
:市场")
LD宏观周报(2023/06/19):市场
原文:新智元

图片来源:由无界 AI 生成
随着GPT-4、Stable Diffusion和Midjourney的爆火,越来越多的人开始在工作和生活中引入生成式AI技术。
甚至,有人已经开始尝试用AI生成的数据来训练AI了。难道,这就是传说中的「数据永动机」?
然而,来自牛津、剑桥、帝国理工等机构研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃(model collapse),造成不可逆的缺陷。

也就是,随着时间推移,模型就会忘记真实基础数据部分。即使在几乎理想的长期学习状态下,这个情况也无法避免。
因此研究人员呼吁,如果想要继续保持大规模数据带来的模型优越性,就必须认真对待人类自己写出来的文本。

论文地址:https://arxiv.org/abs/2305.17493v2
但现在的问题在于——你以为的「人类数据」,可能并不是「人类」写的。
洛桑联邦理工学院(EPFL)的最新研究称,预估33%-46%的人类数据都是由AI生成的。

毫无疑问,现在的大语言模型已经进化出了相当强大的能力,比如GPT-4可以在某些场景下生成与人类别无二致的文本。
但这背后的一个重要原因是,它们的训练数据大部分来源于过去几十年人类在互联网上的交流。
如果未来的语言模型仍然依赖于从网络上爬取数据的话,就不可避免地要在训练集中引入自己生成的文本。
对此,研究人员预测,等GPT发展到第n代的时候,模型将会出现严重的崩溃问题。
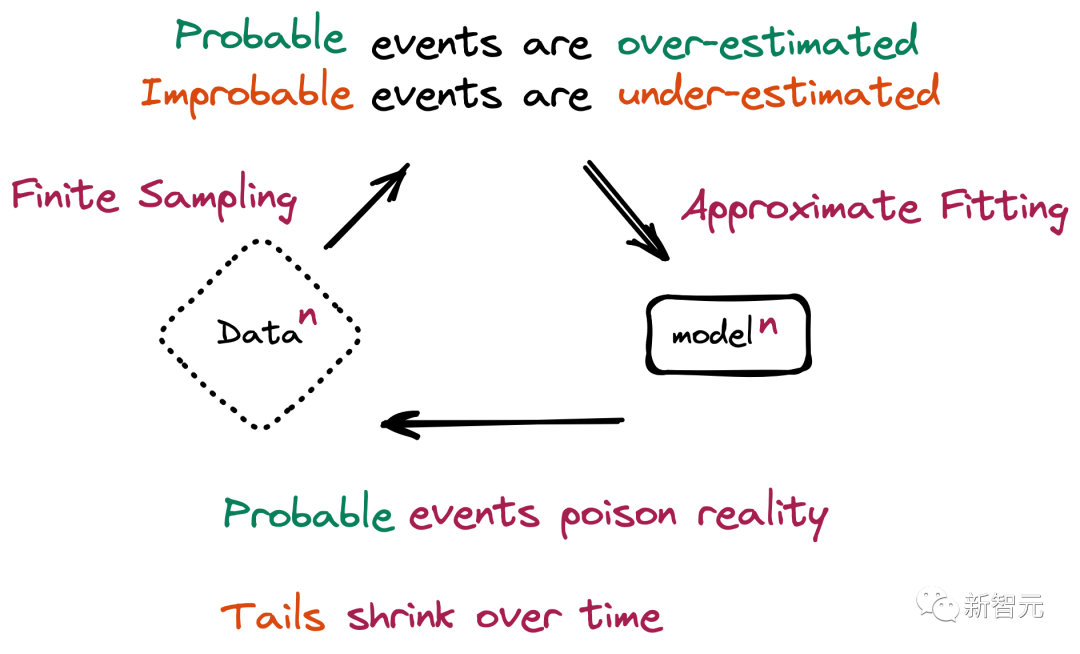
那么,在这种不可避免会抓取到LLM生成内容的情况下,为模型的训练准备由人类生产的真实数据,就变得尤为重要了。
大名鼎鼎的亚马逊数据众包平台Mechanical Turk(MTurk)从2005年启动时就已经成为许多人的副业选择。
科研人员可以发布各种琐碎的人类智能任务,比如给图像标注、调查等,应有尽有。
而这些任务通常是计算机和算法无法处理的,甚至,MTurk成为一些预算不够的科研人员和公司的「最佳选择」。
就连贝佐斯还将MTurk的众包工人戏称为「人工人工智能」。

除了MTurk,包括Prolific在内的众包平台已经成为研究人员和行业实践者的核心,能够提供创建、标注和总结各种数据的方法,以便进行调查和实验。
然而,来自EPFL的研究发现,在这个人类数据的关键来源上,有近乎一半的数据都是标注员用AI创建的。

论文地址:https://arxiv.org/abs/2306.07899v1
而最开始提到的「模型崩溃」,就是在给模型投喂了太多来自AI的数据之后,带来的能够影响多代的退化。
也就是,新一代模型的训练数据会被上一代模型的生成数据所污染,从而对现实世界的感知产生错误的理解。
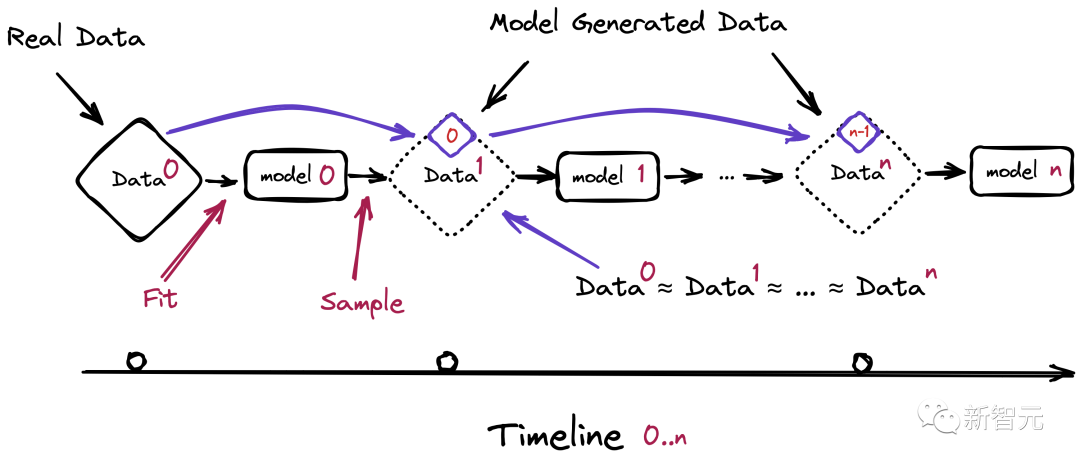
更进一步,这种崩溃还会引发比如基于性别、种族或其他敏感属性的歧视问题,尤其是如果生成AI随着时间的推移学会在其响应中只生成某个种族,而「忘记」其他种族的存在。
而且,除了大语言模型,模型崩溃还会出现在变分自编码器(VAE)、高斯混合模型上。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

