

「胖应用链」理论:应用
原文来源:机器之心

图片来源:由无界 AI生成
低精度训练是大模型训练中扩展模型大小,节约训练成本的最关键技术之一。相比于当前的 16 位和 32 位浮点混合精度训练,使用 FP8 8 位浮点混合精度训练能带来 2 倍的速度提升,节省 50% - 75% 的显存和 50% - 75% 的通信成本,而且英伟达最新一代卡皇 H100 自带良好的 FP8 硬件支持。但目前业界大模型训练框架对 FP8 训练的支持还非常有限。最近,微软提出了一种用于训练 LLM 的 FP8 混合精度框架 FP8-LM,将 FP8 尽可能应用在大模型训练的计算、存储和通信中,使用 H100 训练 GPT-175B 的速度比 BF16 快 64%,节省 42% 的内存占用。更重要的是:它开源了。
大型语言模型(LLM)具有前所未有的语言理解和生成能力,但是解锁这些高级的能力需要巨大的模型规模和训练计算量。在这种背景下,尤其是当我们关注扩展至 OpenAI 提出的超级智能 (Super Intelligence) 模型规模时,低精度训练是其中最有效且最关键的技术之一,其优势包括内存占用小、训练速度快,通信开销低。目前大多数训练框架(如 Megatron-LM、MetaSeq 和 Colossal-AI)训练 LLM 默认使用 FP32 全精度或者 FP16/BF16 混合精度。
但这仍然没有推至极限:随着英伟达 H100 GPU 的发布,FP8 正在成为下一代低精度表征的数据类型。理论上,相比于当前的 FP16/BF16 浮点混合精度训练,FP8 能带来 2 倍的速度提升,节省 50% - 75% 的内存成本和 50% - 75% 的通信成本。
尽管如此,目前对 FP8 训练的支持还很有限。英伟达的 Transformer Engine (TE),只将 FP8 用于 GEMM 计算,其所带来的端到端加速、内存和通信成本节省优势就非常有限了。
但现在微软开源的 FP8-LM FP8 混合精度框架极大地解决了这个问题:FP8-LM 框架经过高度优化,在训练前向和后向传递中全程使用 FP8 格式,极大降低了系统的计算,显存和通信开销。

实验结果表明,在 H100 GPU 平台上训练 GPT-175B 模型时, FP8-LM 混合精度训练框架不仅减少了 42% 的实际内存占用,而且运行速度比广泛采用的 BF16 框架(即 Megatron-LM)快 64%,比 Nvidia Transformer Engine 快 17%。而且在预训练和多个下游任务上,使用 FP8-LM 训练框架可以得到目前标准的 BF16 混合精度框架相似结果的模型。
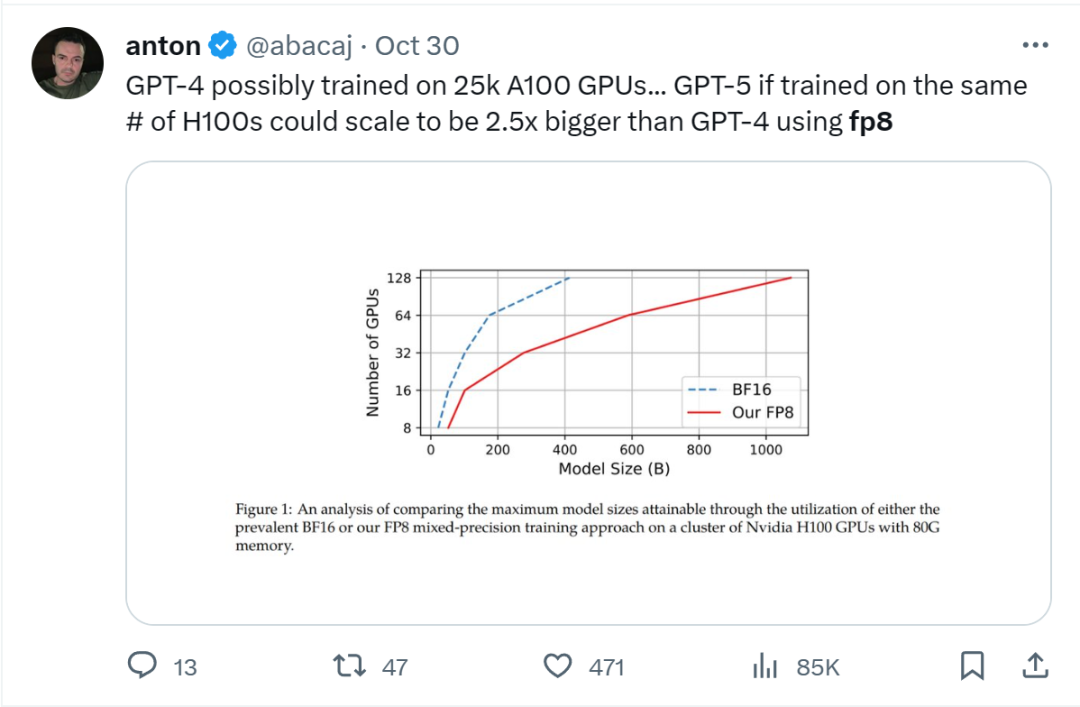
在给定计算资源情况下,使用 FP8-LM 框架能够无痛提升可训练的模型大小多达 2.5 倍。有研发人员在推特上热议:如果 GPT-5 使用 FP8 训练,即使只使用同样数量的 H100,模型大小也将会是 GPT-4 的 2.5 倍!
Huggingface 研发工程师调侃:「太酷啦,通过 FP8 大规模训练技术,可以实现计算欺骗!」
FP8-LM 主要贡献:
FP8-LM 实现
具体来说,对于使用 FP8 来简化混合精度和分布式训练的目标,他们设计了三个优化层级。这三个层级能以一种渐进方式来逐渐整合 8 位的集体通信优化器和分布式并行训练。优化层级越高,就说明 LLM 训练中使用的 FP8 就越多。
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

