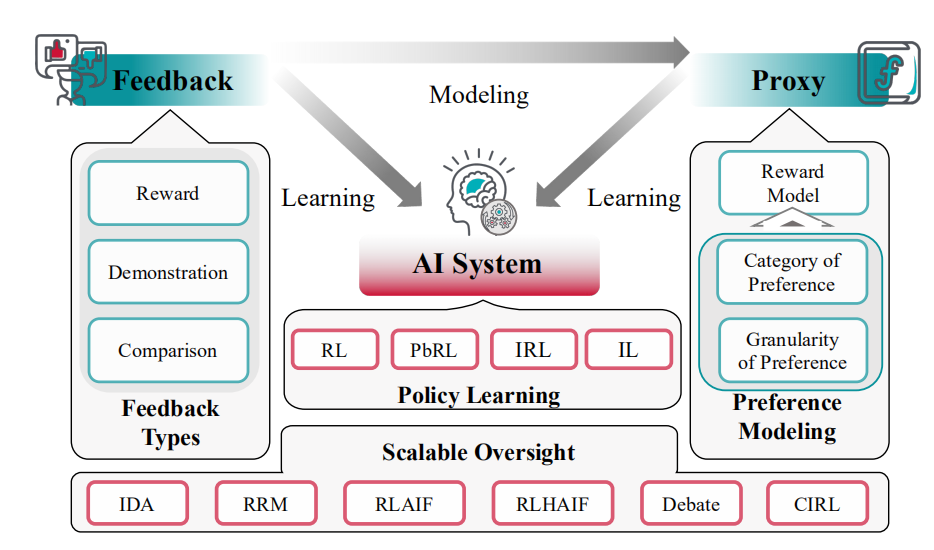
图|从反馈中学习过程的概览
在大型语言模型(LLMs)的背景下,一个典型的解决方案是基于人类反馈的强化学习(RLHF),其中人类评估者通过比较聊天模型的不同答案来提供反馈,然后使用强化学习根据已训练的奖励模型来利用这个反馈。
尽管 RLHF 很受欢迎,但它面临着许多挑战。一个重要的挑战是可扩展监督,即如何在人类评估者难以理解和评估 AI 系统行为的复杂情境中,为超越人类能力的 AI 系统提供高质量的反馈。另一个挑战是如何提供关于道德性的反馈,这个问题是通过机器伦理的方法来解决的。在伦理方面,不对齐也可能源于忽视价值观中的关键变化维度,比如在反馈数据中代表某些人口群体不足。还有一些工作结合反馈机制与社会选择方法,以产生更合理和公平的偏好汇总。
2.分布转移下的学习(Learning under Distribution Shift)
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

