

DeepMind指出「Transformer无法
原文来源:机器之心

图片来源:由无界 AI生成
GPT 变得好用了,但真的更聪明了吗?
昨天,很多人彻夜未眠 —— 全球科技圈都把目光聚焦在了美国旧金山。
短短 45 分钟时间里,OpenAI CEO 山姆・奥特曼向我们介绍了迄今为止最强的大模型,和基于它的一系列应用,一切似乎就像当初 ChatGPT 一样令人震撼。

OpenAI 在本周一的首个开发者日上推出了 GPT-4 Turbo,新的大模型更聪明,文本处理上限更高,价格也更便宜,应用商店也开了起来。现在,用户还可以根据需求构建自己的 GPT。
根据官方说法,这一波 GPT 的升级包括:
发布会一开完,人们蜂拥而入开始尝试。GPT4 Turbo 的体验果然不同凡响。首先是快,快到和以前所有大模型拉开了代差:

然后是功能增多,画画的时候,你一有灵感就可以直接说话让 AI 负责实现:

设计个 UI,几个小时的工作变成几分钟:
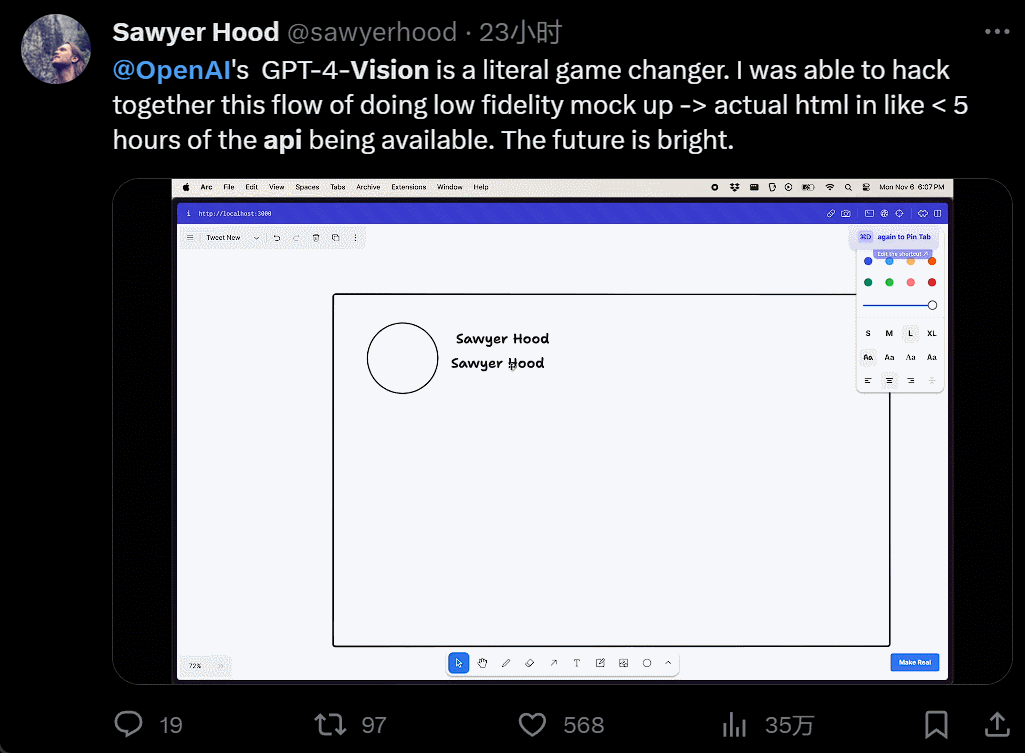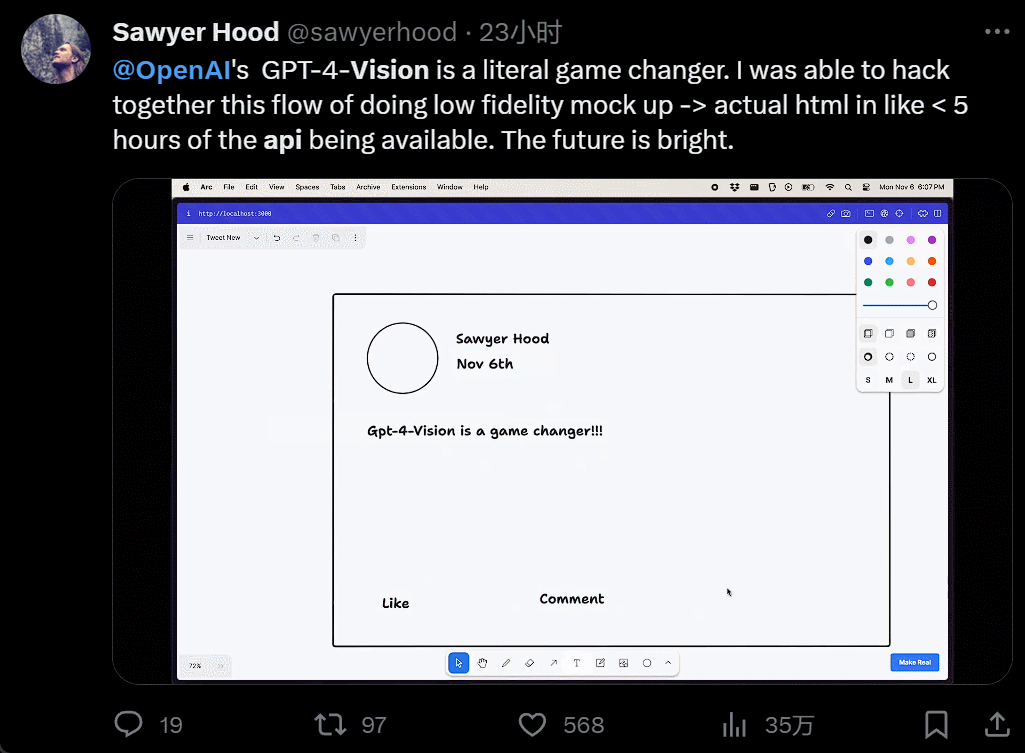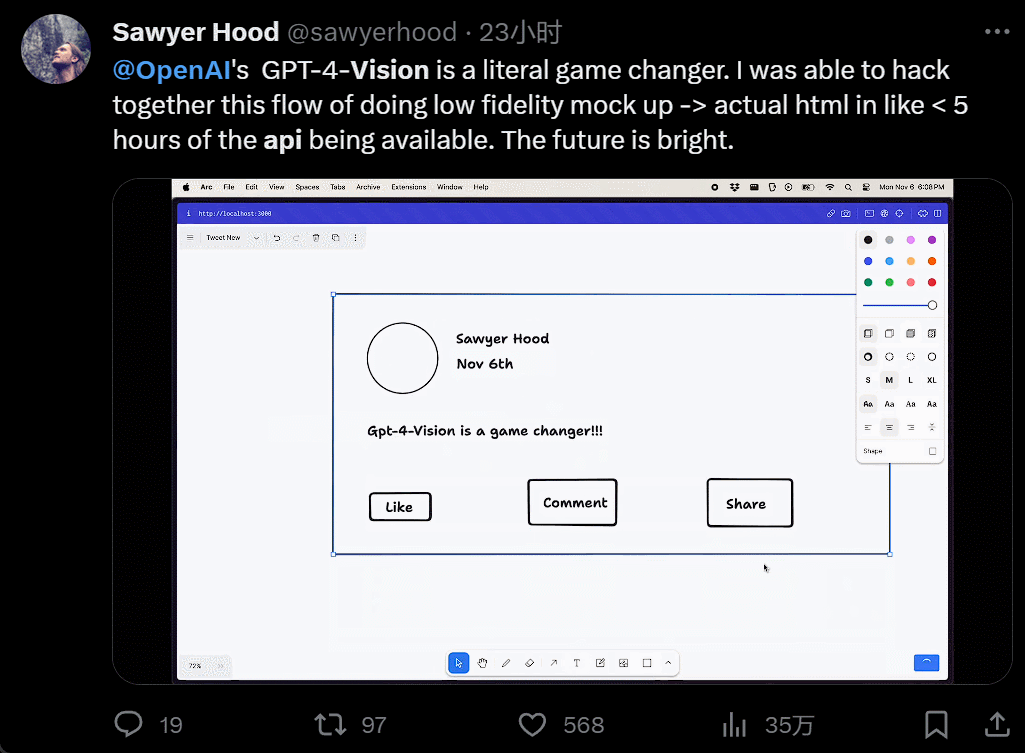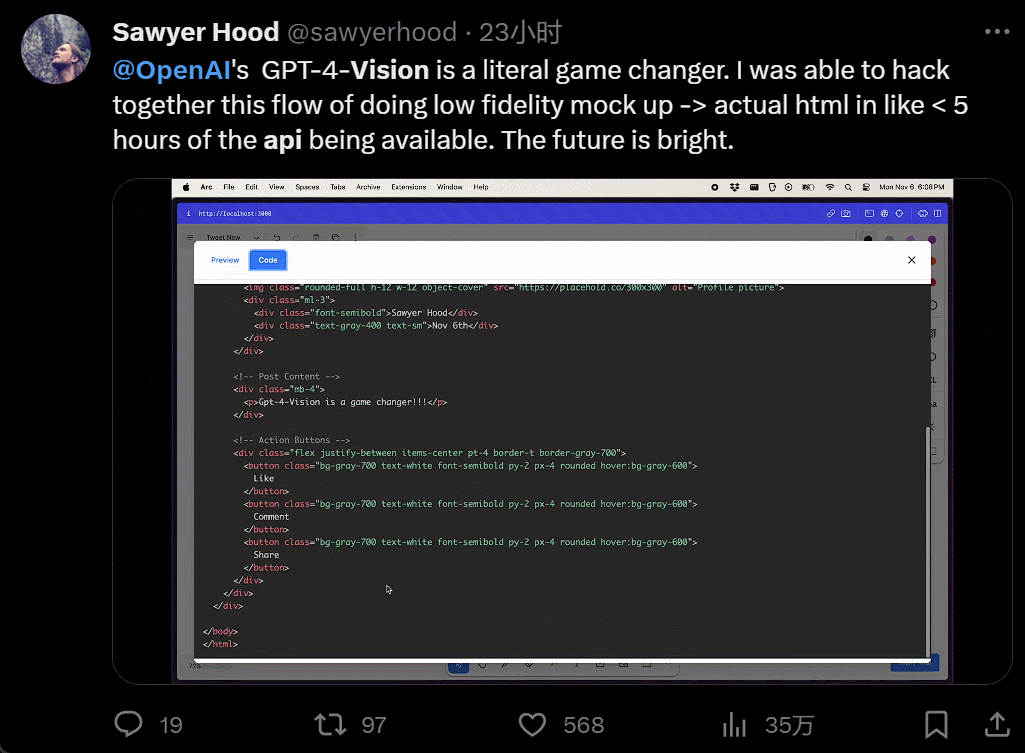
我直接不装了,截个图复制粘贴别人的网站,生成自己的,只用 40 秒:

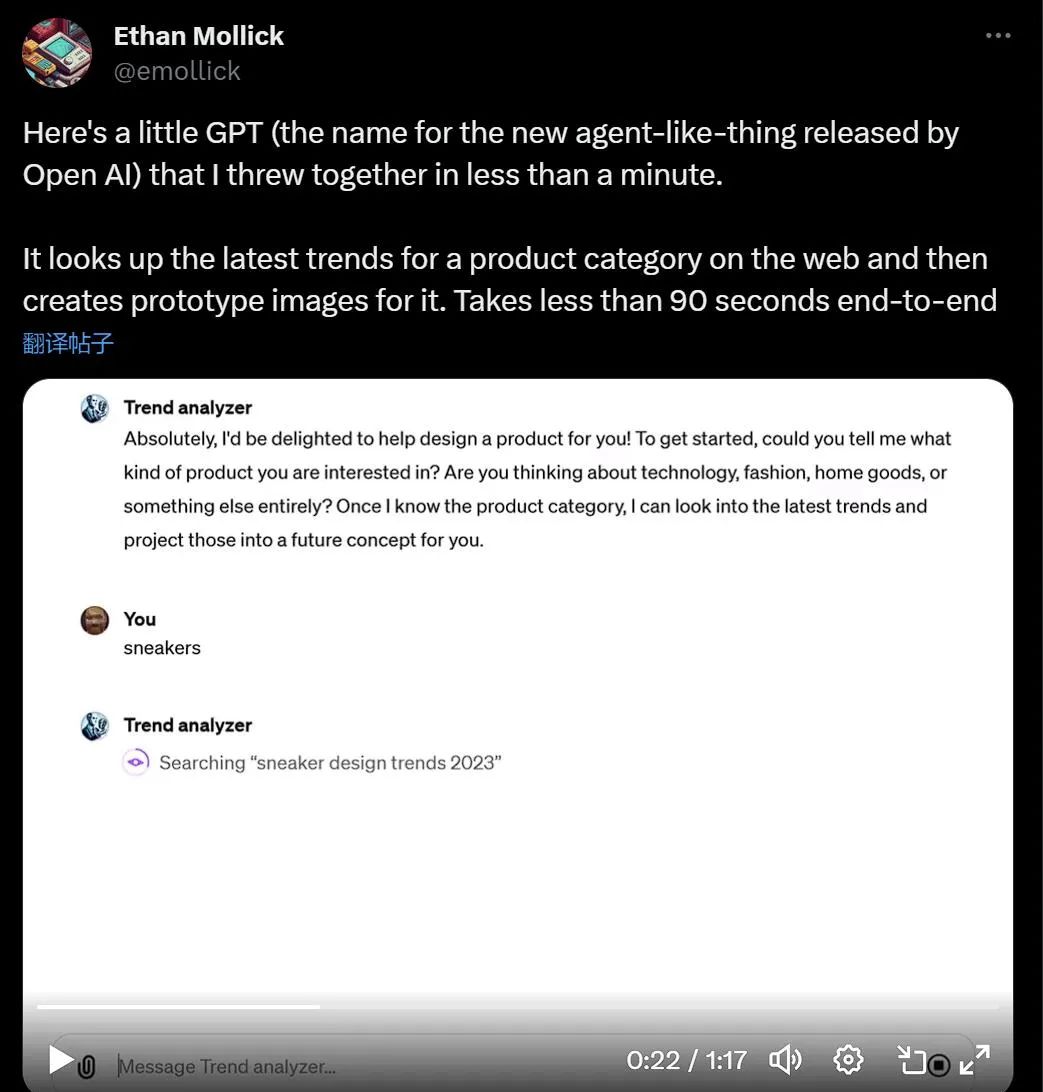
利用 ChatGPT 与 Bing 的浏览功能以及与 DALL-E 3 图像生成器的集成,沃顿商学院教授 Ethan Mollick 分享了一段视频,展示了他的名为「趋势分析器」的 GPT 工具,其可查找市场特定细分市场的趋势,然后创建新产品的原型图像。
Octane AI 首席执行官 Matt Schlicht 的 Simponize Me GPT 会自动应用提示来转换用户上传的个人资料照片,生成《辛普森一家》的风格,做这个小应用只用了不到十分钟。

GPT-4 Turbo 具有创纪录的准确率,在 PyLLM 基准上,GPT-4 Turbo 的准确率是 87%,而 GPT-4 的准确率是 52%,这是在速度几乎快了四倍多的情况下(每秒 48 token)实现的。
至此,生成式 AI 的竞争似乎进入了新的阶段。很多人认为,当竞争对手们依然在追求更快、能力更强的大模型时,OpenAI 其实早就已经把所有方向都试过了一遍,这一波更新会让一大批创业公司作古。

也有人表示,既然 Agent 是大模型重要的方向,OpenAI 也开出了 Agent 应用商店,接下来在智能体领域,我们会有很多机会。
竞争者们真的无路可走了吗?价格降低,速度变快以后,大模型的性能还能同时变得更好?这必须要看实践,在 OpenAI 的博客中,其实说法是这样的:在某些格式的输出下,GPT-4 Turbo 会比 GPT-4 结果更好。那么总体情况会如何?
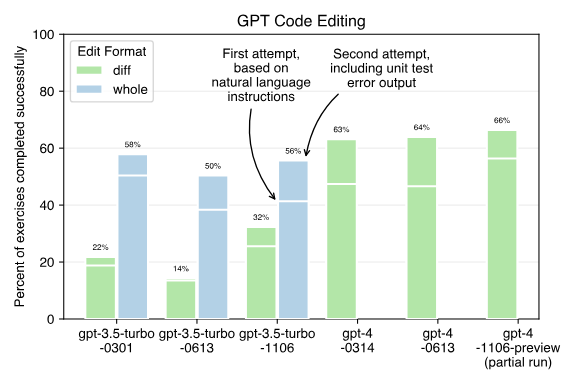
在新模型发布的 24 小时内,就有研究者在 Aider 上进行了 AI 生成代码的能力测试。
在 gpt-4-1106-preview 模型上,仅使用 diff 编辑方法对 GPT-4 模型进行基准测试得出的结论是:
接下来是使用 whole 和 diff 编辑格式对 GPT-3.5 模型进行的基准测试。结果表明,似乎没有一个 gpt-3.5 模型能够有效地使用 diff 编辑格式,包括最新的 11 月出现的新模型( 简称 1106)。下面是一些 whole 编辑格式结果:
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

